CMU15445 Lecture 18: Timestamp Ordering Concurrency Control
2PL是实现并发控制的一种方式,它是pessimistic,因为它假设如果不加锁,未来便会出问题。T/O也是一种并发控制的方式,它是Optimistic,通过设置时间戳,使得schedule达到serializable
Timestamp Ordering Concurrency Control
有多种时间戳的实现方式:System clock,Logical Counter,Hybrid

Basic Timestamp Ordering (BASIC T/O)
T/O需要保证TS小的txn最终表现为完整的在TS大的txn之前发生,本质就是事务不能够操作来自未来的数据

Read Operations
为什么要自己留下一份?防止重复读的时候数据被修改,为了保证一定的隔离级别,那么需要copy
Write Operations

下面这个例子对于T/O而言是不能通过的,但是它的本意是T1在T2之前发生,但是这里可以使得T1的W(A)不往数据库里头写,而是写在本地,要T2的W(A)写往数据库,那么结果符合假设,但是T(1)最后的R(A)究竟读什么数据?为了保证serializable,那么T1需要读TS小于等于自己的写,所以读的是自己的W(A),也就是读了自己的本地副本,这就是Thomas优化
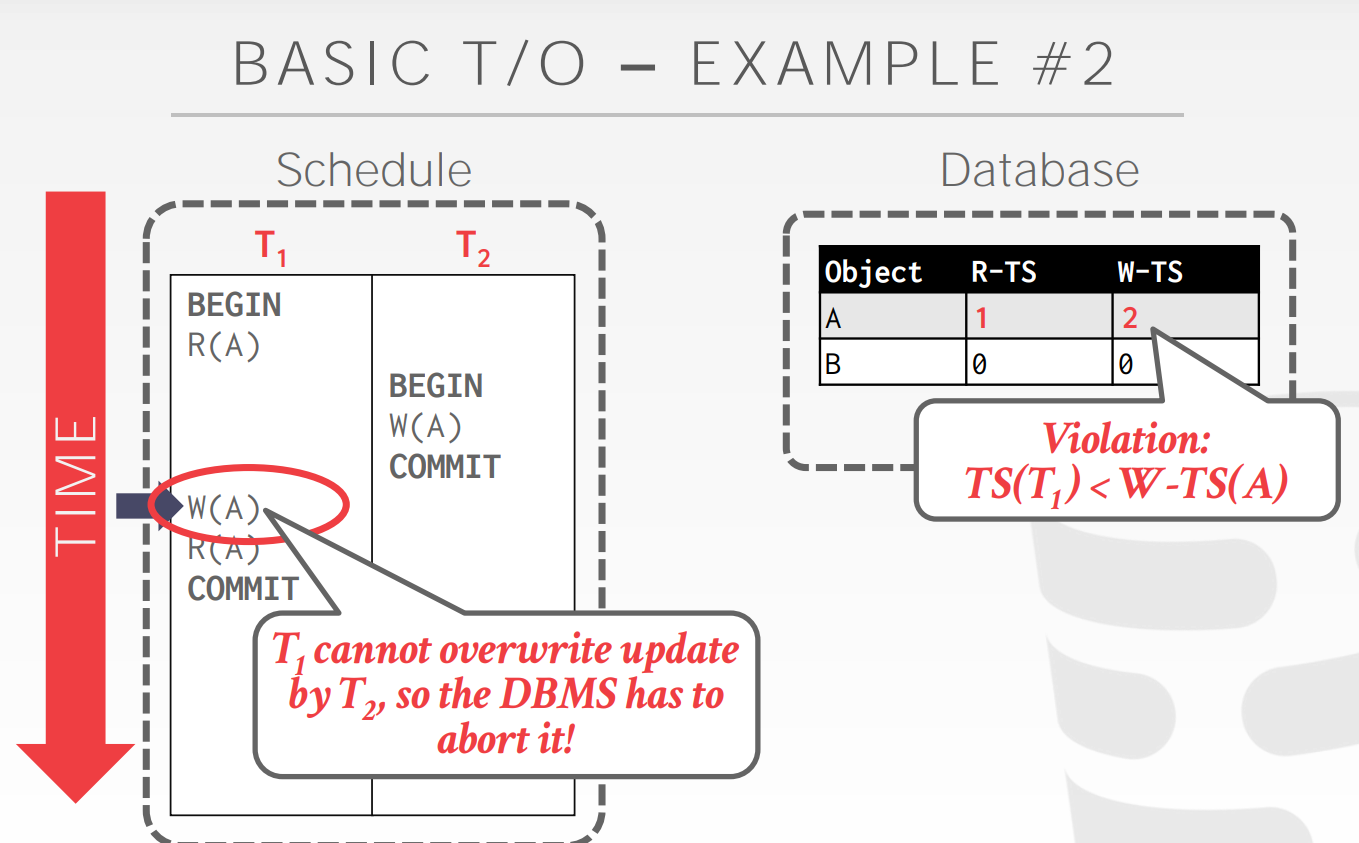
Optimization: Thomas Write Rule
即使是未来的写发生了,那么过去写还是可以发生,可以认为是写了但是被覆盖了?
BASIC T/O保证一个conflict serializable的schedule

