mit 6.824 lec1
2022.5.14
1.1分布式系统的驱动力与挑战
- 人们使用大量相互协作的计算机驱动力是:
- 人们需要更高的计算性能,(大量的计算机意味着)大量的并行计算,大量CPU,大量内存,以及大量磁盘在并行运行
- 另一个构建分布式系统的原因是,他可以提供容错。两台计算机,一台发生错误,另一台就可以执行
- 有些问题是天然分布式的,比如银行转账
- 构建分布式系统还可以达成一些安全的目标。比如有些代码不被信任,但是你要与它交互,这些代码不会立即表现的恶意或者出现bug。你不会想要信任这些代码,所以你或许想要将代码分散多处运行,这样你的代码在另一台计算机上运行,我们可以通过一些特定的网络协议通信。所以,我们可能会担心安全问题,我们把系统分成多个的计算机,这样可以限制出错域
- 6.824主要讨论性能和容错,后两部分通过学习案例研究
- 分布式系统的挑战:
- 因为分布式系统存在很多部分,这些部分又在并发执行,你会遇到并发编程和各种复杂交互所带来的问题,以及时间依赖的问题(比如同步,异步)
- 分布式系统有很多个部分,再加上计算机网络,你会遇到一些意想不到的故障。如果只有一台计算机,那么它通常要么是工作,要么故障没电,网络也可能故障,局部错误是分布式系统的难点
- 人们设计分布式系统是为了获得更高的性能,比如一千台计算机或一千个磁盘臂达到的性能。但是实际上一千台机器到底有多少性能是一个棘手的问题
1.3分布式系统的抽象和实现工具
- 824主要是介绍基础架构,基础架构包括存储,通信(网络)和计算,主要是存储
![]()
- 对于存储和计算,我们的目标是设计一些简单的接口,让第三方应用能够使用这些分布式的存储与计算,这样才能简单的再这些基础架构之上,构建第三方应用程序。也就说通过抽象的接口,将分布式特性隐藏在整个系统之中。我们希望设计一个接口,它看起来就像一个非分布式存储和计算系统一样,但是其内部是一个高性能高容错的分布式系统。但这样的抽象很难。
- 在构建分布式系统的时候,使用了很多工具:
- RPC。RPC的目标就是掩盖我们在不可靠的网络上通信的事实。
- 线程技术,利用多核心计算机。线程提供了一种结构化的并发操作方式,这样,从程序员的视角来说就可以简化并发操作。
- 🔒。线程往往需要🔒 来实现并发控制。

1.4 可扩展性(Scalability)
- 可扩展性是指,如果用一台计算机解决了一些问题,当我买第二台的时候,我只需要一半的时间就可以解决这些问题,两台计算机如果有两倍性能或者吞吐。构建分布式系统的一大目的就是实现可扩展性。
- 扩展性是很难实现的。当我们希望通过增加机器的方式实现扩展,这是很难实现的,需要一些架构设计来将这个可扩展性无限推进下去。
1.5 可用性(Availability)
- 由于分布式系统一般涉及大量计算机,以及运行在庞大的网络之上,那么存在极大的故障风险,很罕见的问题也会被放大。但是分布式系统需要构建一种基础架构,使它能够尽可能的对于开发人员屏蔽和掩盖错误。
- 可用性是用来描述容错的一个概念。可用系统是指,在特定的故障范围内,系统仍然能够提供服务。
- 可恢复性(recoverability)是另一个用来描述容错的特性。这是一个比可用性更弱的需求,因为在出现故障到故障组件被修复期间,系统将会完全停止工作,但是修复之后,系统又可以重新运行。
- 为了实现可用性与可用性,有两个重要的工具:
- 一个是非易失性存储。在磁盘,闪存,SSD之类的存储checkpoint或者系统状态的log。不过更新非易失存储代价很高,所以出现了很多管理非易失去存储的工具,同时构建高性能的,容错系统,需要避免频繁的写入非易失去存储的操作
