CMU15445 Lecture 21 Database Crash Recovery
Crash Recovery 主要需要做两件事情,一件是txn processing before a failure,另一件是actions after a failure,本节主要介绍后者
那么什么时候flush dirty page呢?
Algorithms for Recovery and Isolation Exploiting Semantics (ARIES)
Write Ahead Logging
Repeating History During Redo
Logging Changes During Undo
?
WAL Records

写log的执行流程以及LSN的分类
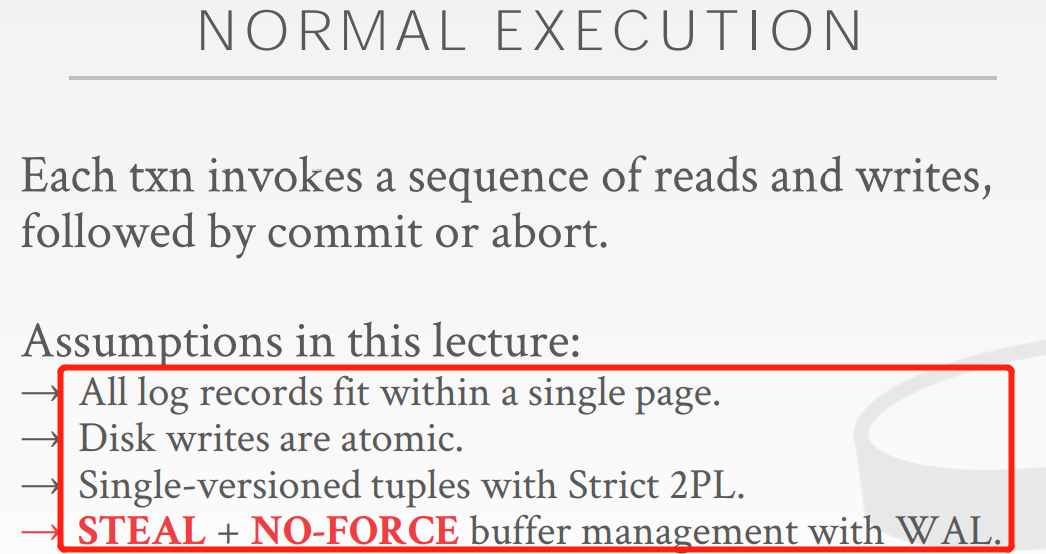
Normal Execution
对于每一个txn的执行以及写log的操作做的一定假设
- 所有的log都在一个page中
- 一个数据库的数据page可能是16k,disk page的大小可能是8k,那么就有可能disk write不是atomic,但是这个lecture假定其是atomic
- 没有mvcc,使用ss2PL
- 采取steal + no-force策略
![]()
Normal Execution
Transaction Commit
- 一个txn commit的时候,所有的该txn 的commit log之前log 都需要同步的(也就是直到log被刷到disk之前,该txn的相关线程都会卡住),连续的被写到disk
- txn-end是直到txn相关的dirty page也被刷入disk中时添加的log,有可能是chekcpoint的redo阶段做的"刷脏",这也体现了no-force的策略
do not need to be fushed immediately是啥意思?
![]()

