CMU15445 Lecture 12 & 13 Query Execution
Query Plan
?multiple way指的是可以按照单一tuple的粒度往上emit,或者是按照batch的tuple的粒度往上emit,或者是整个要求的数据集合的粒度往上emit
Processing Models
Processing Models定义了query plan的执行从什么方向读取以及算子(operator)之间传递什么样的数据。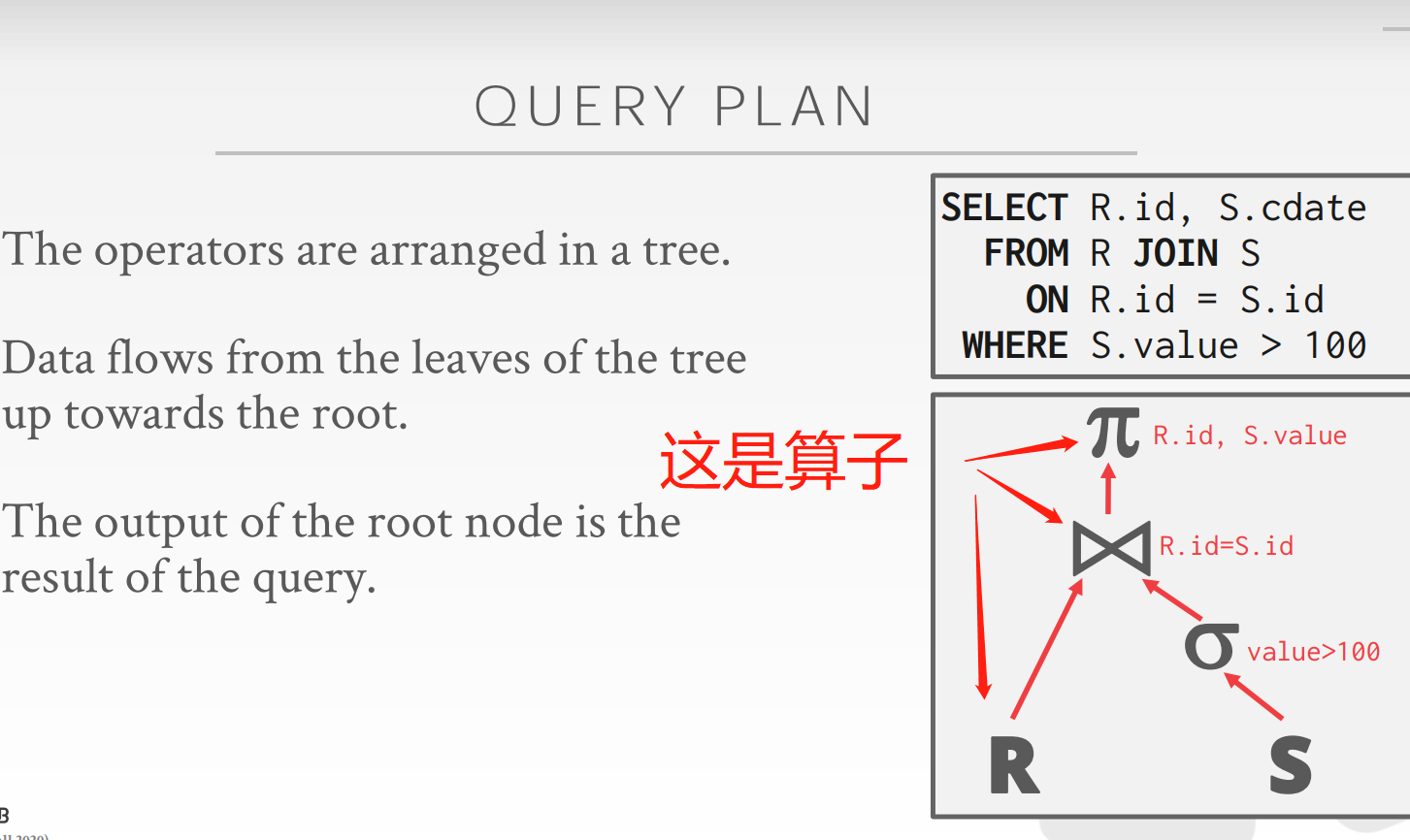
model有两种调用算子的方式(函数调用的方向)
- 自顶向下:较常用
- 自下而上:能够更好的控制管道中的寄存器或缓存?
