CMU15445 Lecture 23 Distributed OLTP Database Systems
Decision Support Systems(OLAP database的别名)
OLTP获取数据,ELT将OLTP的数据Extract,Transform,Load合并成一个统一的模式,传给OLAP
Decision support systems,分析数据,做出未来的决策

数据的架构有两种:

Problem setup
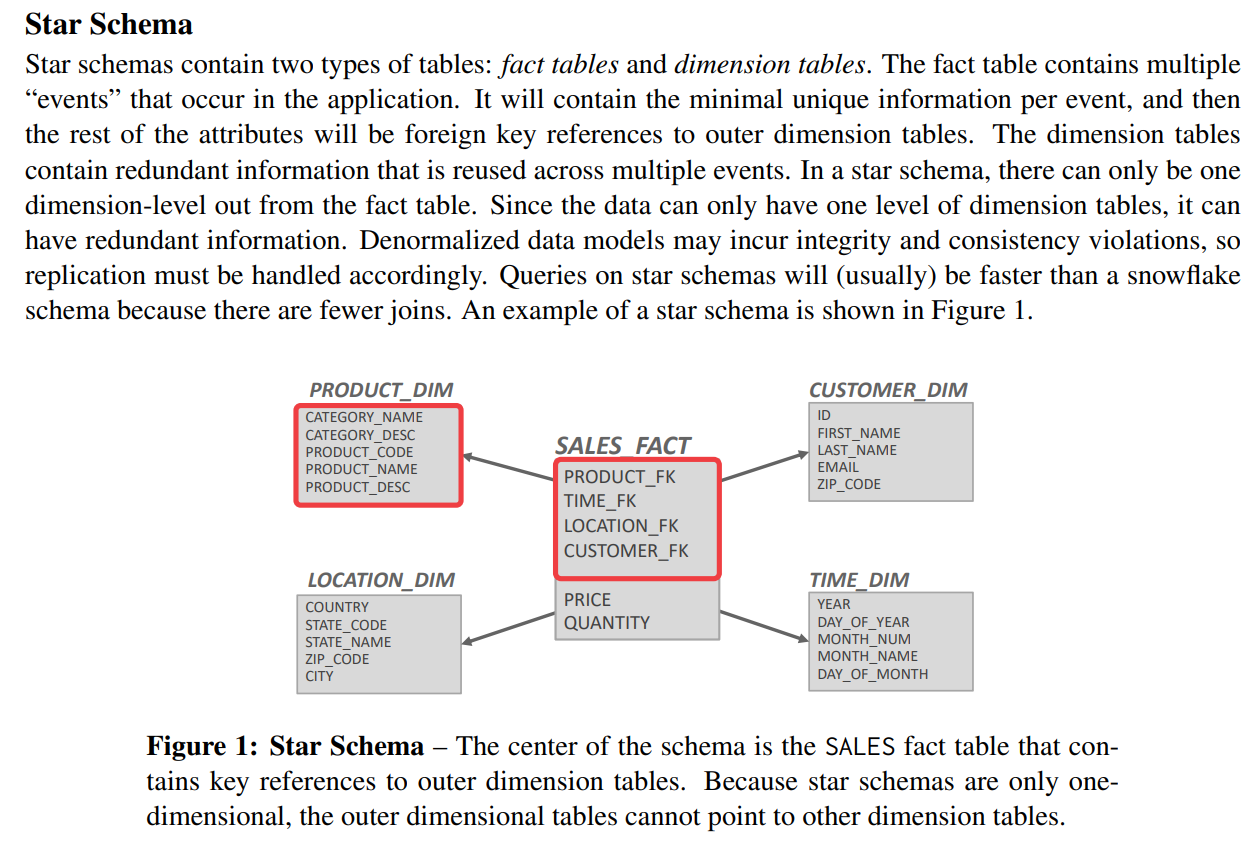
star schema
star schema只有两级的结构,一个中心,延展开的其他节点是对fact table每一个维度的描述
会出现信息冗余,Denormalized,数据可能会出现一致性与完整性问题,也就是说如果数据不用外键索引,那么可能会出现一个数据多种表示方式
satr shcema通常比snowflake更快,因为需要的table join少
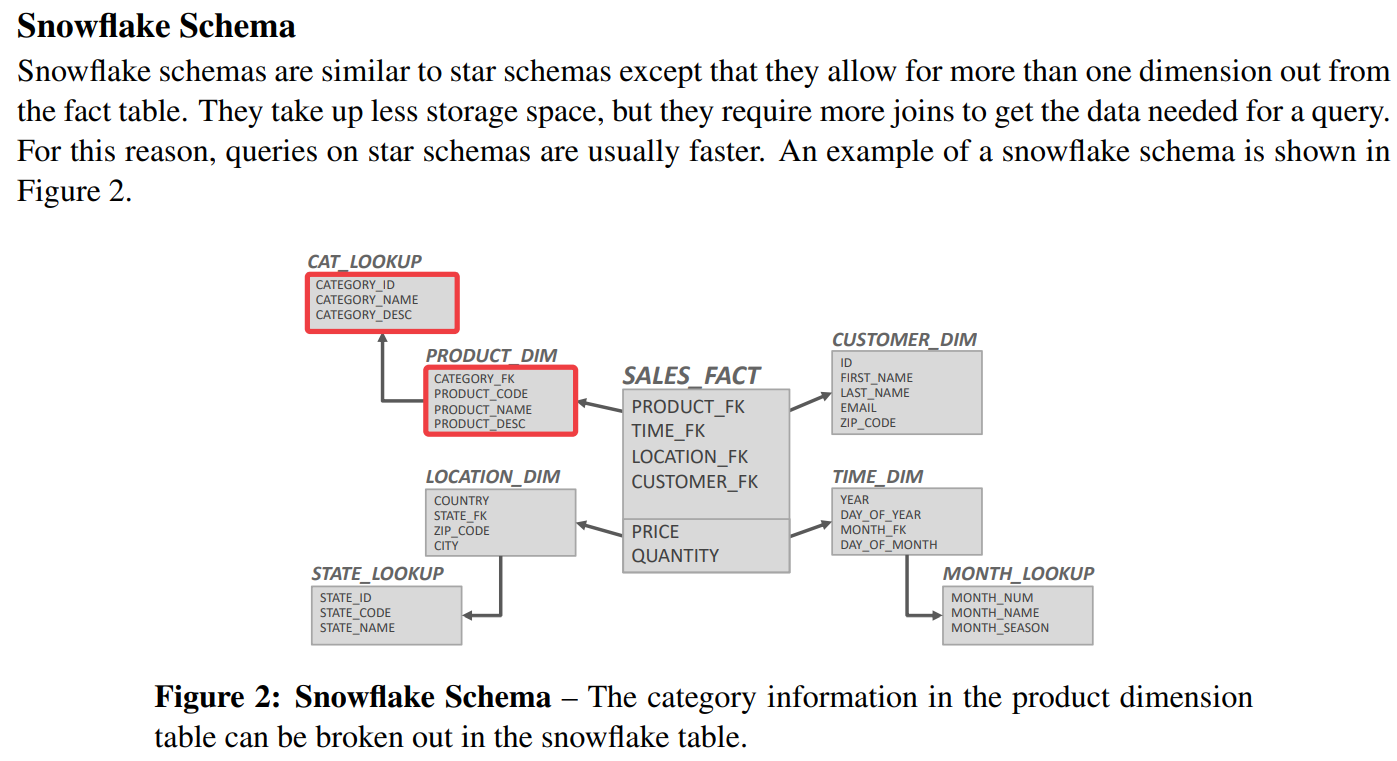