- 第二是复制。不过管理复制副本需要处理一致性问题
1.6 一致性(Consistency)
- 一致性包括弱一致性与强一致性。对于一个分布式kv存储系统,get请求可以得到最近一次完成的put请求写入的值,这就是强一致性。而弱一致性是指不保证get请求可以得到最近的一次完成的put请求写入的值,弱一致性也很有用。
- 强一致性代价很高,需要大量的通信,为了避免大量的通信,人们会构建弱一致性系统,允许读取旧的数据,当然,为了使弱一致性更有意义,人们还会定义很多规则
- 如果将两个副本放在同一个机房的一个机架上,会因为有谁踢到了机架的电源线,数据的两个副本都没了。为了更好的容错,人们希望将不同的副本放置在尽可能远的位置,所以为了在多个副本之间更新一个数据,也需要花费几毫秒到几十毫秒,代价很高
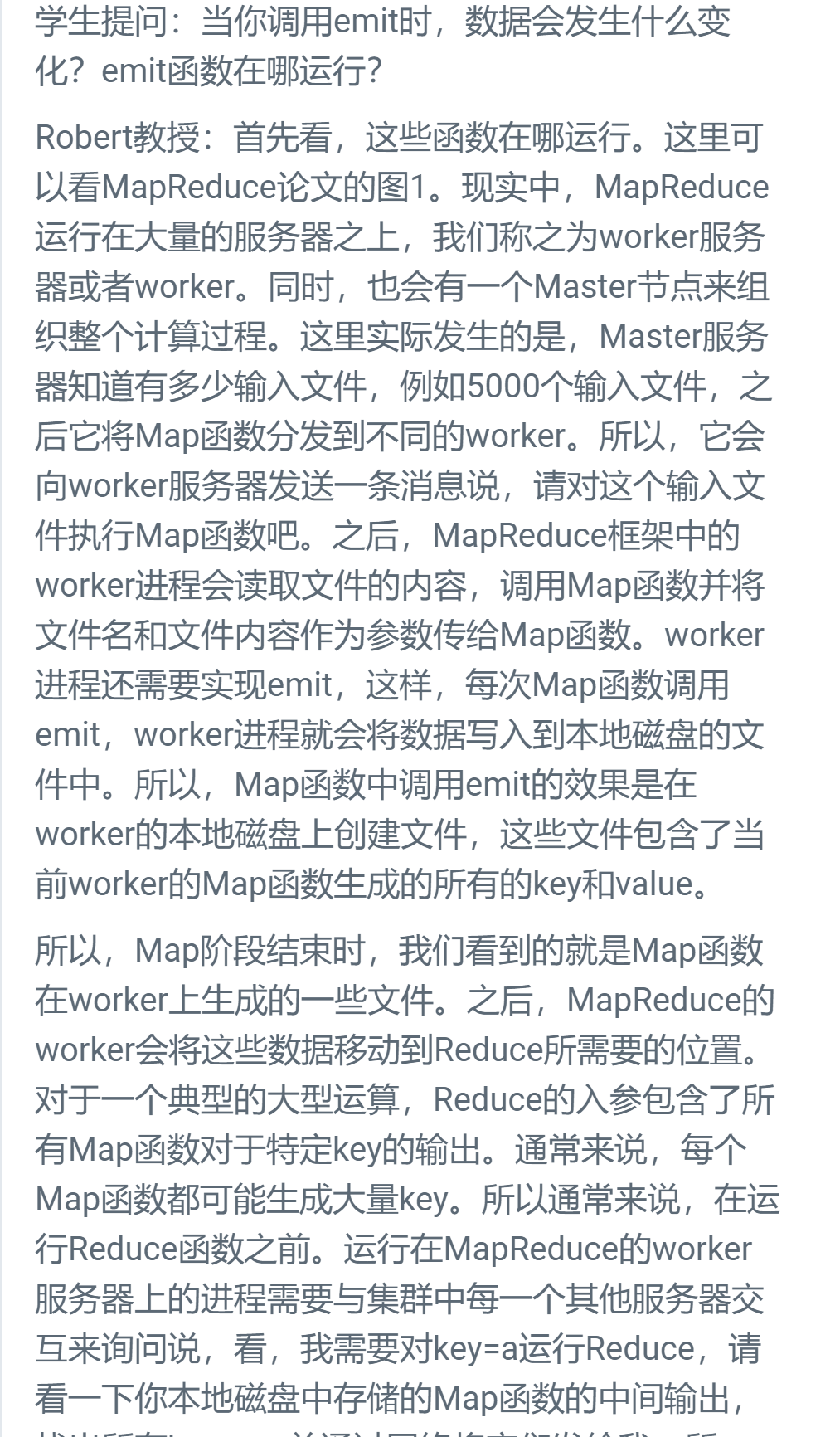
1.7 MapReduce基本工作方式
- MapReduce:
- Job。整个MapReduce计算成为Job
- Task。每一次MapReduce调用成为Task。
- 所以对于一个完整的MapReduce Job,它由一些Map Task和一些Reduce Task组成。
1.8 Map函数和Reduce函数
- MapReduce的大致运行方式
![]()
![]()
![]()
- MapReduce的map task的输入是从何而来?
![]() 将GFS和MapReduce混合运行在一组服务器上,就可以减少网络传输
将GFS和MapReduce混合运行在一组服务器上,就可以减少网络传输![]() shuffle是什么意思?数据在Map Task的机器上按照行存储,最终在Reduce Task的机器上按照列存储,这个过程称为shuffle
shuffle是什么意思?数据在Map Task的机器上按照行存储,最终在Reduce Task的机器上按照列存储,这个过程称为shuffle![]() 用Streaming
用Streaming![]() 现在交换机快多了,所以网络通信不是限制MapReduce的瓶颈了,现在会有很多root交换机而不是一个交换机(spine-leaf架构)
现在交换机快多了,所以网络通信不是限制MapReduce的瓶颈了,现在会有很多root交换机而不是一个交换机(spine-leaf架构)![]()
![]()


 将GFS和MapReduce混合运行在一组服务器上,就可以减少网络传输
将GFS和MapReduce混合运行在一组服务器上,就可以减少网络传输 shuffle是什么意思?数据在Map Task的机器上按照行存储,最终在Reduce Task的机器上按照列存储,这个过程称为shuffle
shuffle是什么意思?数据在Map Task的机器上按照行存储,最终在Reduce Task的机器上按照列存储,这个过程称为shuffle 用Streaming
用Streaming 现在交换机快多了,所以网络通信不是限制MapReduce的瓶颈了,现在会有很多root交换机而不是一个交换机(spine-leaf架构)
现在交换机快多了,所以网络通信不是限制MapReduce的瓶颈了,现在会有很多root交换机而不是一个交换机(spine-leaf架构)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号