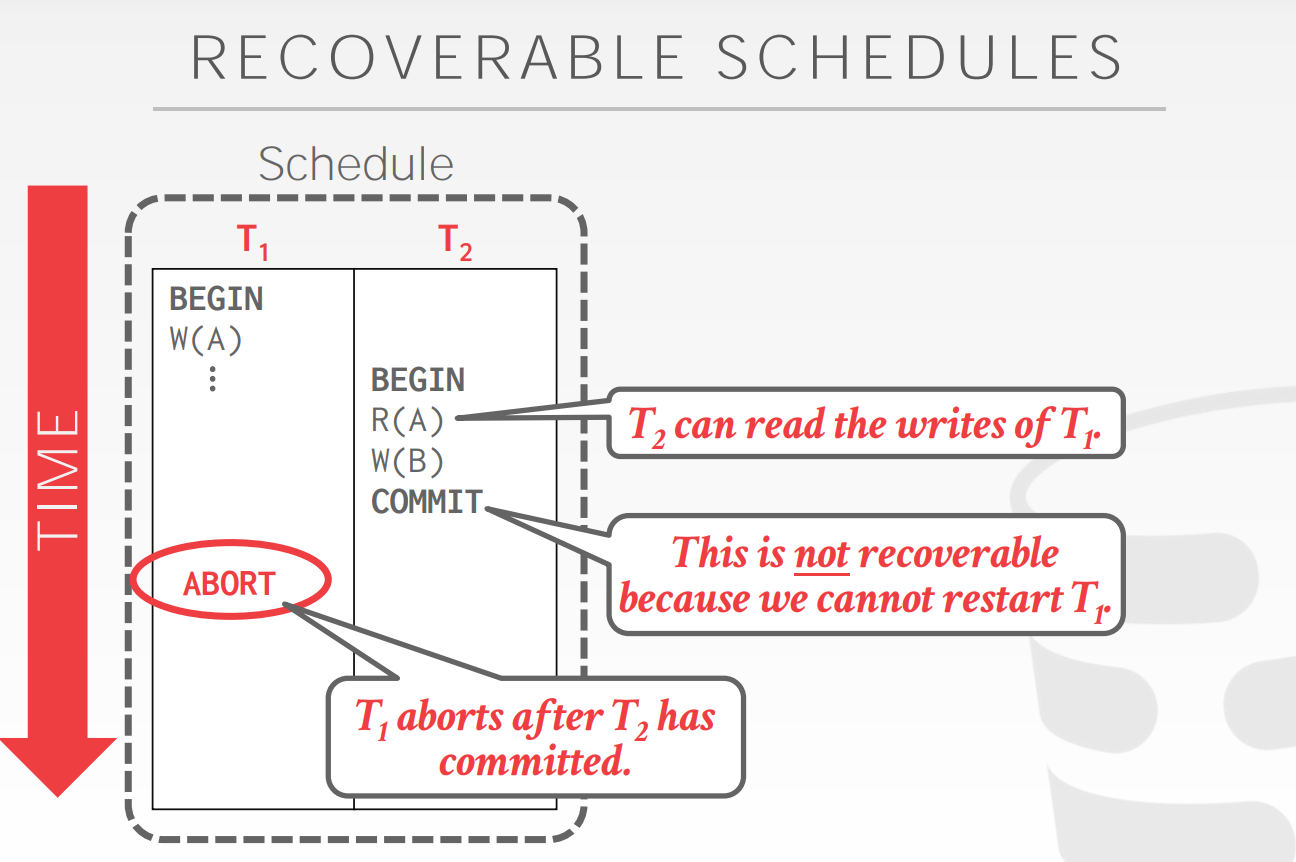
一个schedule是可恢复,当txns读的数据来自于那些已经commit的txns?否则DBMS不能够担保txn读的数据是可恢复的?recover到底啥意思recover应该就是指恢复到原来的数据

