MapReduce
介绍
基本编程模型
实现(MapReduce执行流程,容错方案...)
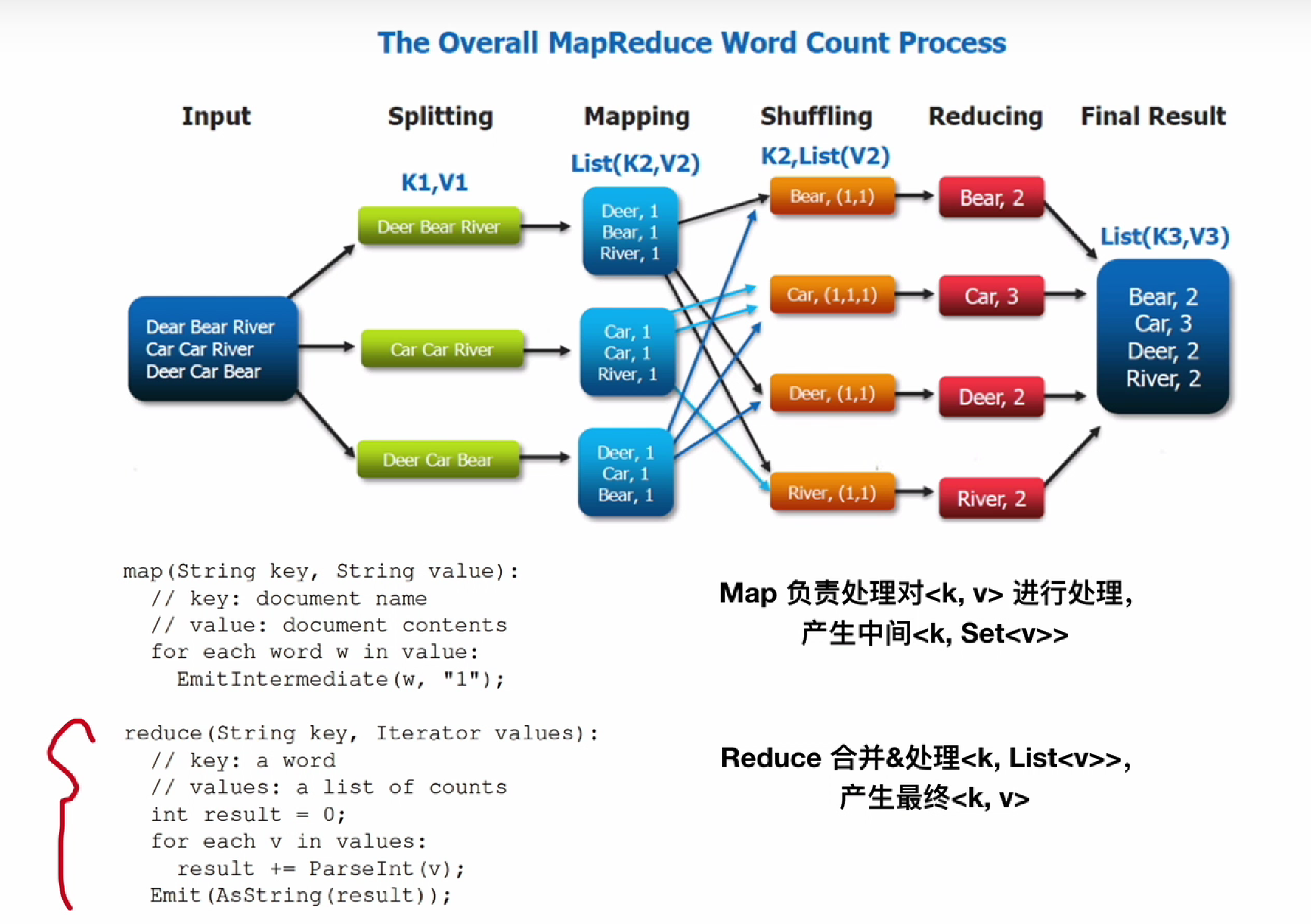
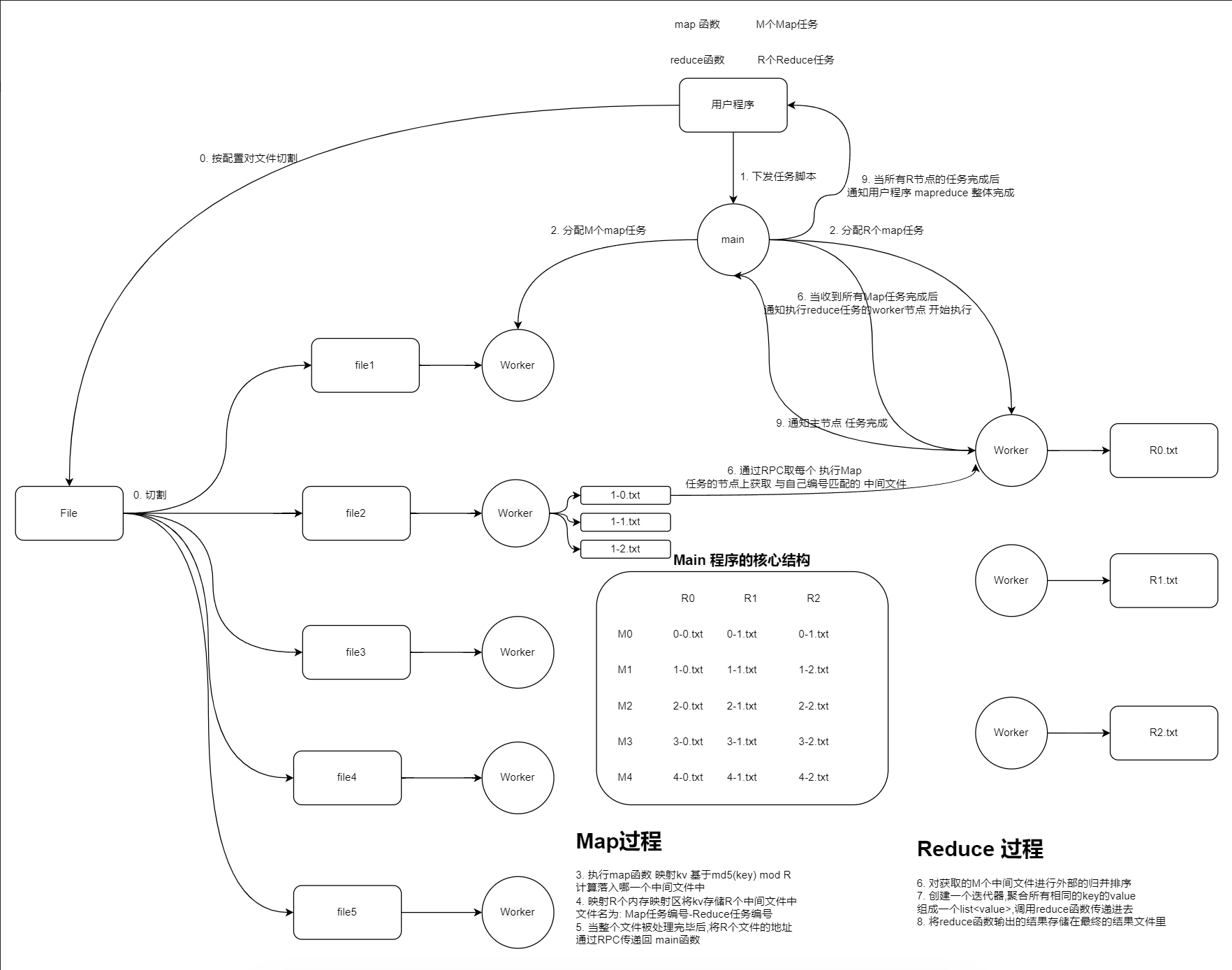
MapReduce执行流程
-
大致的执行流程分为7步
![]()
-
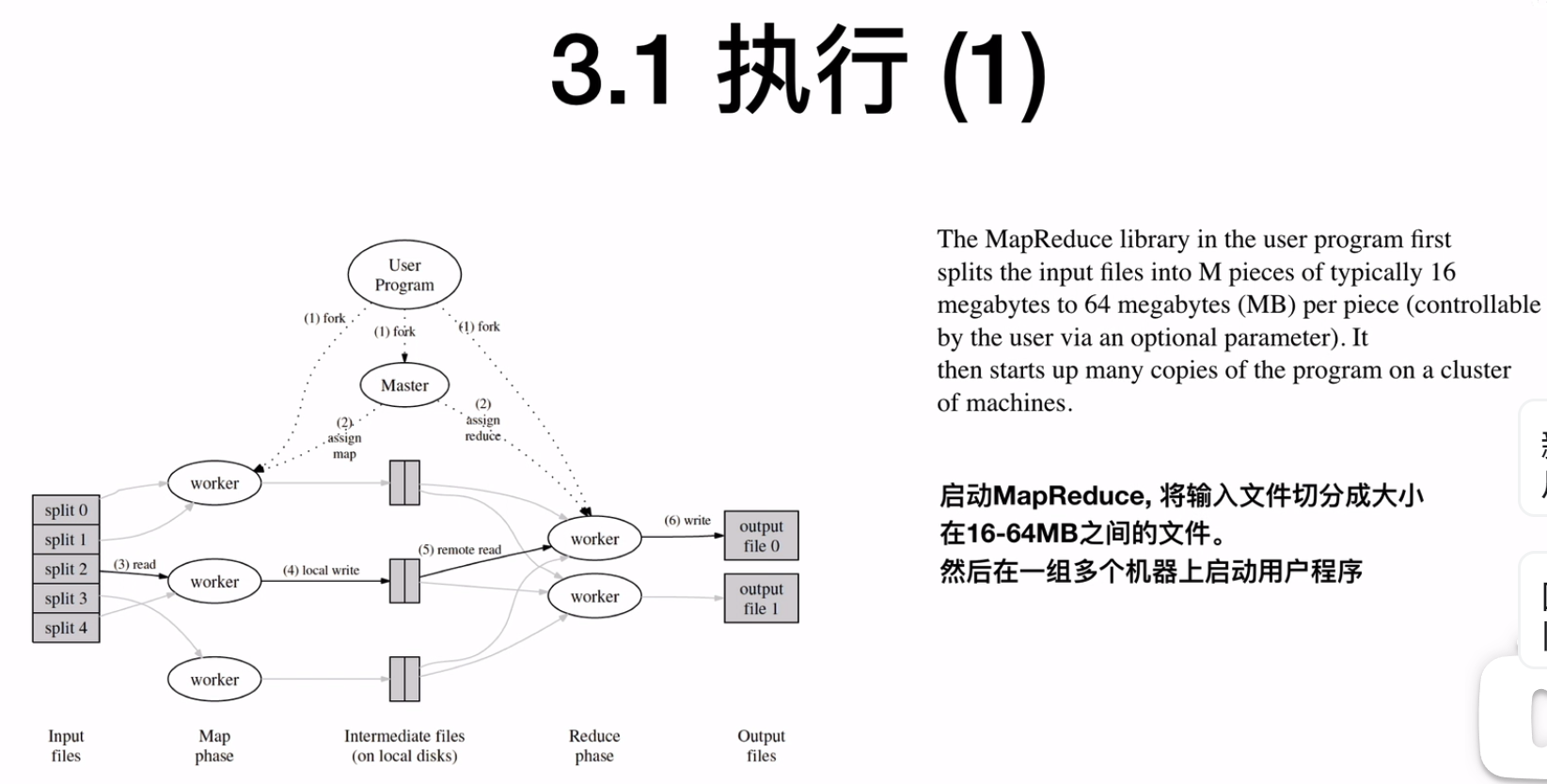
将输入文件切分为大小在16-64MB的文件,然后在一组多个机器上启动用户程序,每个机器是一个worker
![]()
-
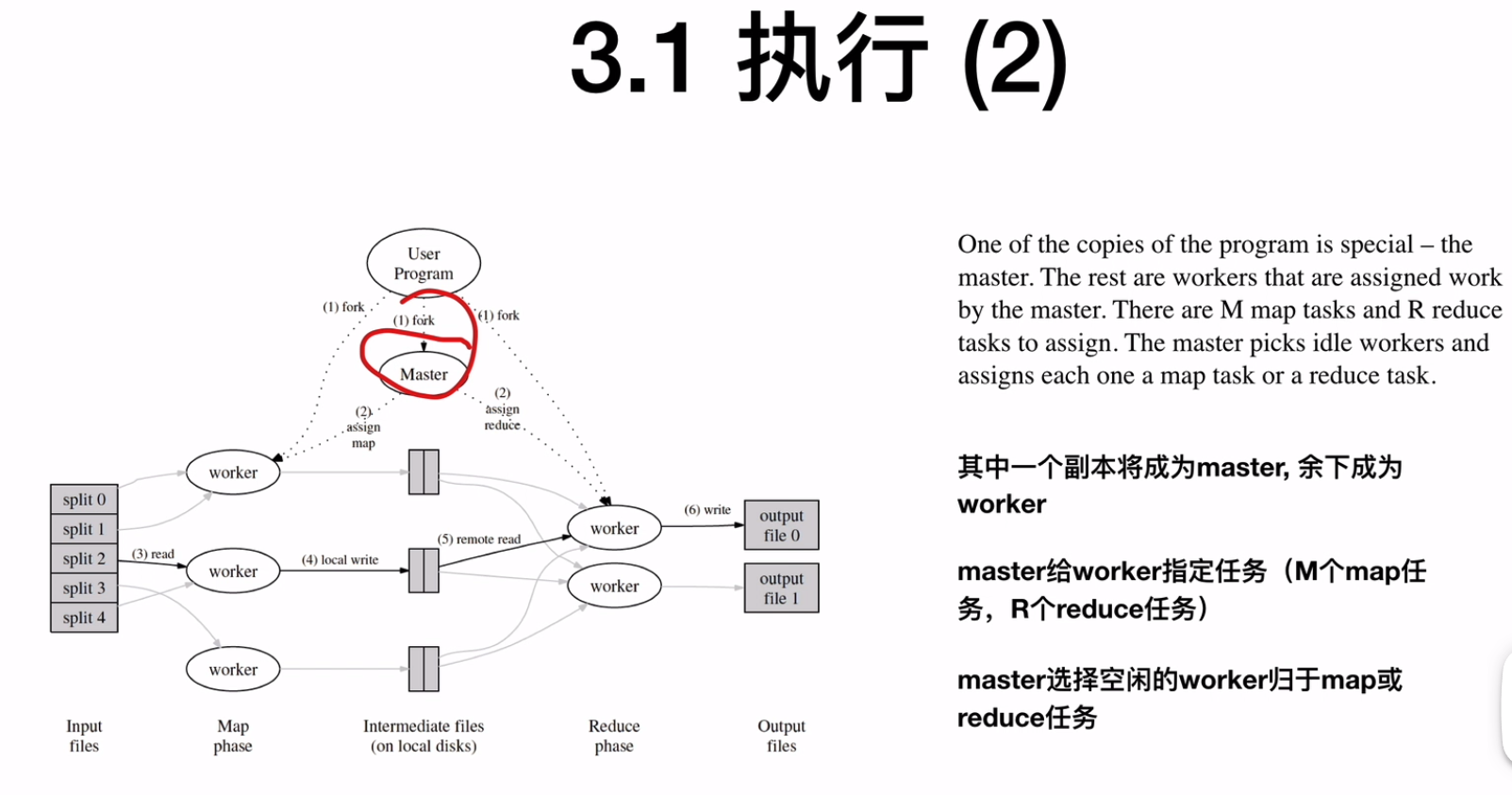