snowflake schema
snoflake 比 schmea需要的存储空间更少,到那时需要更多的table join,所以执行query更慢
Execution Models(多节点上的执行模型)
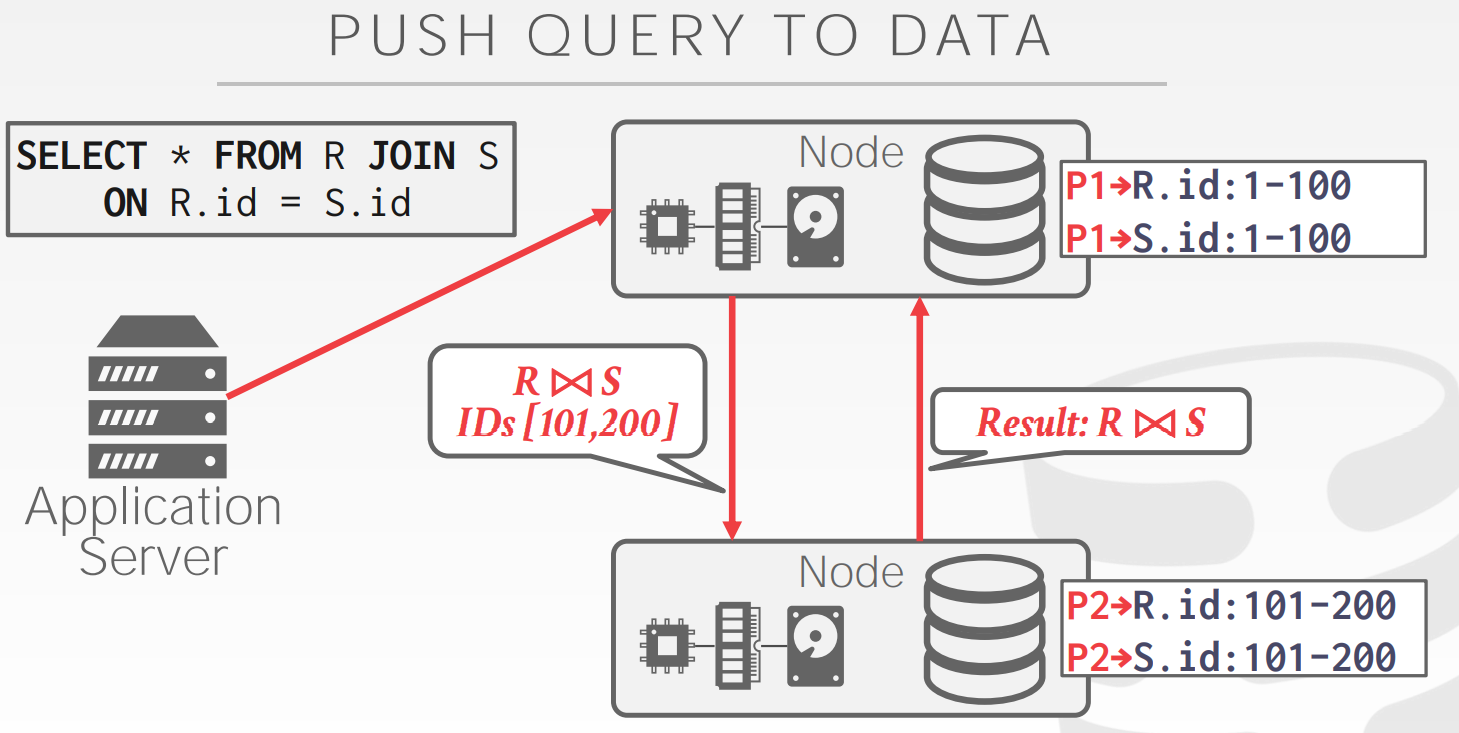
Pushing a Query to Data
- 把query push或者query的一部分发送到各个节点
- 在相应的节点上执行尽可能多的过滤、预处理操作,将尽量少的数据通过网络传输返回