Processing Model
Iterator Model(又叫火山模型)
每个operator实现一个Next()函数:
- 每次调用该函数,算子返回一个tuple或是null标记
- 父operator实现一个循环去调用其子operator的Next()以获取tuple并处理他们,也就是emit,以返回到祖先operator
对于join算子,首先调用outer table的每一个tuple去生成hash table,然后是调用inner table中的每个tuple去生成join成的tuple,之后便可以emit join之后的tuple了![]()
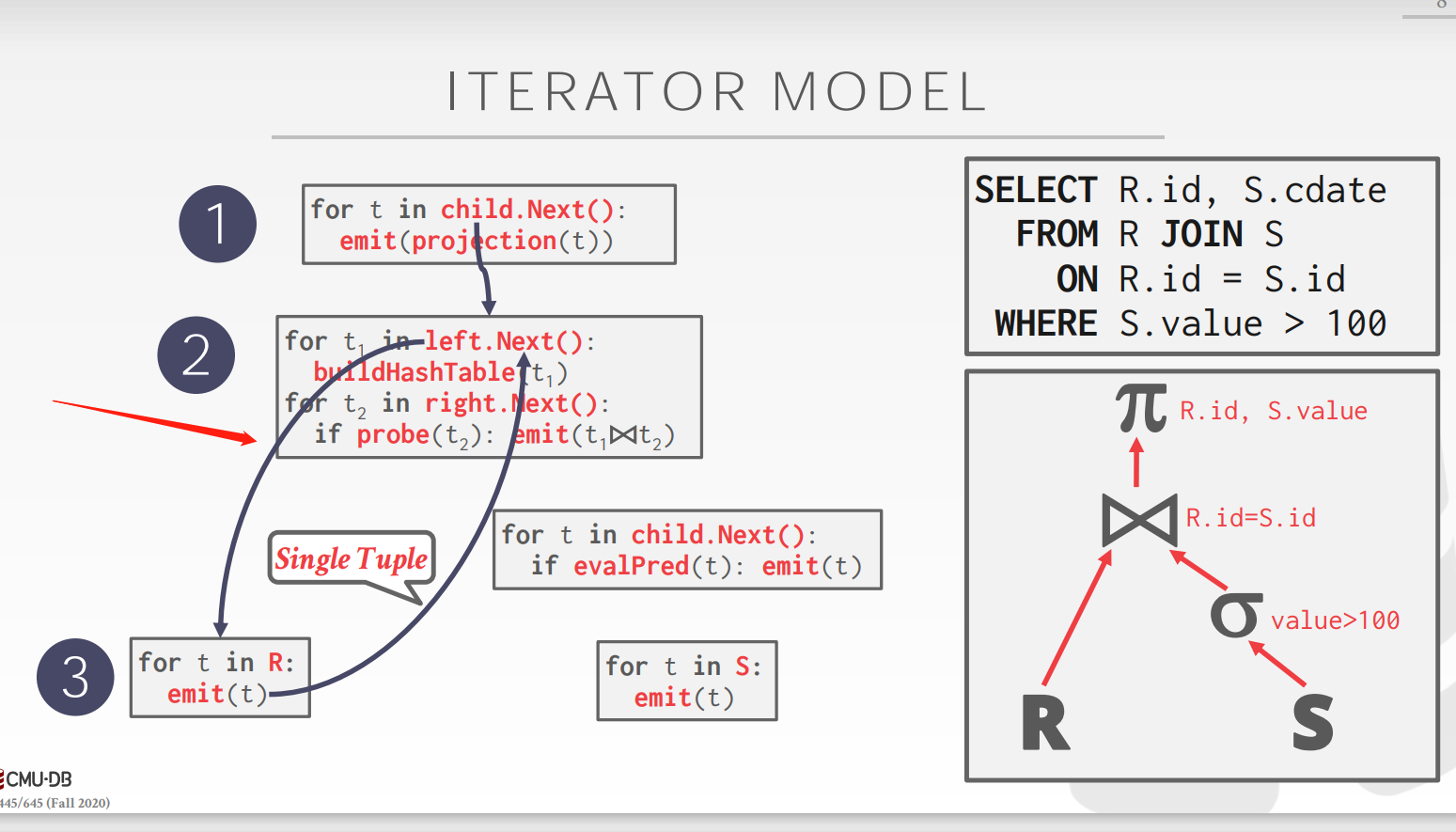
Materialization Model
直觉上的DBMS执行query plan的model
该model的执行过程大体是:
- 每次调用一个operator,该operator以数组的形式返回给父级operator所有的结果tuple,
- 适合OLTP的数据库,因为这种数据库主要执行点查询
- 但是不是OLAP的数据库,因为这种数据库一般会有大量的中间结果,也就是一个operator传递的数据量巨大
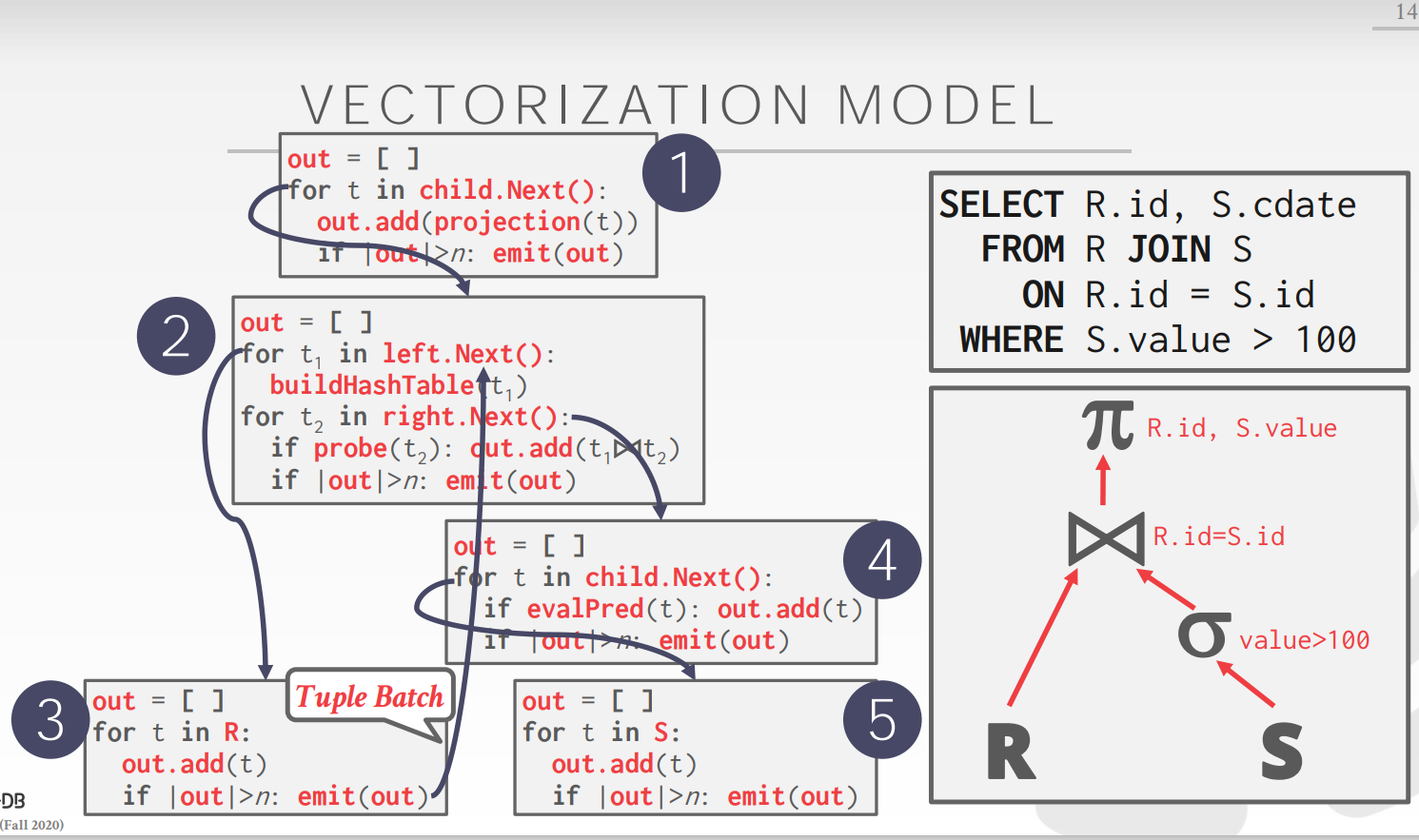
Vectorization Model
与Iterator Model类似,:
- 每个operator实现一个Next()函数,每次调用该函数,不同的是,每次返回一组tuple,而不是一个tuple