其中一个worker会成为master,master给worker指定任务(M个map任务,R个reduce任务),master会给idle的worker map或reduce的任务
![]()
-
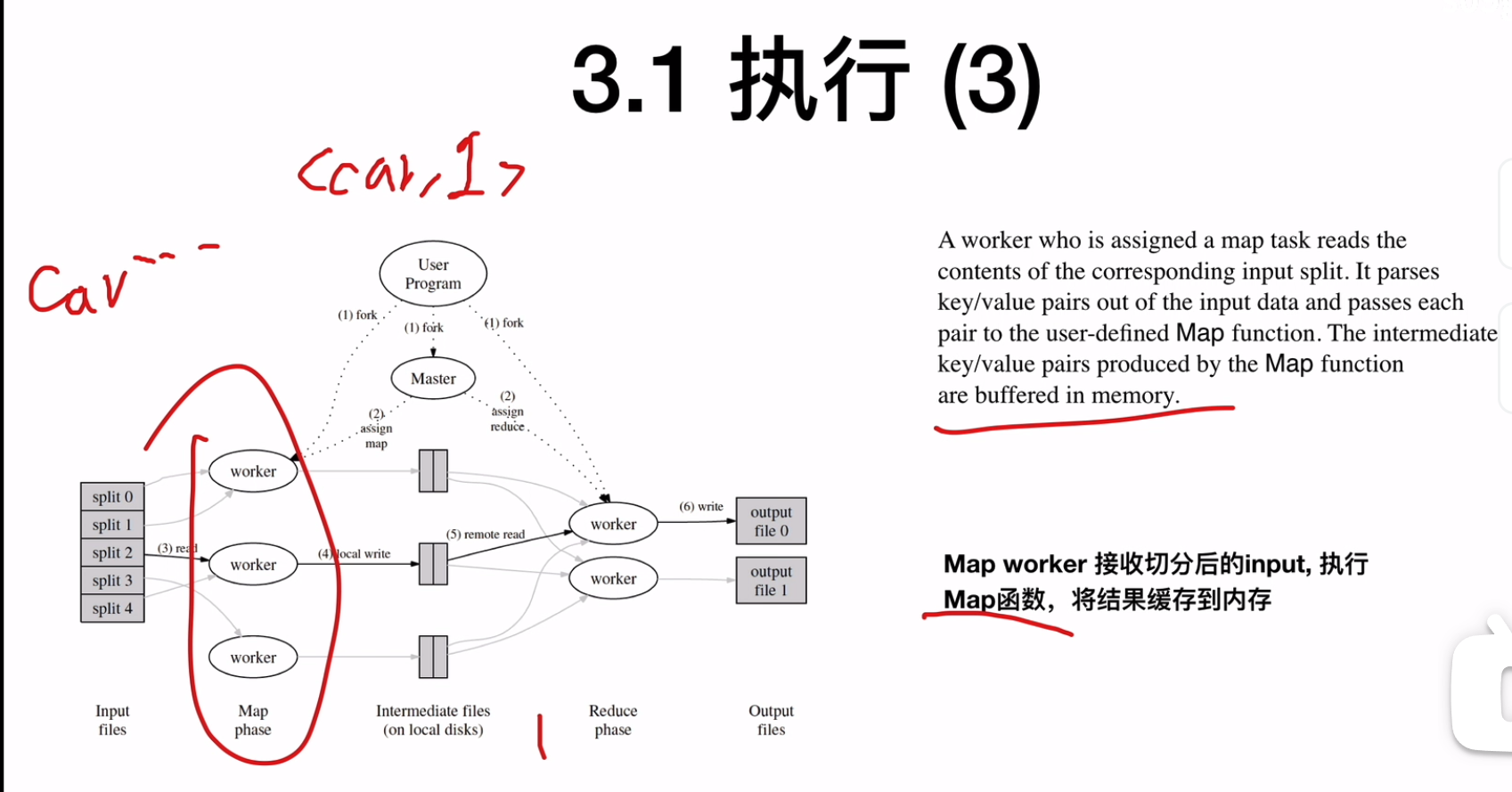
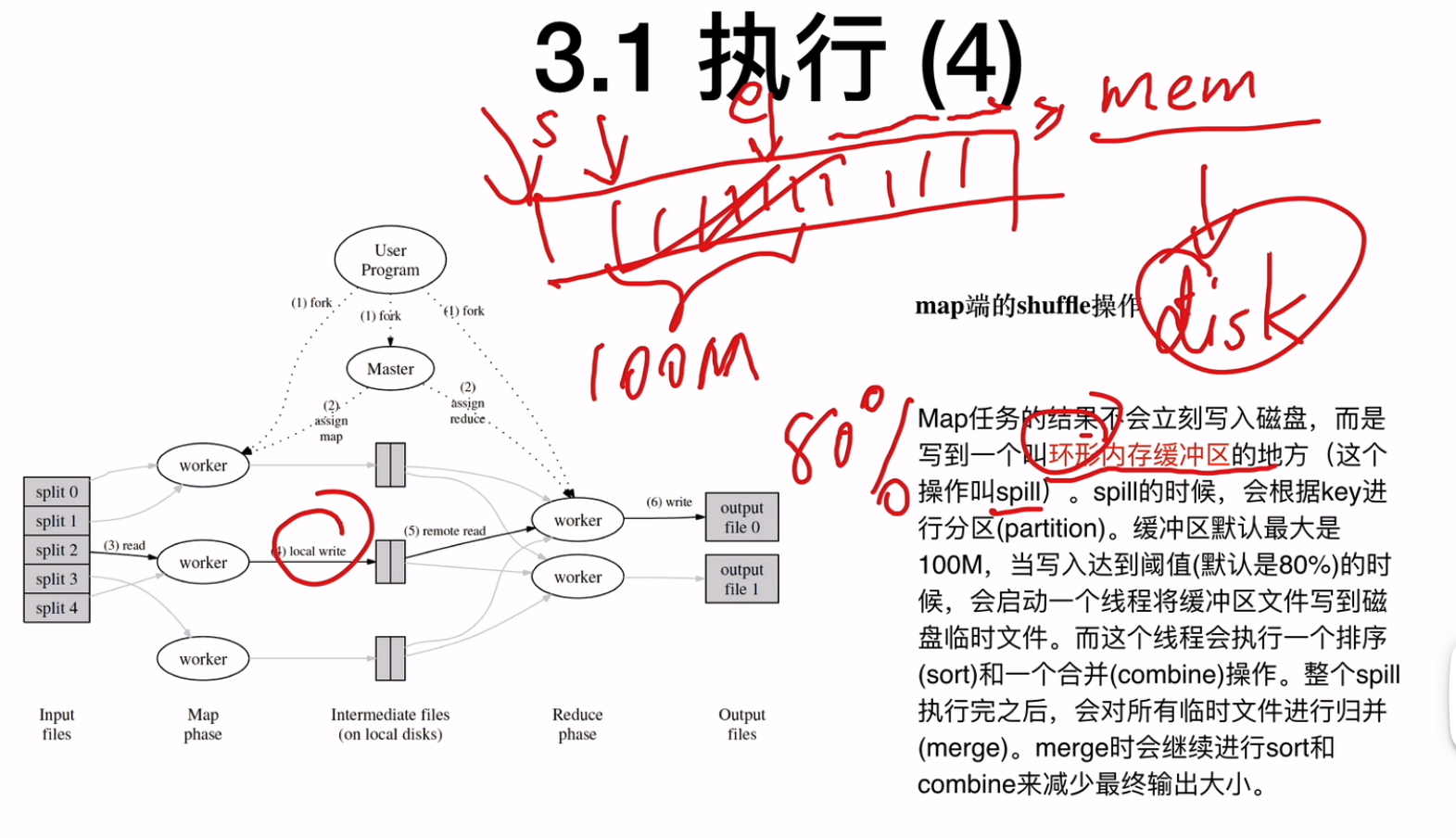
执行map的worker会接收切分后的input,执行map函数,其中map函数会映射kv,基于md5(key) mod R计算落入哪一个中间文件中(这样一来,一样的k的kv就会被放置到一样reduce worker中),映射R个内存映射区将kv存储R个中间文件名为 Map任务编号Reduce任务编号将结果缓存到机器的内存中
![]()
-