以下是非recoverable的schedule,因为T1 abort了,那么T2读的T1的数据完全是错误的?
T/O issues
- 读数据时需要往本地拷贝,拷贝开销大
- 长时间运行的事务会饥饿,因为它的TS太小了,以至于其后面的txn大都完成了读,那么长时间运行的事务必须得终止
![]()
- ?
![]()

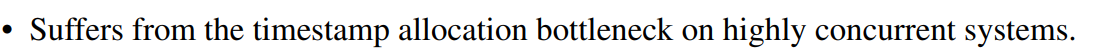
T/O适合conflict少且所有的txn都是运行时间短的
?OCC适合基本没有conflict的schedule

Optimistic Concurrency Control (OCC)
OCC非常适合This is when either all of the transactions are read-only or when transactions access disjoint subsets of data. If the database is large and the workload is not skewed, then there is a low probability of conflict, making OCC a good choice.
为什么适合not skewed的workload?因为database非常大且worklod是not skewed(not skewed表示均匀的),意味着txn之间大概率access disjoint subsets of data
OCC需要将修改与object read都放到workspace,等到commit的时候在放到global database


read phase
为了达到repeatable read,需要将write/read 的数据放到 private workspace,reaptable read就是为了实现schedule 的 serializable

validation phase
txn进入validation phase才会被分配时间戳
,validation 保证schedule是seializable,并且保证conflict是一个方向的

backward validation
backward validation是和已经提交了的事务进行校验,如果当前要提交的事务与之前已经提交的事务冲突了,那么当前事务abort
forward validation
forward validation需要与还未提交的进入提交阶段的事务做冲突检测
1和3有啥区别?

write phase
write phase需要写全表,确保其他thread读到的数据是同一时间的
issues
- overhead of copying data
- vaildation/write phase过于复杂,可能会成为瓶颈
- 非常的wasteful,因为txn只有在vaildation的阶段才会abort,浪费的operation一般较多
![]()