- 一组具体的大小与软硬件相关
![]()
适合OLAP的数据库,并且可以利用CPU的SIMD指令(Single Instruction Multiple Data)
Access Methods
Access Methods指的是DBMS读表的方式:
- 基于index读表
- multiple index(Bitmap Scan)是 index scan的扩展?
- 线性扫描
?![]()

Sequential Scan
基本的Sequential Scan就是全表扫描

基本的优化:
- 预取
- 对于线性扫描的数据,不放到缓存池中
- 并行取数据,比如用两个cursor在表的首尾扫描
- Heap Clustering: Tuples are stored in the heap pages using an order specified by a clustering index.
tuples以聚簇index指定的方式存在heap page中
![]()

Zone Maps
- 该方法首先给每个page统计aggregation的信息,以此决定需不需要将该page读入内存
- 此方法的缺点是需要维护Zone Map
![]()

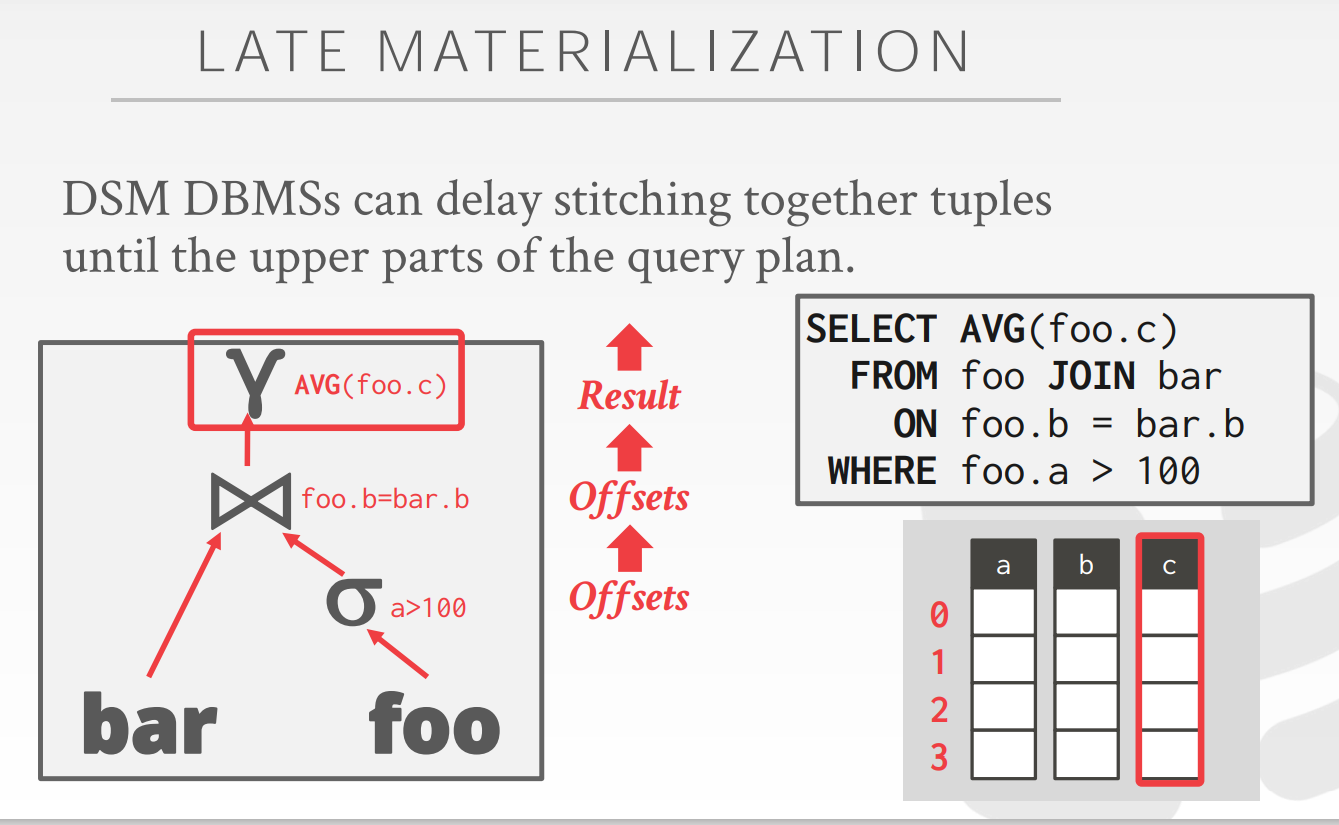
Late Materialization
适合于DSM(列存储:Decomposition Storage Model)存储tuple,不适合行存储的tuple,N-ary Storage Model (NSM)?