![]()
上面的节点充当router,把query进行拆分
Pulling Data to Query
- 将数据移动到执行查询的节点上,然后再执行查询获取结果
![]()
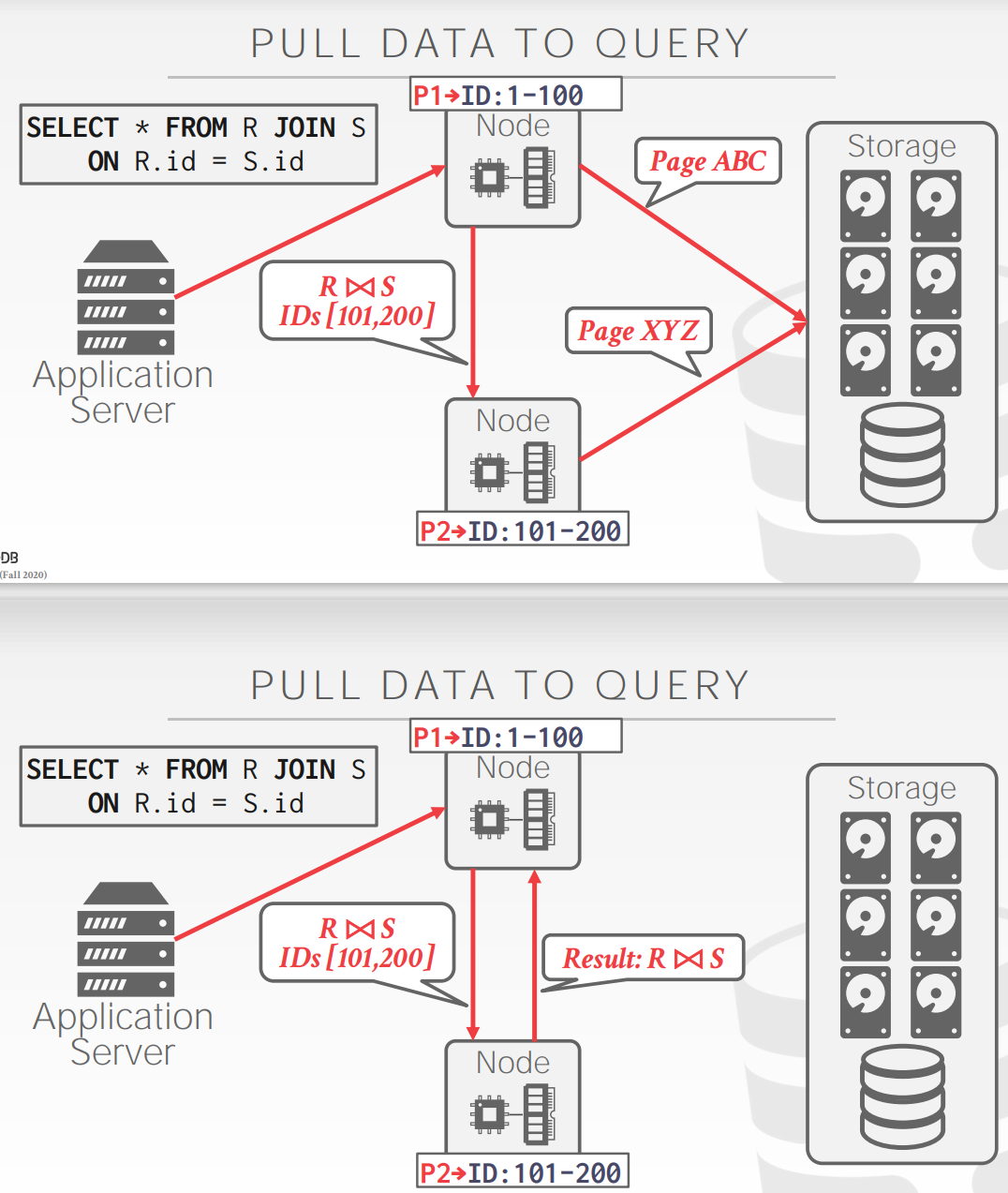
Query Fault Tolerance
将中间结果存到shared-disk?

cached in the buffer pool是指存到当前节点的缓存吧?那么存中间结果的快照才是存在shared-disk中?