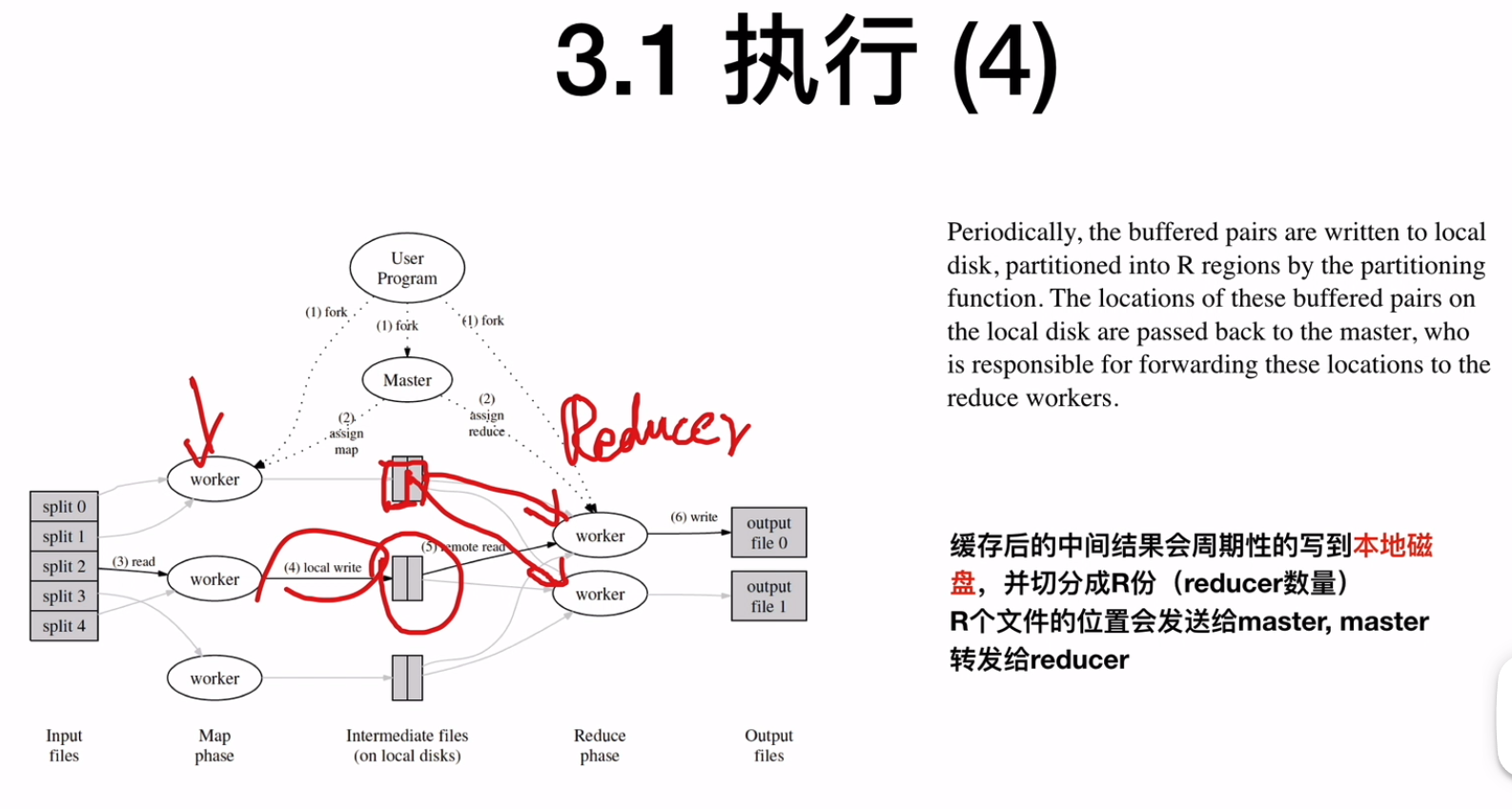
内存中的中间结果会周期性的写到本地磁盘中,并切分成R份(reducer的数量),这R个文件的位置会发送给master,master转发给reducer
![]()
![]()
-
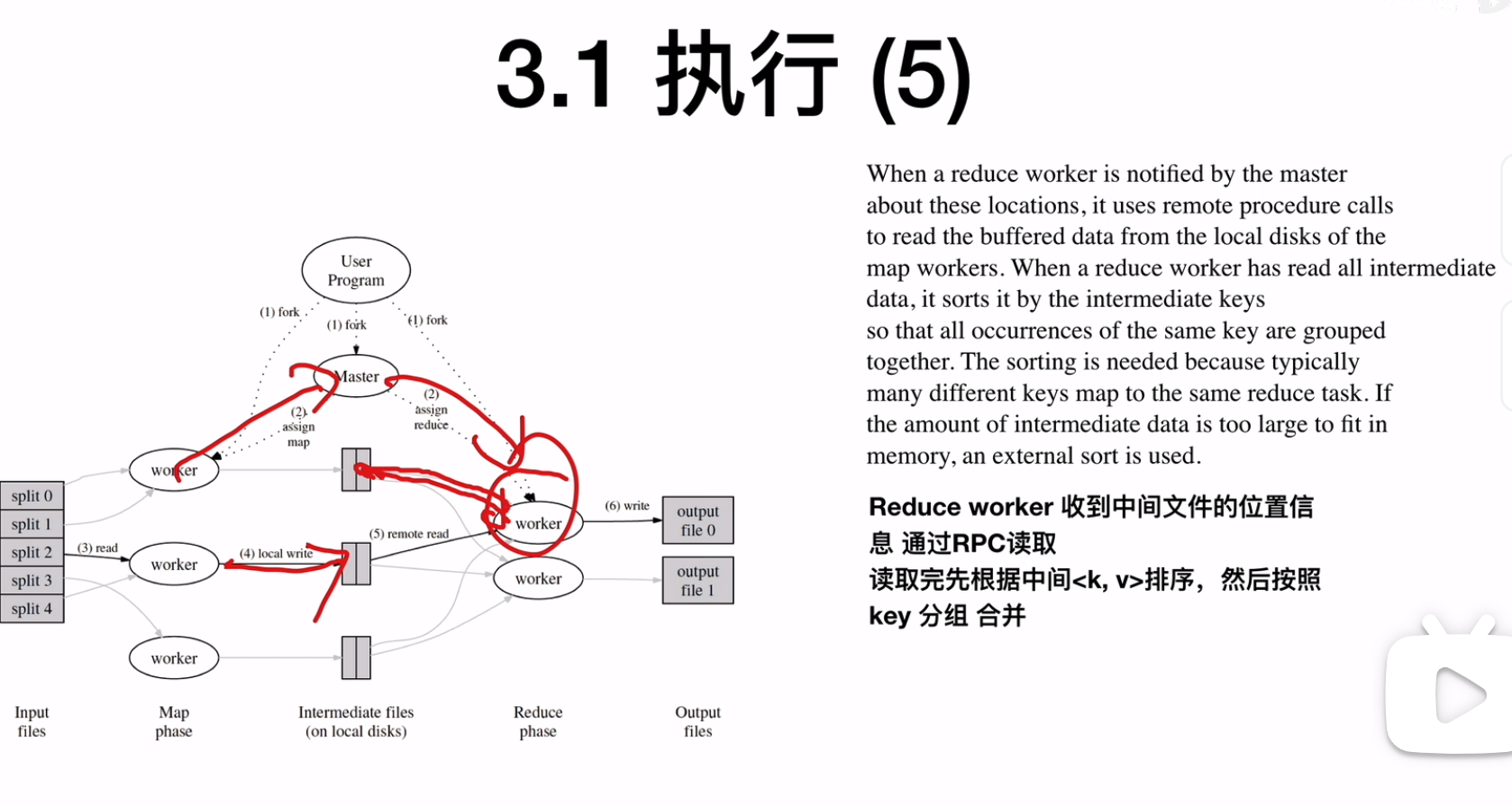
reduce worker收到中间文件的位置信息会通过RPC读取,读取到之后根据intemediate<k, v>排序,然后按照key分组合并
![]()
-
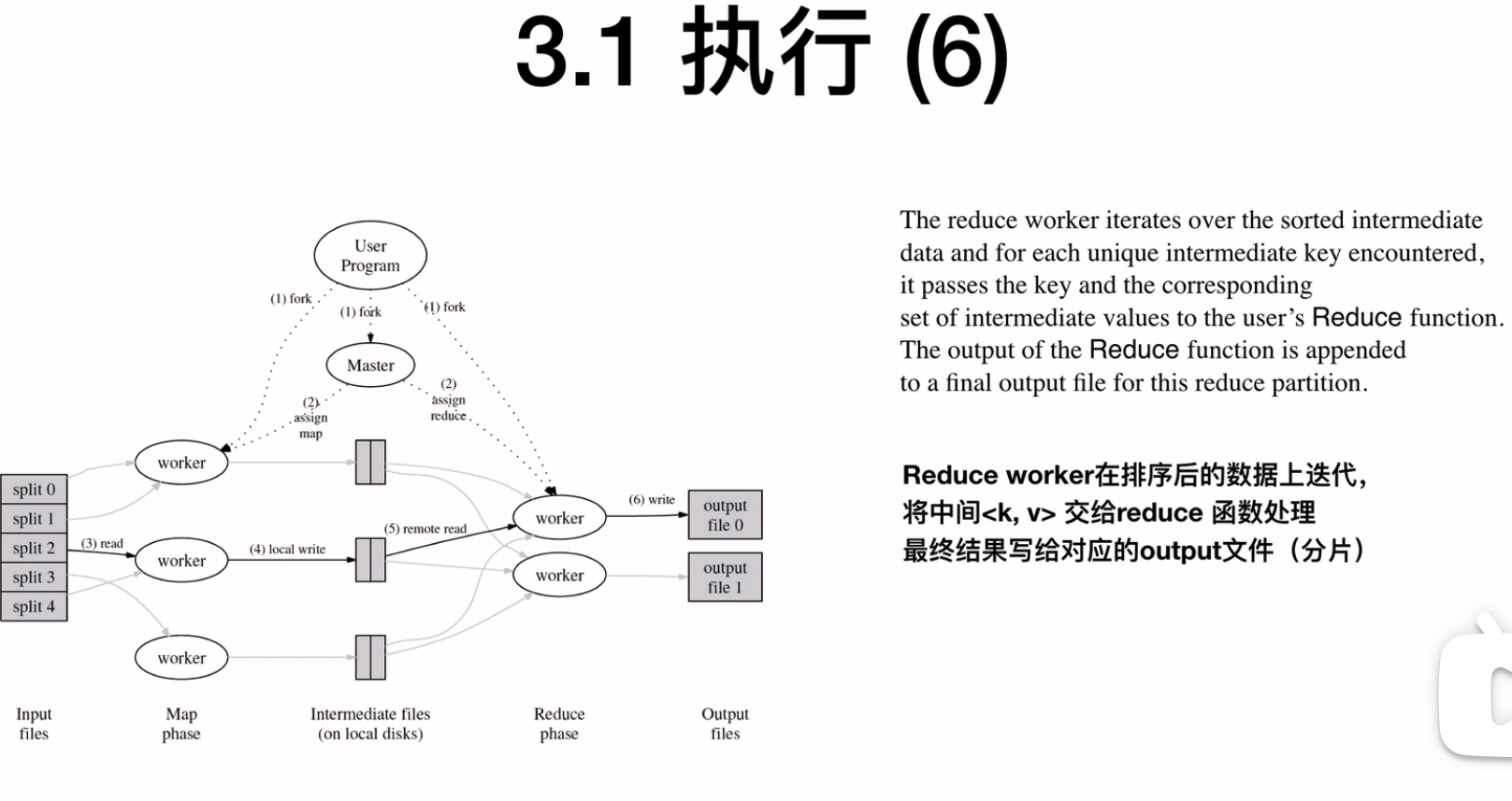
将排序后的数据,执行reduce函数,并写入到output文件
![]()