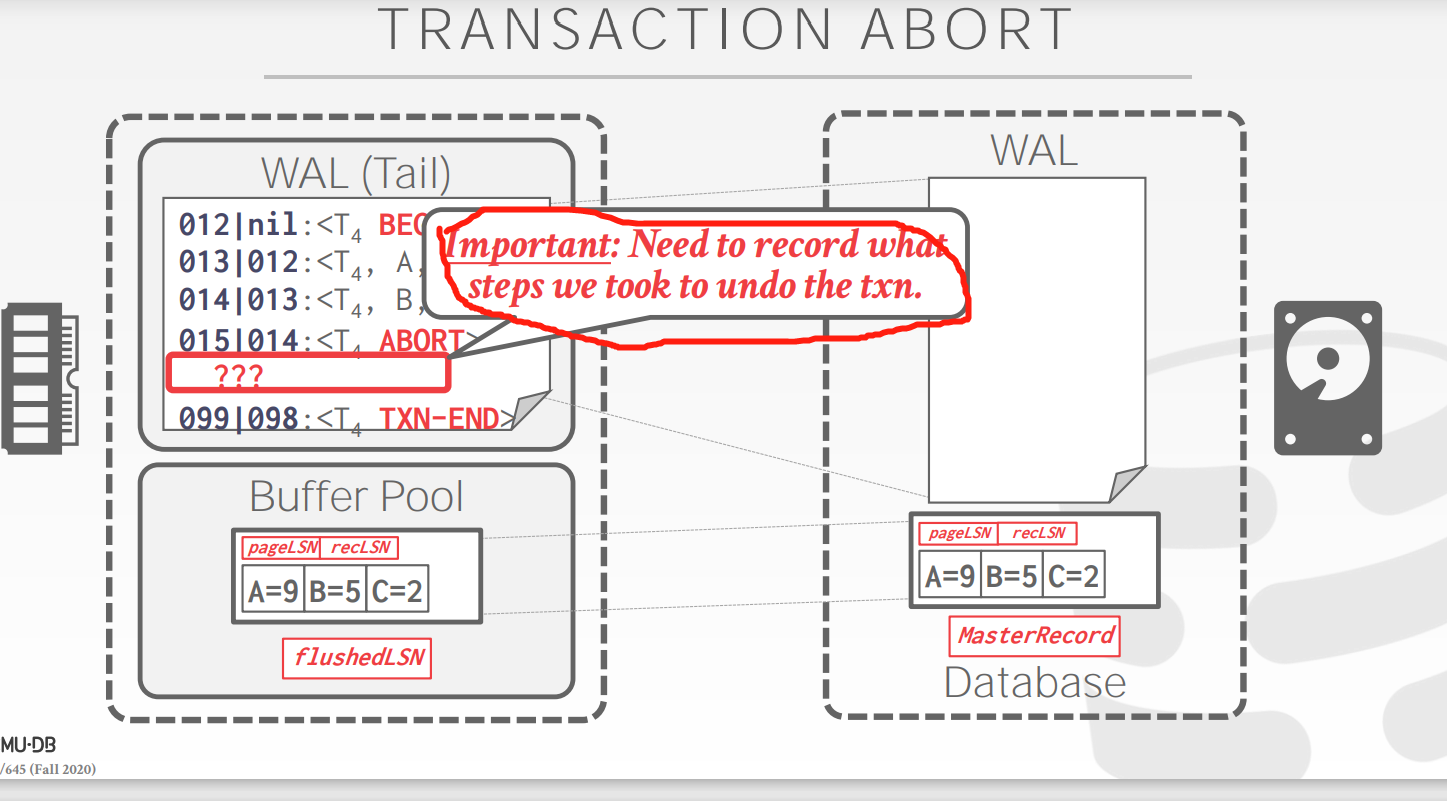
Transaction Abort
-
prevLSN指的是对同一个txn而言的上一个LSN
![]()
-
对于txn的undo,需要CLR log来记录undo 的 actions
![]()
-
CLR log并不需要强制刷入disk,因为如果期间碰到crash,下一次可以重新写CLR log
-
回滚结束的时候需要添加TXN-END log,并且对于CLR的log不需要递归的undo
![]()


Fuzzy Checkpointing
这个scanning到底是啥意思,对于blocking checkpoint不是已经确保了checkpoint之前的txn已经commit了吗?

Blocking Checkpoints
blocking checkpoint确保所有txn commit,这样recover的时候就很简单

Slightly Better Blocking Checkpoints
优化的点是,不要等待所有的txn都结束,而是要所有的txn修改都停止,但是需要额外的记录?这个是lecture 20介绍的checkpoint吗

当活跃事务表中的事务abort或者是commit,也就是写入了TXN-END log,才把该事务移除

脏页表记录没有刷盘的脏页,脏页表会记录每一个脏页的recLSN,也就是第一个修改该页的log

但是这种checkpoint任然需要暂停txn的修改,比如下面的<CHECKPOINT ATT={T3},DPT={P11,P33}>,需要暂停T3,保持只有P11和P33是脏页