Query Planning(多节点查询优化)
分布式查询优化还需要考虑数据的物理位置和network transfer cost
Physical Operators
把物理计划切分成小块,并分由各个节点去执行,在本地产生query plan分解成多个部分,发给不同的节点?
SQL
将原始的 SQL 语句按分片信息重写成多条 SQL 语句,每个节点自己在本地作查询优化。AP 说他只见过 MemSQL 采用了这种方案,举例如下:
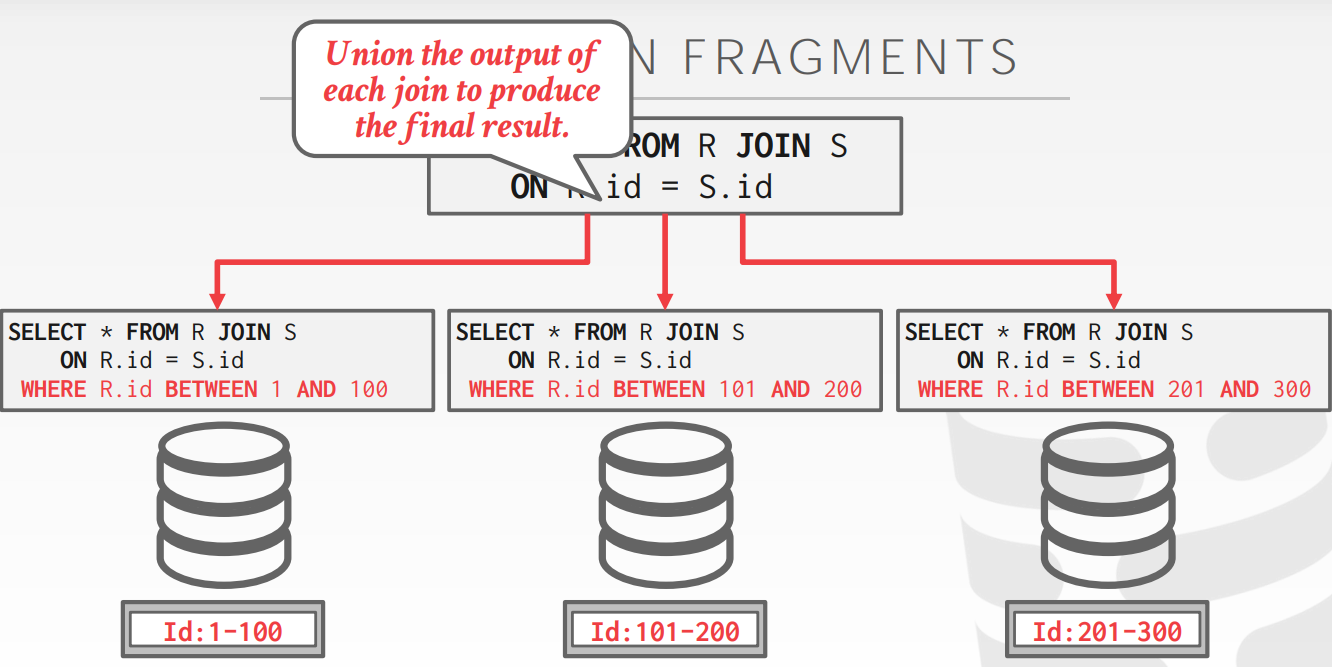
Distributed Join Algorithms