-
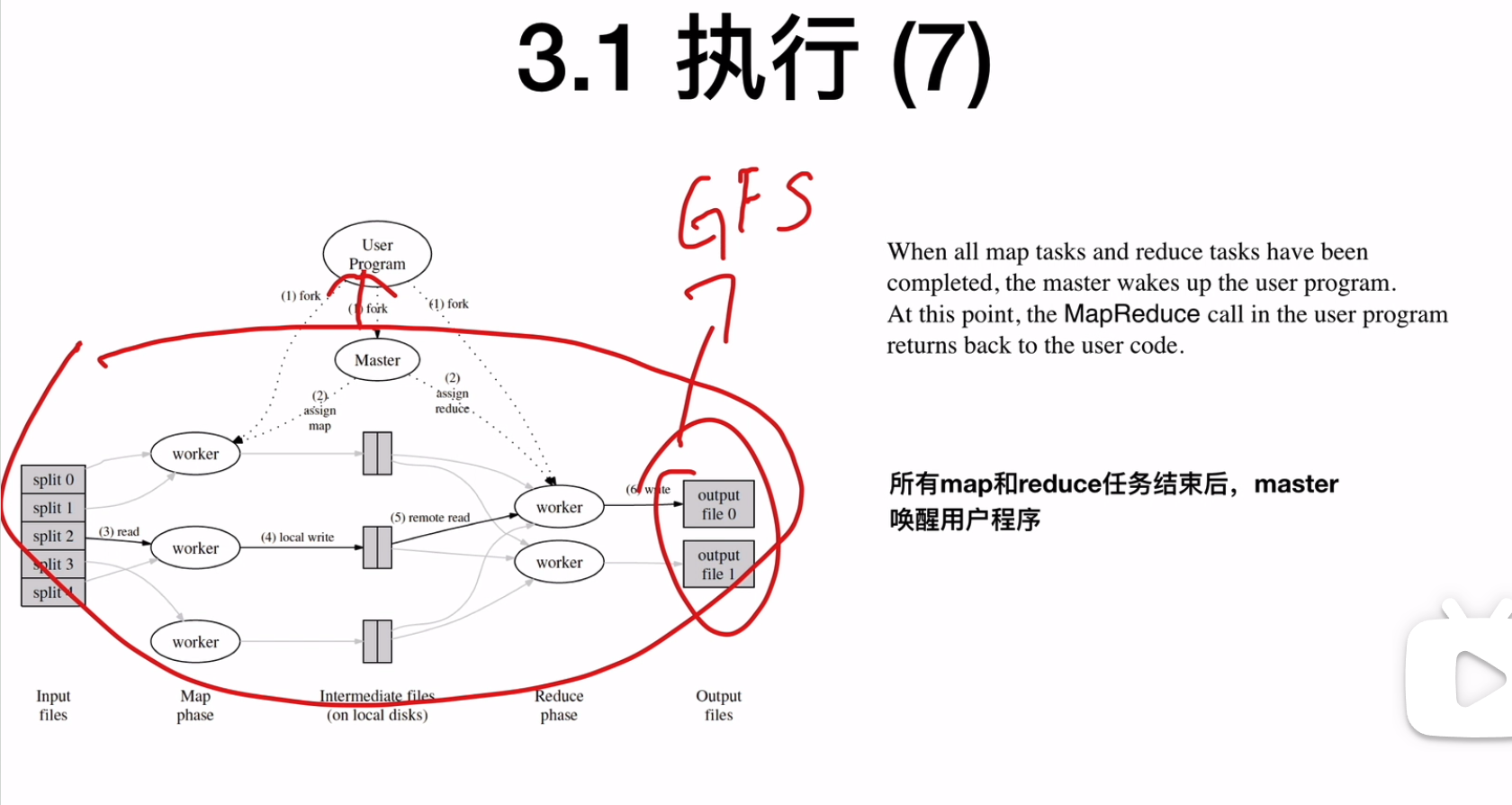
所有的output文件会被写到叫做GFS的全局文件系统,MapReduce程序结束之后,Master返回到UserProgram
![]()
Master数据结构
- 在master中会记录每一个task的状态,以及每个task属于哪一个worker machine
![]()

容错
分布式容错的本质就是在不可靠的硬件之上构建可靠的软件
Worker failure
- 对于map task的worker失效,对于已经完成的map task会被重新标记为idle,那么需要另一个worker重新执行map task,因为map的结果是存储在locl disk,而reduce的结果存在GFS中,GFS上的数据不会丢失,每个数据会有多个备份。