注意这里并不是index,这里传递的是offset
Index Scan

MULTI-INDEX SCAN
就是取多个index,根据谓词,取结果的交集或并集
Modification Queries
修改数据库的Operator需要满足一些条件:
- Insert,如果存在unique约束,那么不能插重复的值
- Insert,Update,delete也需要更新对应index
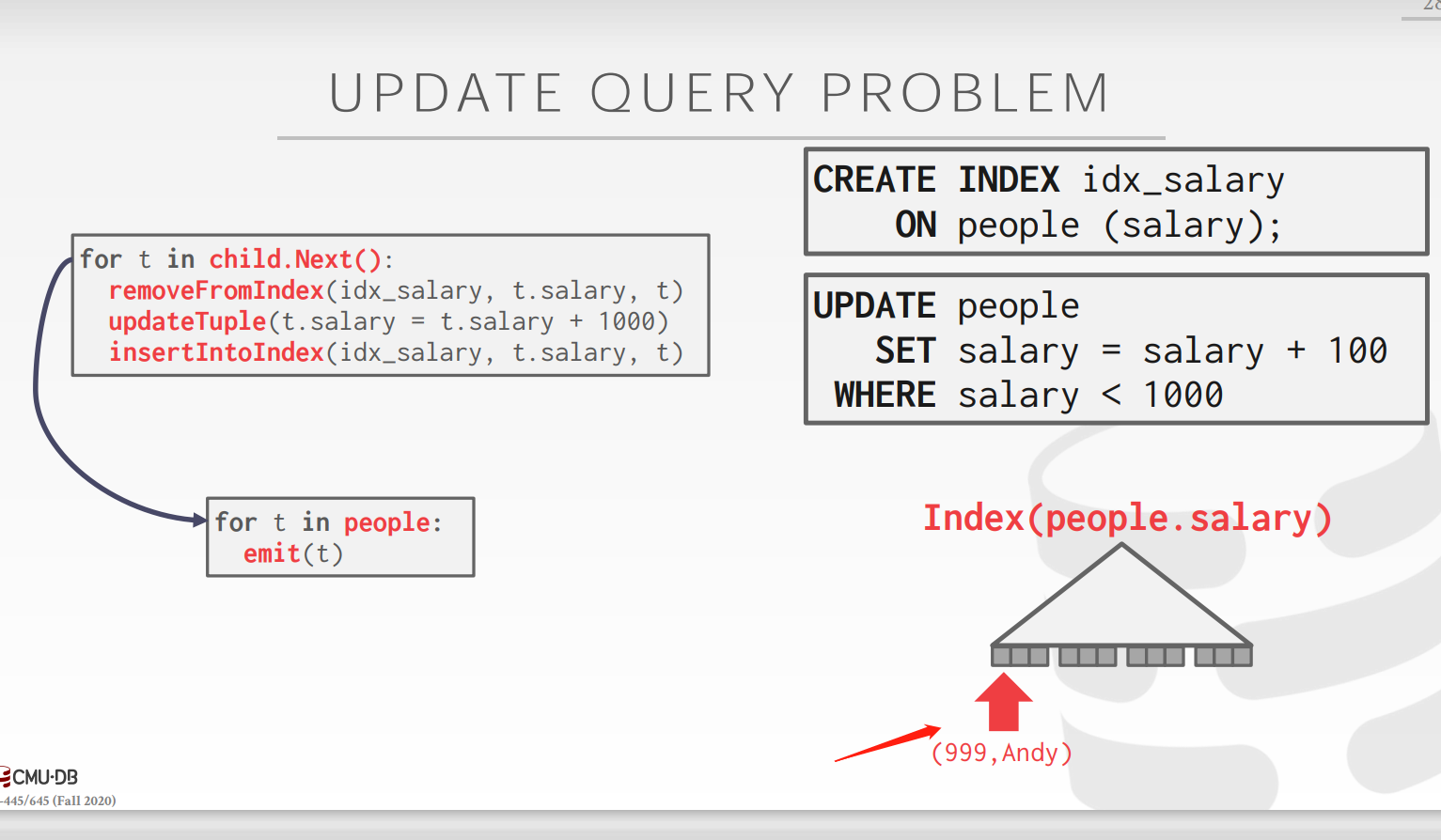
?![]()
对于下面的这个操作,必须要keep track of previously seen tuples不然此处Andy的工资会被加两次100![]()

Expression Evaluation
DBMS将WHERE子句表示一个表达式树