对于之前的SQL语句
SELECT * FROM R JOIN S ON R.id = S.id
假设了R与S表中id相同范围内的数据在一个节点上,这样并不现实。要获得R和S的join,我需要将join所需的数据移动到同一个节点上,之后便可以使用loop join,hash join等join策略
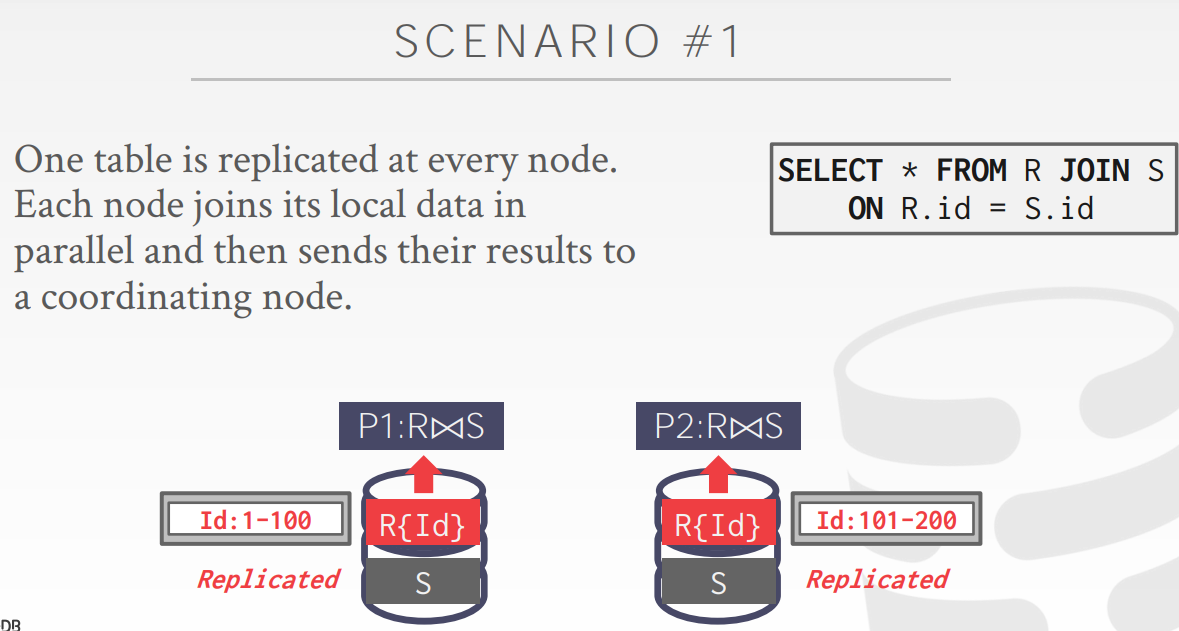
Scenario 1
如果S表非常小,那么可以这样做
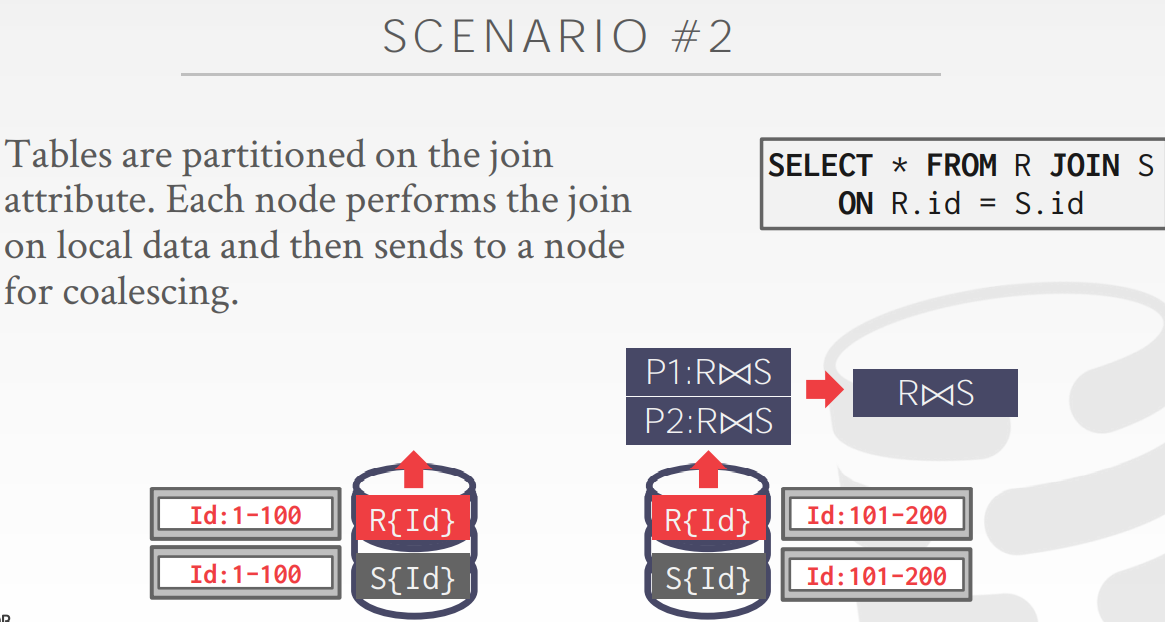
Scenario 2
如果分区依赖的列是经常被连表的列,那么这种做法容易实现