Isolation Levels
Phantom Read
2PL锁了现存的东西,但是控制不了insertion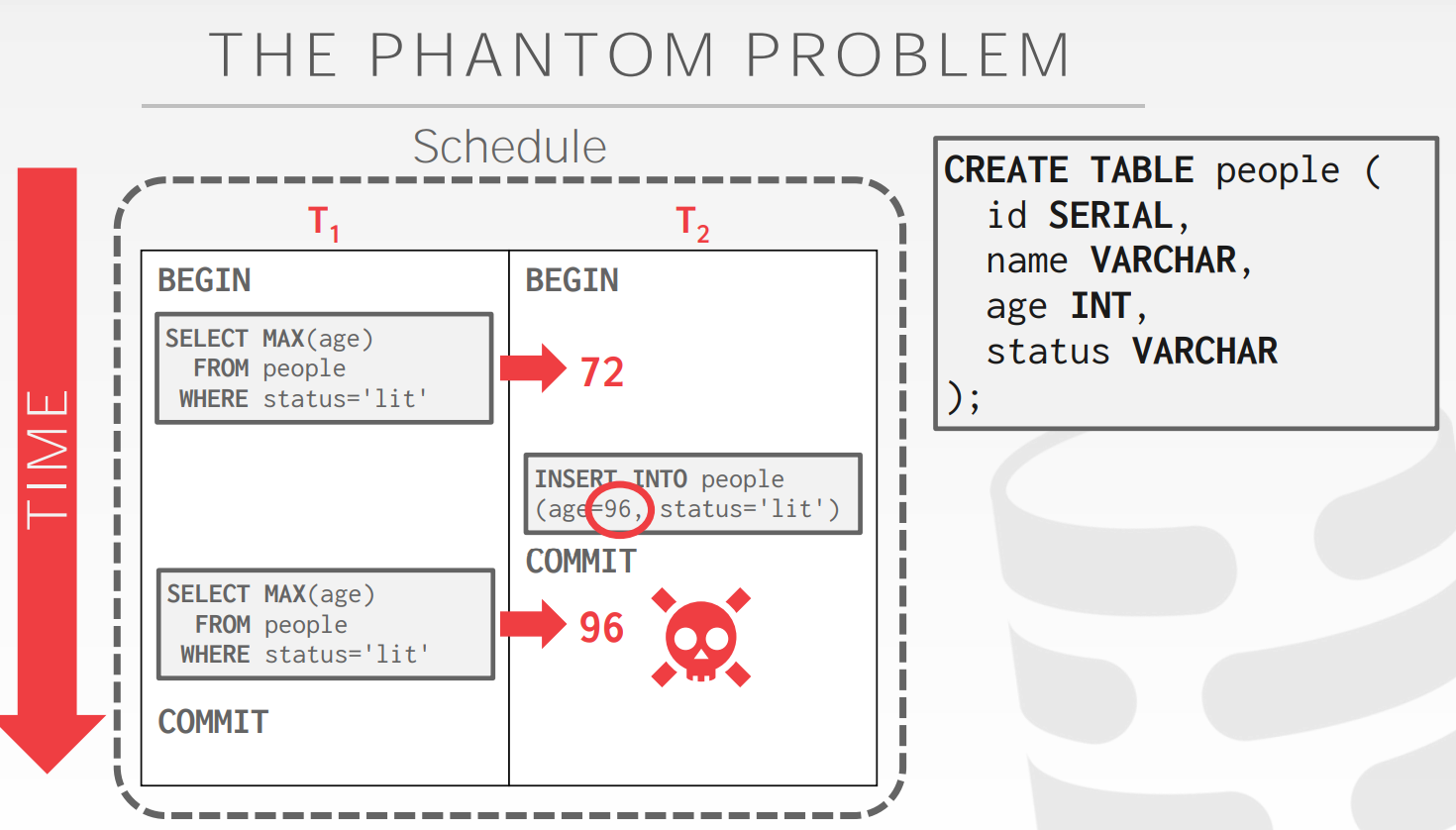
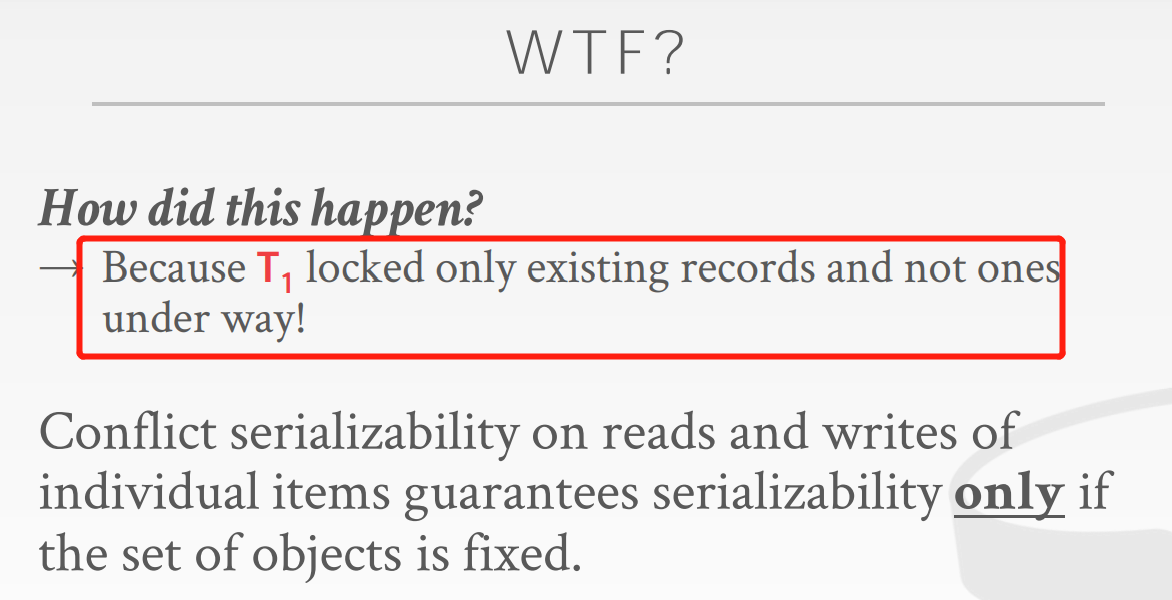
Re-Execute Scans
对于每次range query 的scan set,DBMS跟踪,并在commit之前,重新执行以检测range query,查看结果是否一致?