但是对于下面这种expression会存在执行效低的问题,因为需要多次计算? + 1? 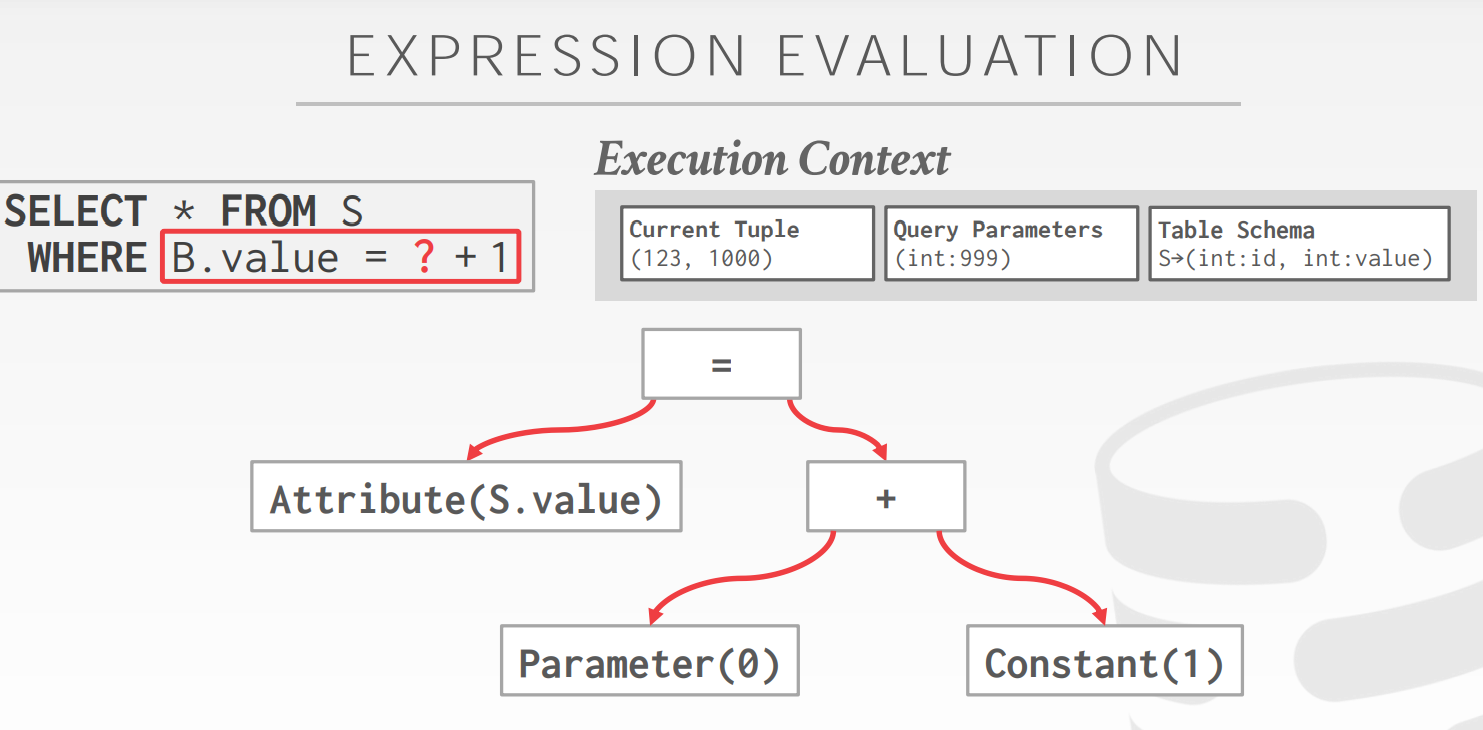
?1 + 1
并行Query Plan
query plan in parallel的好处:
TCO?应该就是花销
Parallel vs Distributed Databases
区别:

Process Model
DBMS的process model还定义了,如何使得系统能够处理来自多用户应用的并发请求
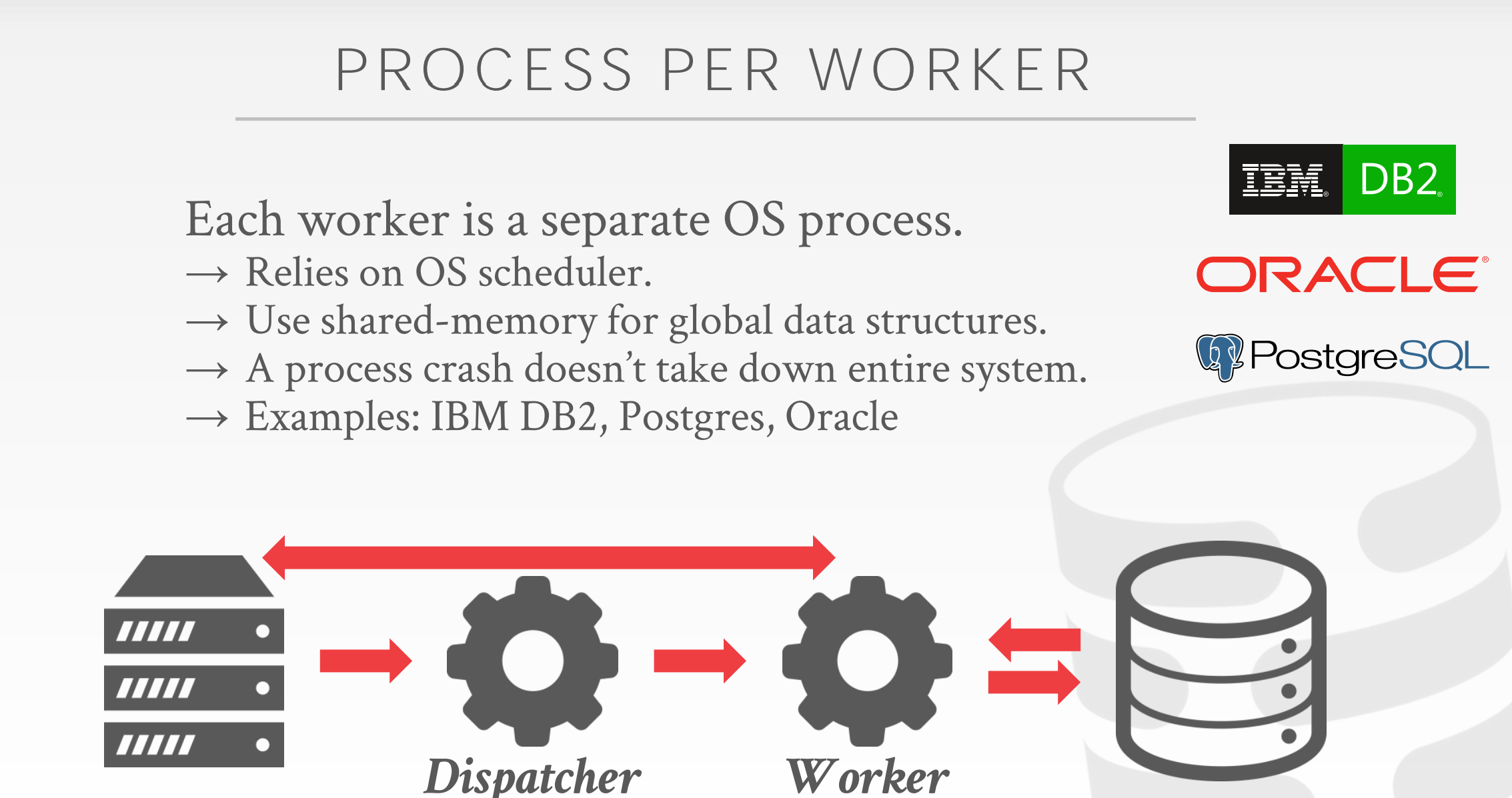
Process per DBMS Worker
- 如果每个worker是一个process,那么它们之间的协同合作需要依赖于OS的调度
- 如果worker之间需要交换数据,那么为它们开辟一段共享内存,其中存放global data structure
- 一个worker出问题了,并不会使得整个系统崩溃