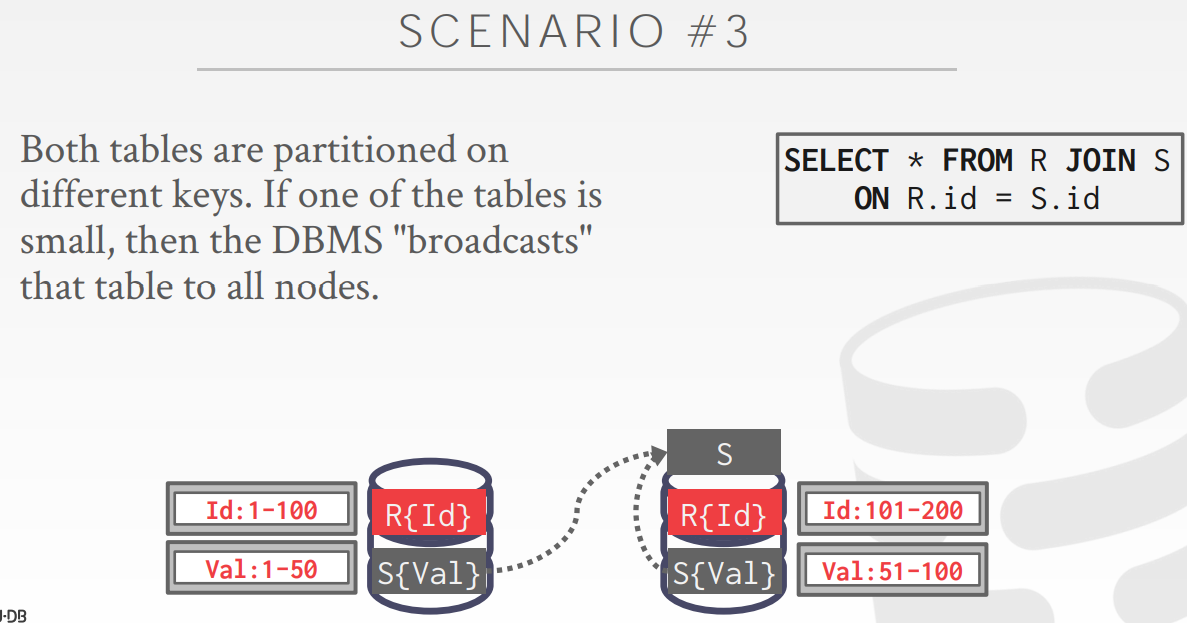
Scenario 3
这种分区依赖的列不是经常被连表的列,就需要两个节点把S表数据全都放到一个节点
broadcasts
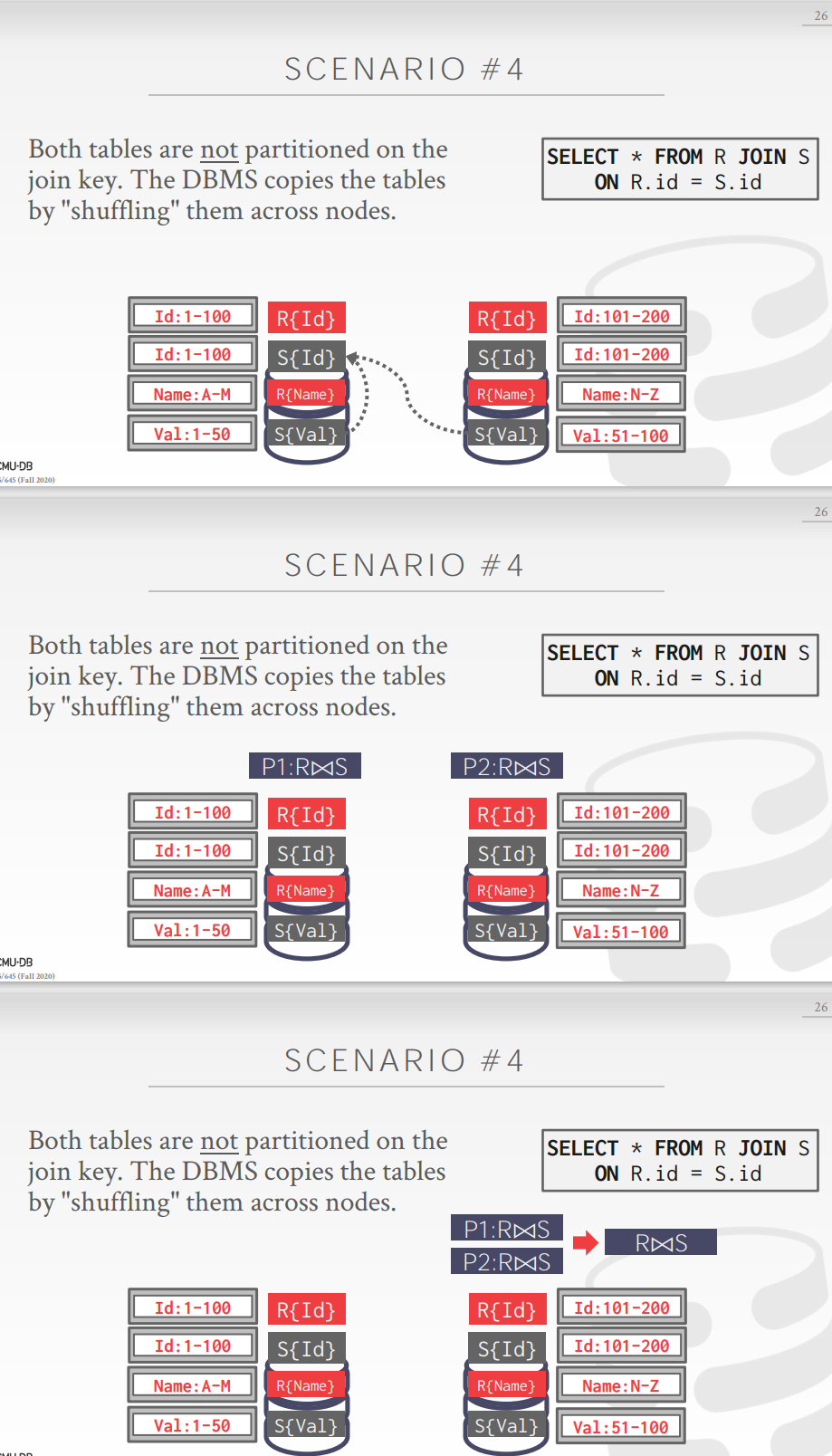
Scenario 4
临时按照join key重新分区,这种开销很大
semi-join
如果dbms不支持semi join,可以通过exist 伪造semi join。并且在分布式数据库的情况下,可以只传递R.id,也就是join id来达到优化分布式join的校效果

Cloud Systems
DBaas,云数据库模糊了shard-nothing与shared-disk,因为云计算的发展,shared-nothing变得愈发少了,因为本地的硬盘可以是云上的硬盘。云服务可以先过滤数据,再传送数据到计算节点

Managed DBMSs
一个运行在云服务器上的“云”DBMS

Cloud-Native DBMS
云原生DBMS,一般基于shared-disk架构

Serverless Databases

DBMS的底层page文件一般都是私有的


 浙公网安备 33010602011771号
浙公网安备 33010602011771号