并且关于这个map task的结果的位置,会被重新通知
![]()

Master failure
- master会周期性的备份数据(也就是tasks的状态),有备份点checkpoints
![]()

Backup Tasks
- 对于执行缓慢的任务(Straggler),在MapReduce操作接近完成的时候,master会对(in-progress)的余下任务启动backup执行,也就是创建一个副本task,(有可能原来的task卡住了),那么原来的task就是primary,当primary与backup中任意一个完成,那么该task会被标记为完成
![]()

Semantics in the Presence of Failures
- 需要保证MapReduce的确定性,文件大小必须是有界的,mpareduce本质是一个批处理系统,如果是流式的,那么每个map task的重新处理会不一致
![]()

副作用
- 命名的原子性以及两个Task去写一个文件
![]()

优化/完善
局部性优化
- 在具有输入文件的节点上,分配map任务
任务的粒度
combiner function
![]() zipf‘s law齐夫定律,在任何语言中存在一种现象,就是有些词出现频率高,比如英语中的the
zipf‘s law齐夫定律,在任何语言中存在一种现象,就是有些词出现频率高,比如英语中的the![]()
![]()
- map阶段结束之前不能启动reduce阶段,但是可以以combiner的身份执行reduce代码
![]()
 zipf‘s law齐夫定律,在任何语言中存在一种现象,就是有些词出现频率高,比如英语中的the
zipf‘s law齐夫定律,在任何语言中存在一种现象,就是有些词出现频率高,比如英语中的the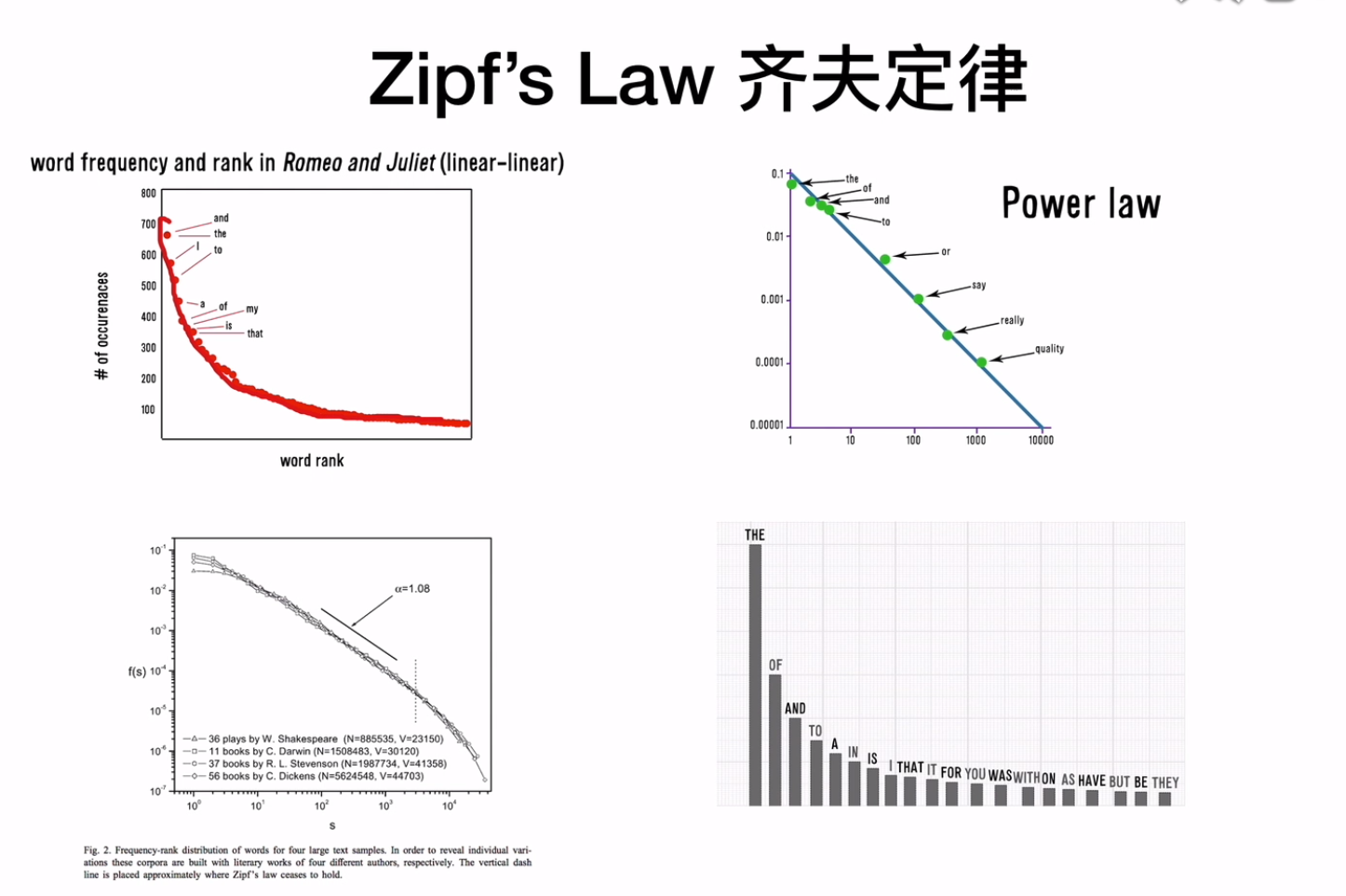


性能
经验
相关工作
结论
问题
our use of a functional model with user-specified map and reduce operations allows us to parallelize large computations easily and to use re-execution as the primary mechanism for fault tolerance.re-execution作为容错机制?![]() 输入的k/v与输出的k/v的类型不同,中间的k/v与输出的k/v类型相同?
输入的k/v与输出的k/v的类型不同,中间的k/v与输出的k/v类型相同?![]()
![]()
- shuffle过程在哪里?
 输入的k/v与输出的k/v的类型不同,中间的k/v与输出的k/v类型相同?
输入的k/v与输出的k/v的类型不同,中间的k/v与输出的k/v类型相同?


 浙公网安备 33010602011771号
浙公网安备 33010602011771号