![]()
Process Pool
把一个Process Pool作为worker的好处是啥?
Thread per Worker
由于pthread的大行其道,Thread per Worker得以流行,postgresql任然使用processe per worker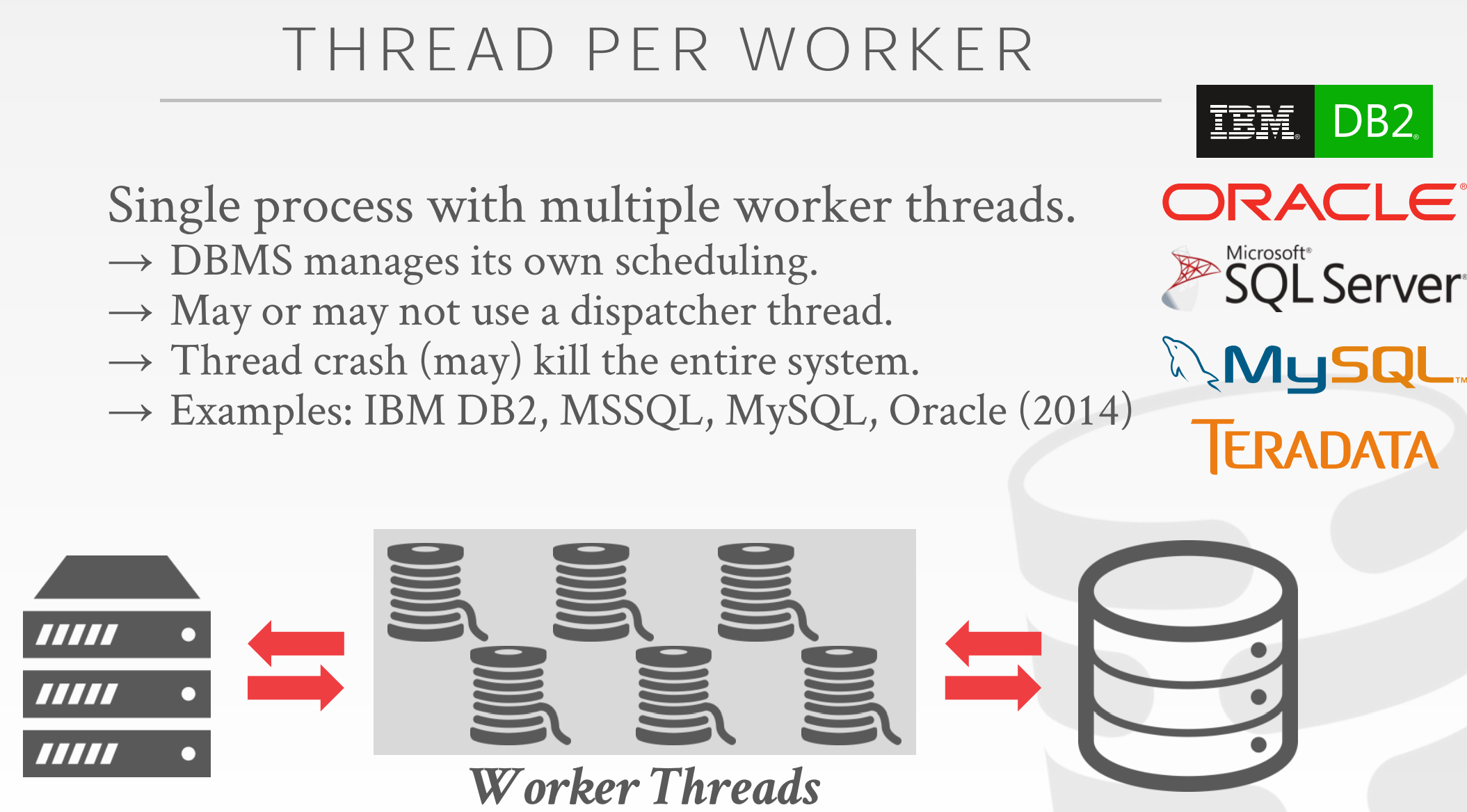
优势:
- context切换开销更小
- 由于在同一个process中,所以thread之间不用管理共享内存
- 但是这并不意味着intra - query parallelism,也就是说query之间是并发的,query内部不是并发
调度
DBMS比OS更懂数据库query plan的执行任务的调度
Inter-Query Parallelism and Intra-Query parallelism
区别:
![]()