Fuzzy Checkpoints
主要思想是把checkpoint设置为一个阶段,也就是分为checkpoint-begin和checkpoint-end
开始于checkpoint-begin 之后的txn不会被写到活动事务表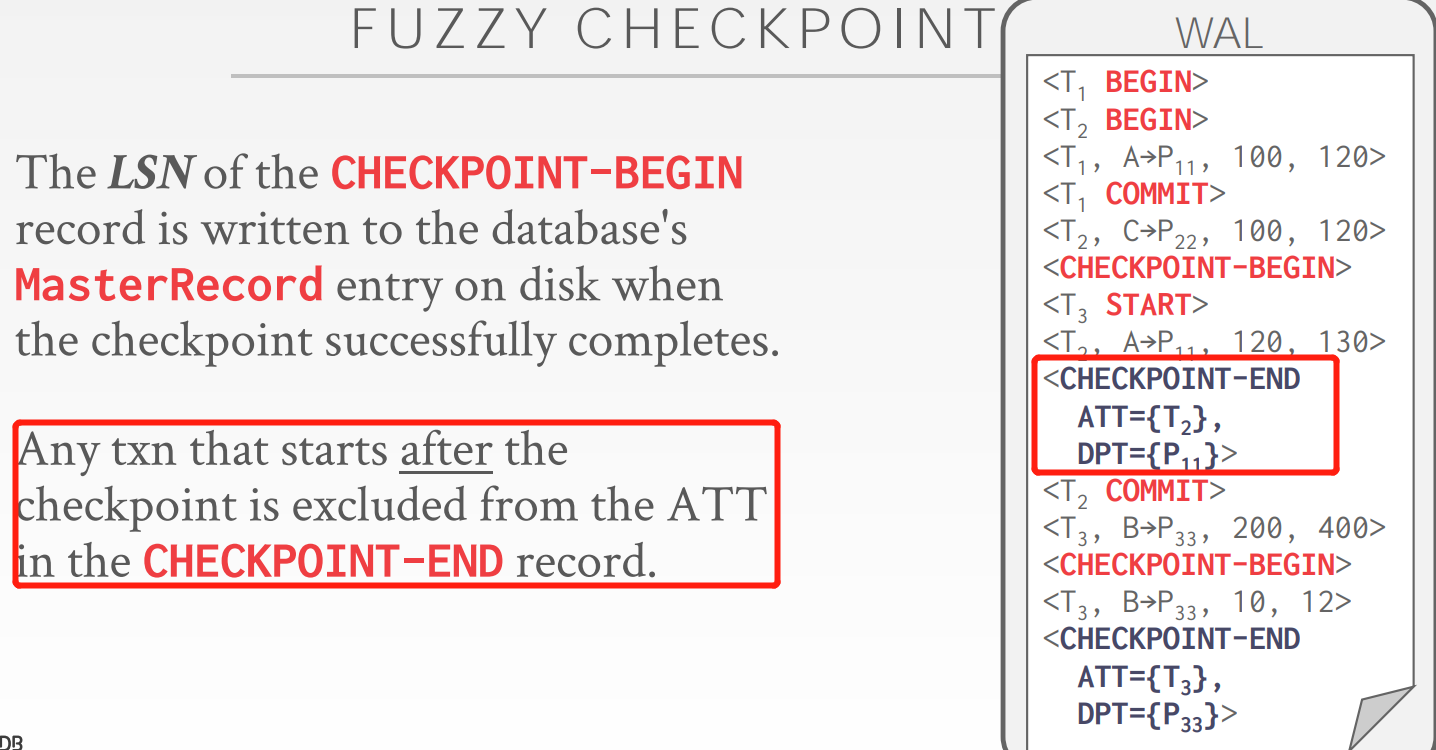
ARIES Recovery

analysis分析需要redo和undo的txn
redo找到脏页表中的脏页的smallest recLSN,做日志的回放?日志回访到底是干嘛?还需要处理commit了但是还没TXN-END的txn
undo找到活动事务表中txn,这些txn因为在crash时都在执行,那么它们需要回滚?回滚具体做啥?

analysis
analysis分析得出脏页与活跃txn,分别加入ATT和DPT,注意,是从last checkpoint-begin开始扫描

redo
?aborted txns是指将memory上page回到脏页状态再将脏页回滚吗?

redo的修改还是在memoery中执行,这两处是不是矛盾啊,不强制flushing,但是又要去添加 TXN-LOG?就是说在redo之后 ,对于status C的txn需要直接flush吧

undo
- 对于redo之后,存在需要回滚的txn,也就是未commmit的txn,需要做undo
- undo的时候,需要写CLR,这样可以提高效率,如果回滚的时候再次crash,可以接上上一次的回滚
- crash之后的活跃txn表,表明这些事务所做的修改都是无效的
![]()

issue
redo之后,后台异步刷盘
undo采取懒加载,也就是对于memeory中的page先不做修改,当有线程访问时,再修改,并且不要写超长的txn,undo的时候费时间


 浙公网安备 33010602011771号
浙公网安备 33010602011771号