Predicate Locking
谓词加锁
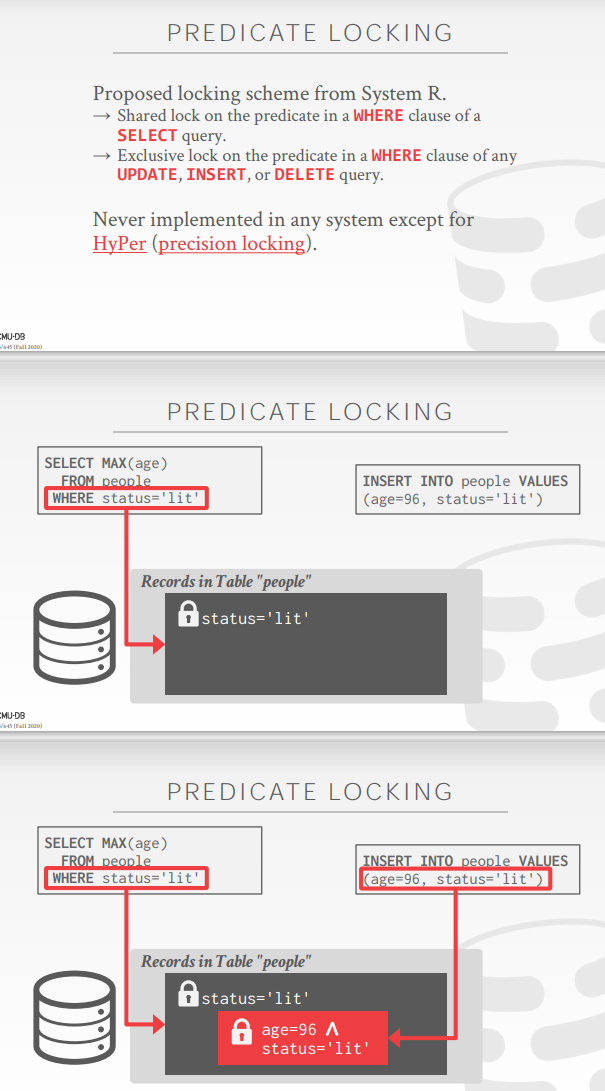
Index Locking
给谓词index加锁,如果该谓词没有index,那么给higher table加锁,对于一个index加🔒,那么当需要insert的时候,insert算子会调用seq_scan算子,seq
_scan算子会通过谓词获取tuple,如果对于谓词index加🔒,这时就可以阻止phantom