- Inter-Query Parallelism:如果是query之间需要write,那么便涉及concurrent control
![]()
- Intra-Query parallelism,这二者有什么具体例子吗?
![]()



Intra-Query parallelism
以一种consumer/producer的范式工作
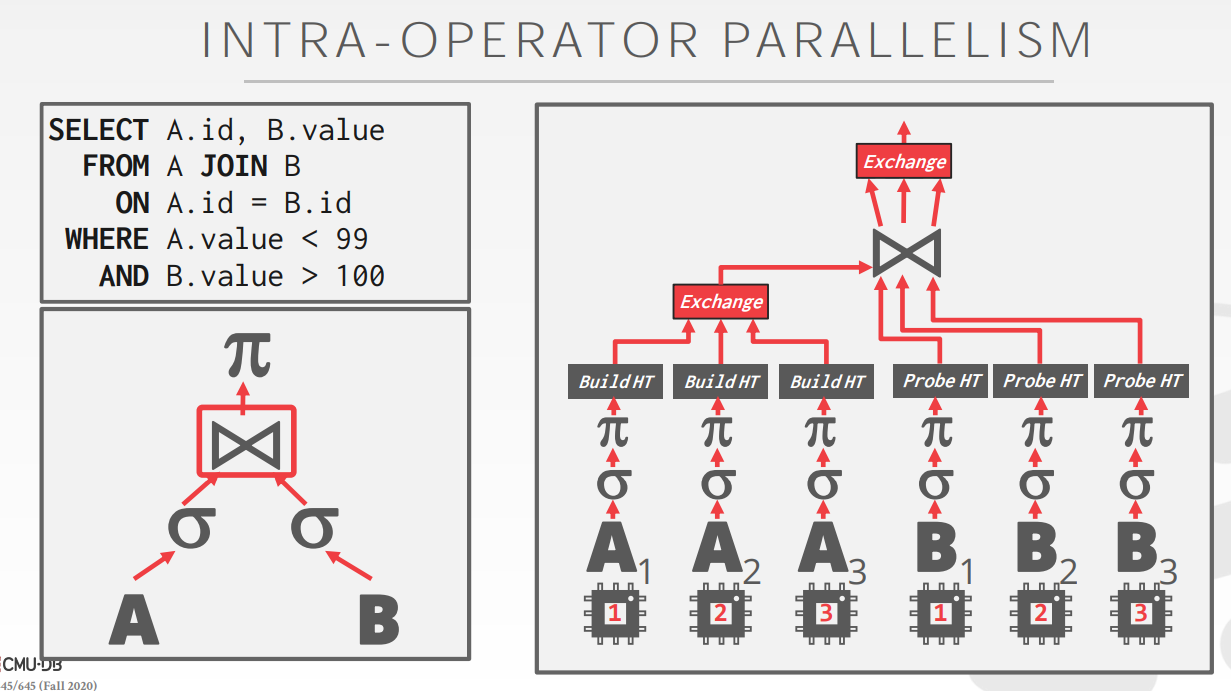
- Intra-Operator Parallelism (Horizontal)
![]()
![]()
![]()
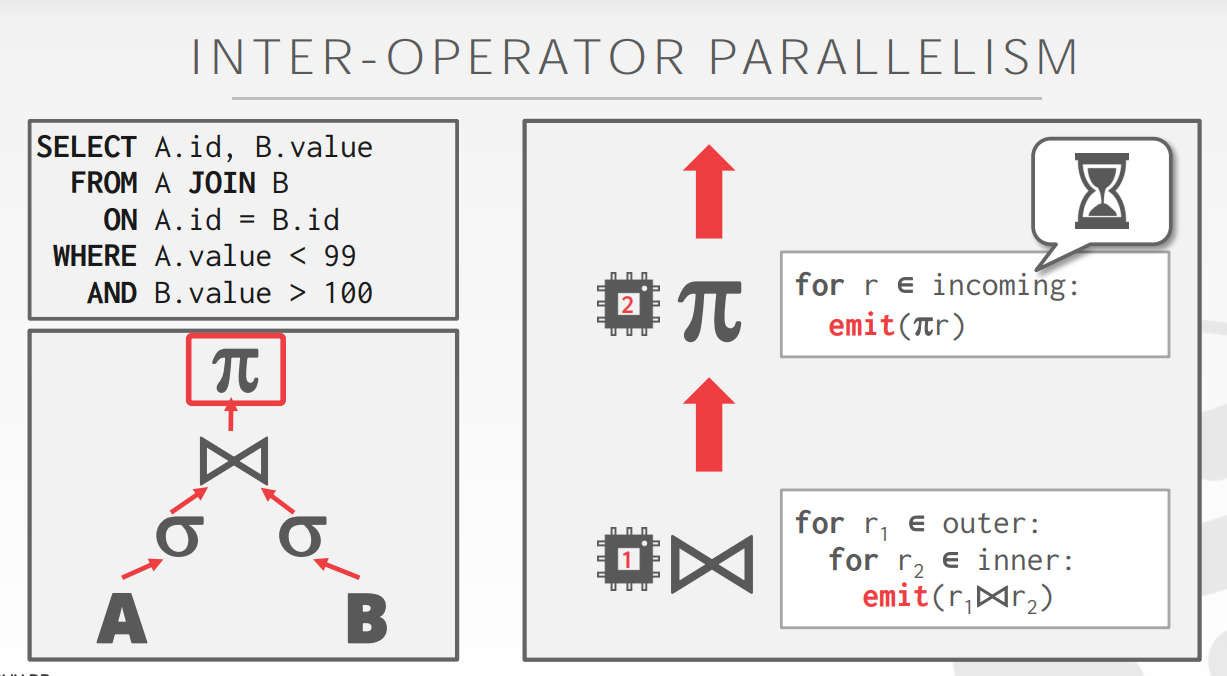
- Inter-Operator Parallelism (Vertical)
运用缓冲的管道并行![]()
![]()
