CMU15445 Lab 2 B+TREE & homework2 index
homework2 index
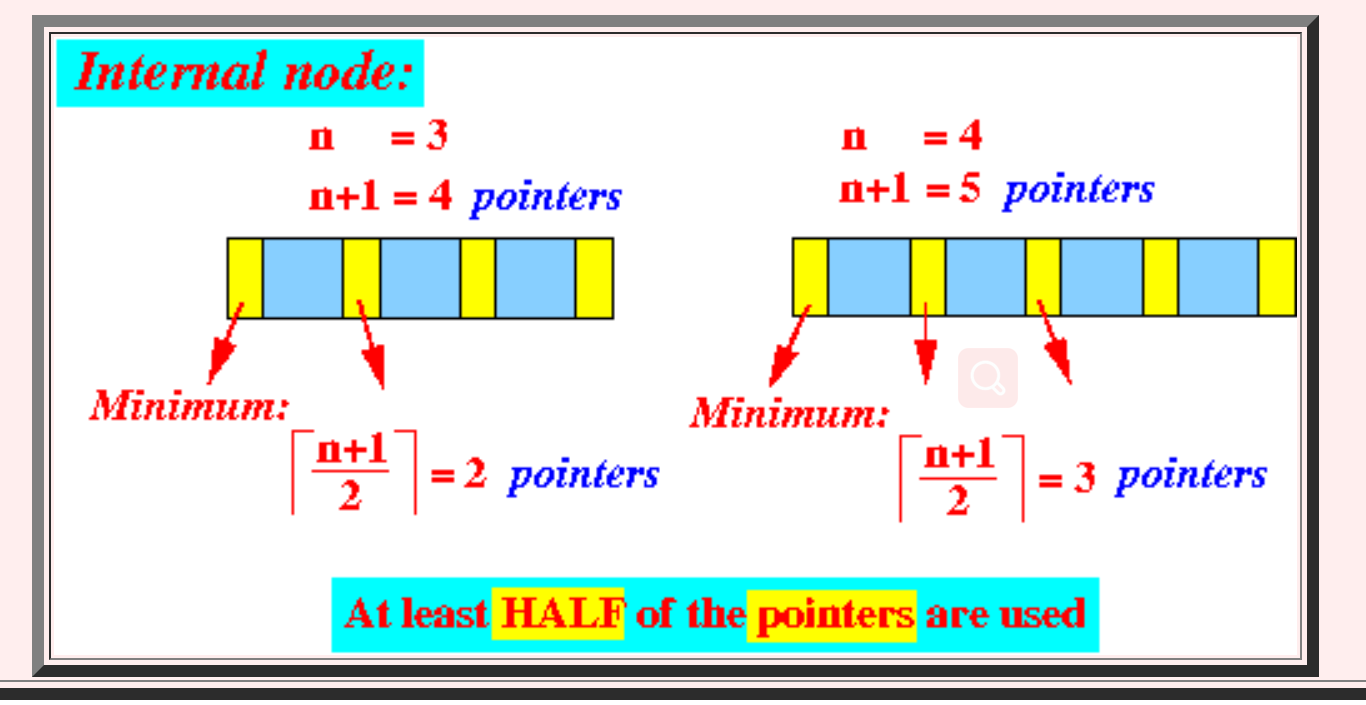
假设度为n
- leaf node:ceil((n - 1) / 2) <= k <= n- 1,leaf