MySQL解决幻读的方式是间隙锁,比如数据是1,5,7,9,那么1与5之间的间隙也要加锁,再比如,对于Max,如果第一次select的是数据啊,那么第二次select之前需要对于间隙(a, +∞)之间加间隙锁
serializatiable大大的牺牲了并行性?所以可以有一些更加低的隔离级别
Isolation Levels
隔离级别的分类
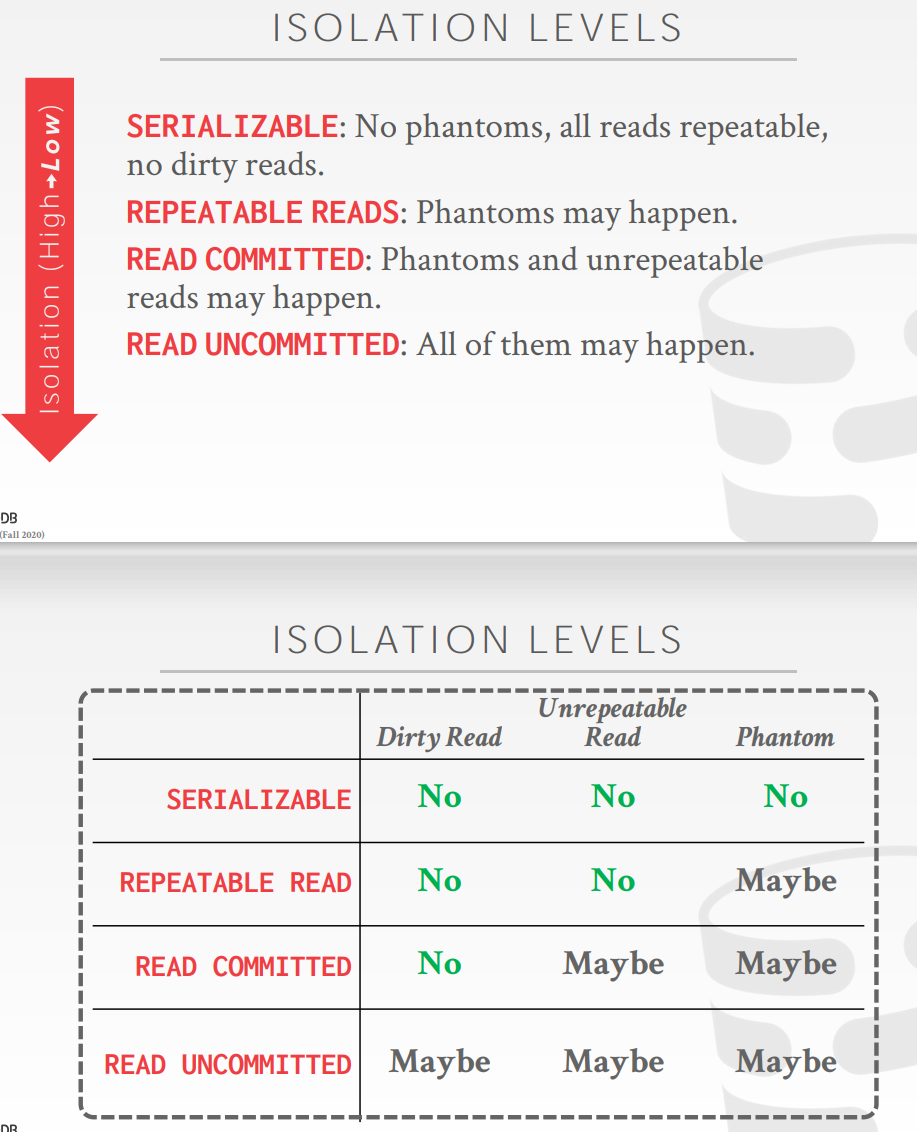
隔离级别的实现

snapshot isolation是oracle的最高隔离级别


 浙公网安备 33010602011771号
浙公网安备 33010602011771号