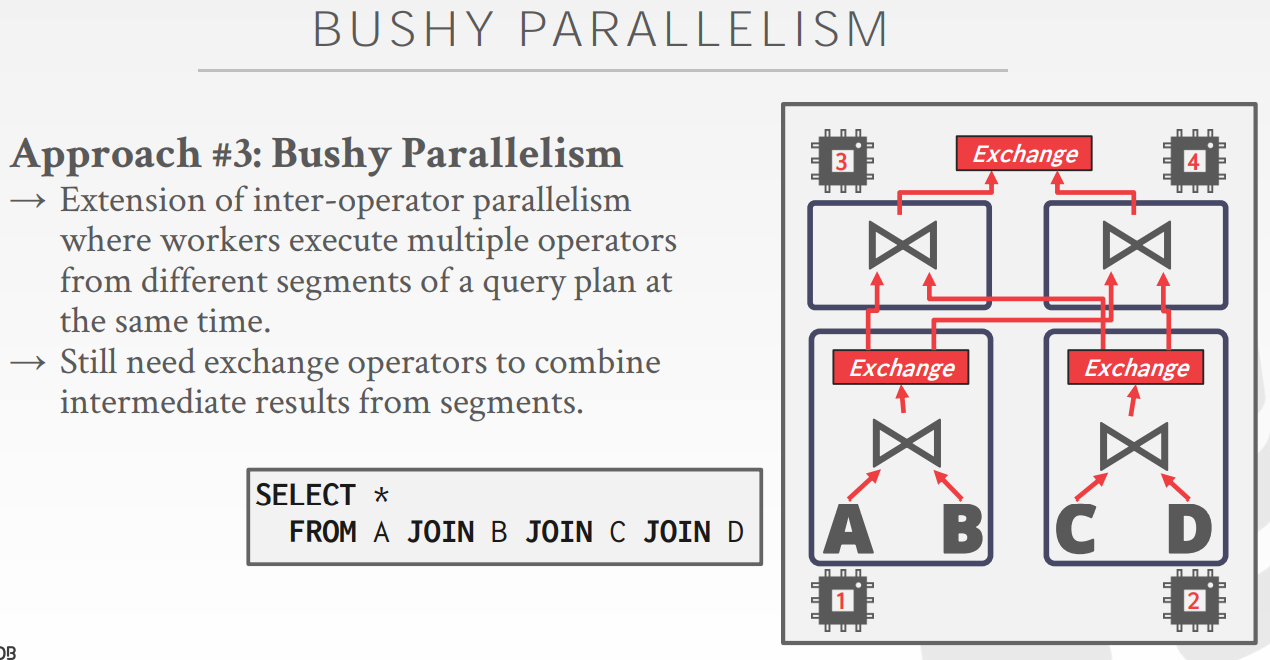
- Bushy Parallelism
Inter-Operator Parallelism(Horizontal)与Inter-Operator Parallelism (Vertical)的结合![]()



I/O Parallelism
为什么会更糟?因为随机的存取对与disk storage不友好
Multi-Disk Parallelism
这个是配置OS/硬件,对于DBMS是透明的
Partitioning
如何切开数据库
Database Partitioning
按照database的粒度切开
Logical Partitioning
把table切开,分别放到多个disk,数据库的划分需要处理好shared log file


 浙公网安备 33010602011771号
浙公网安备 33010602011771号