node看的是key的个数,那么对于n = 4的情况,2<= k <= 3
- inner node:ceil(n / 2) - 1 <= k <= n - 1, inner node看的是pointer,那么对于n = 4的情况,1<= k <= 3。图中的n是degree - 1
![]()
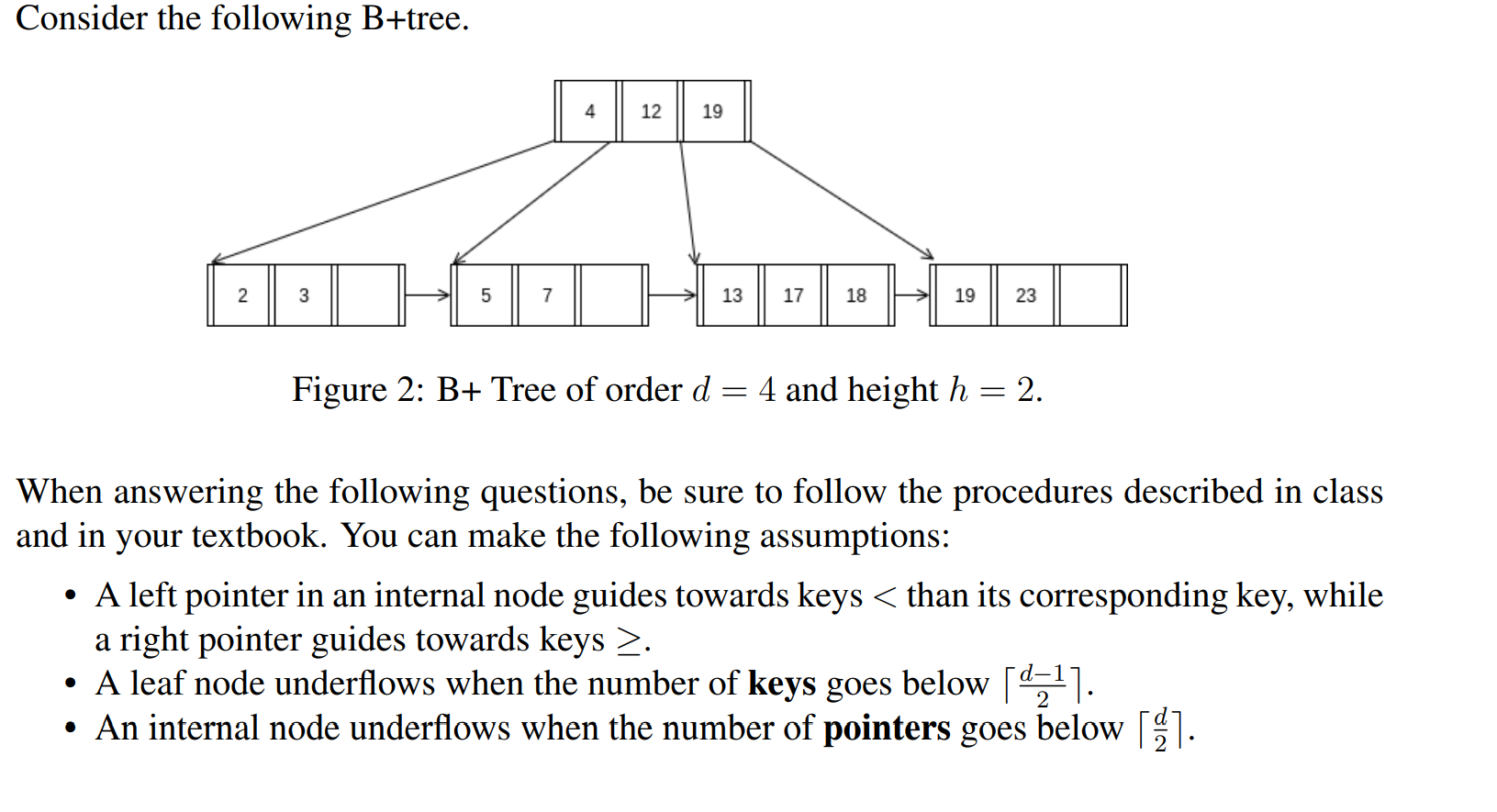
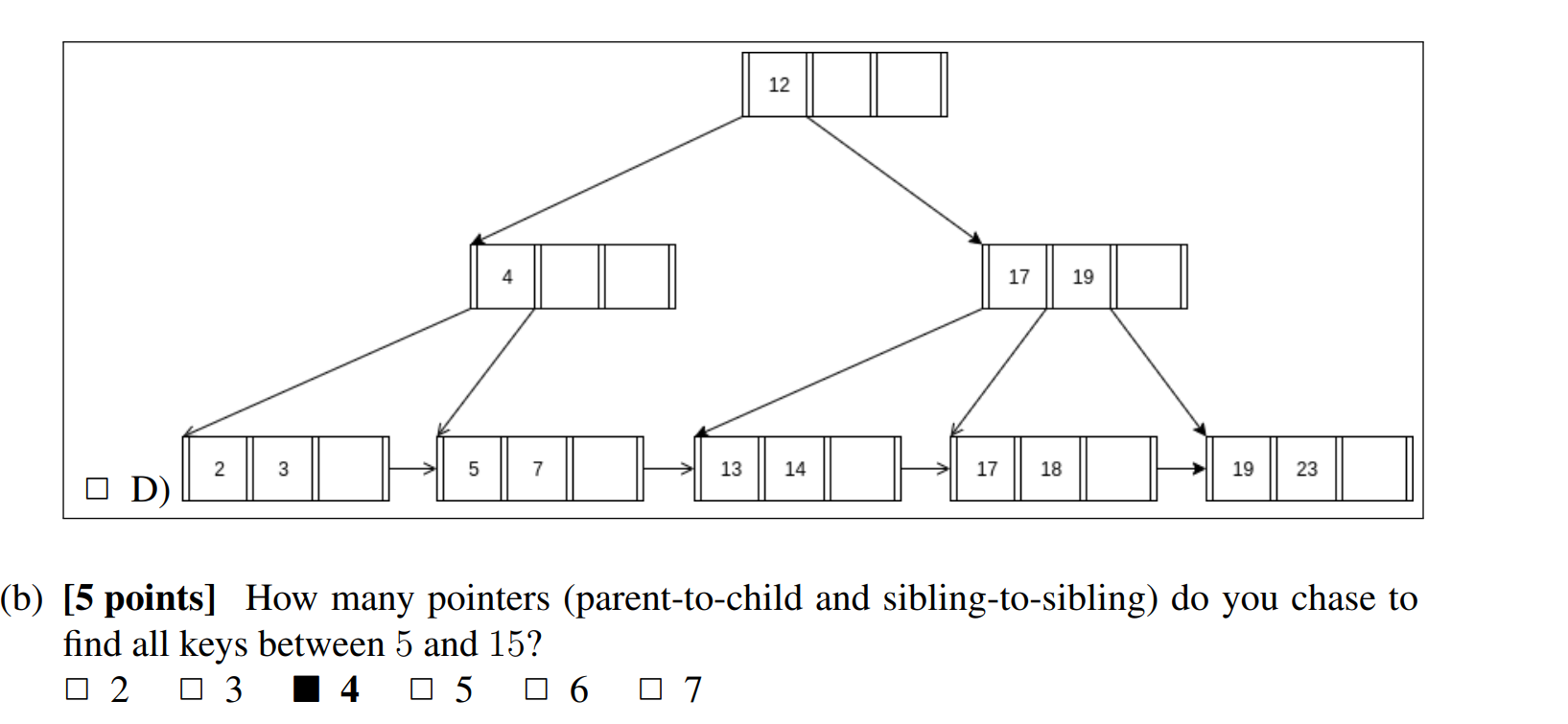
为什么是4个? 为需要遍历到右边的17,才能够知道没有15
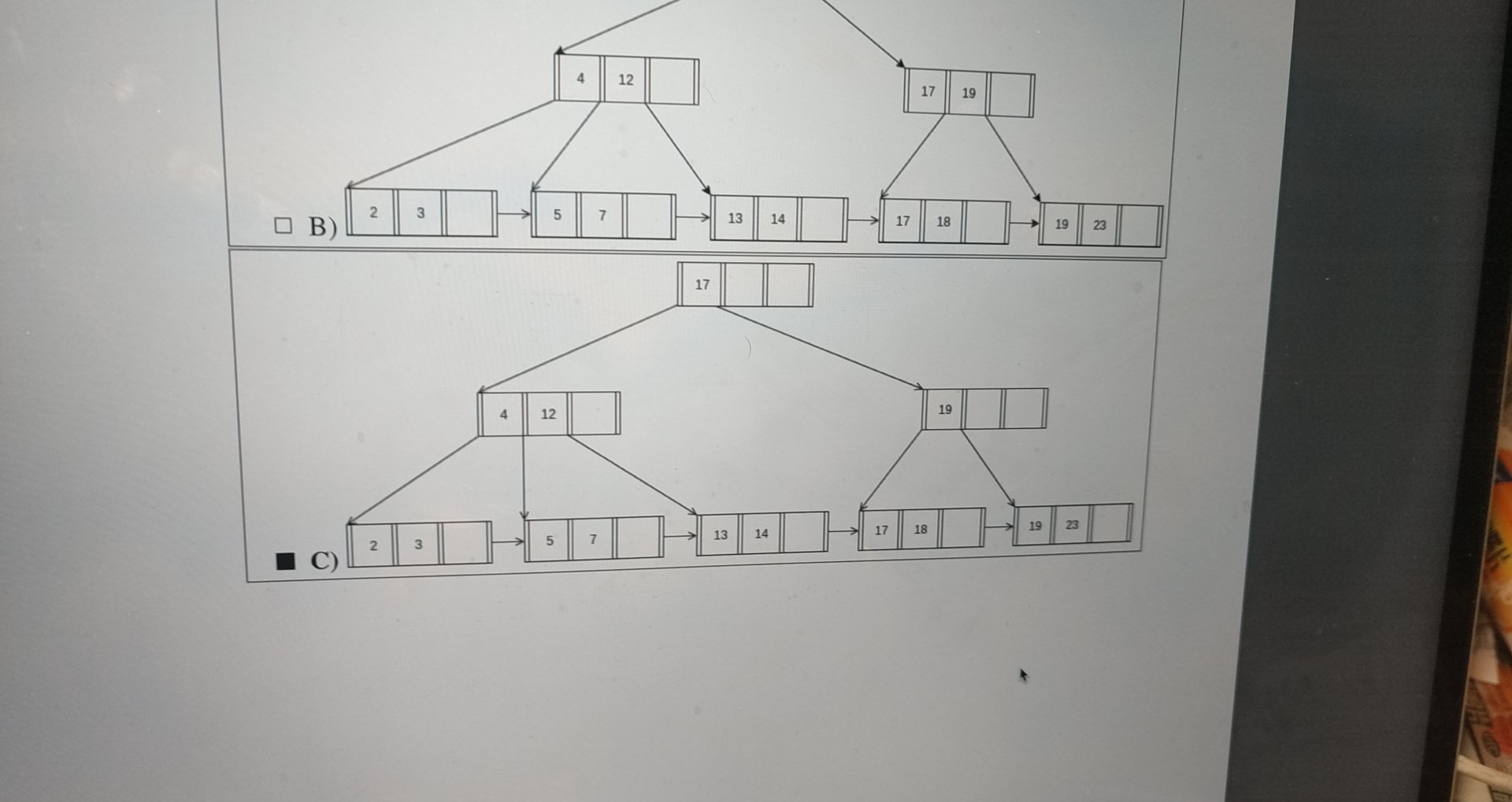
上面的树删除23并不能得到下面的树
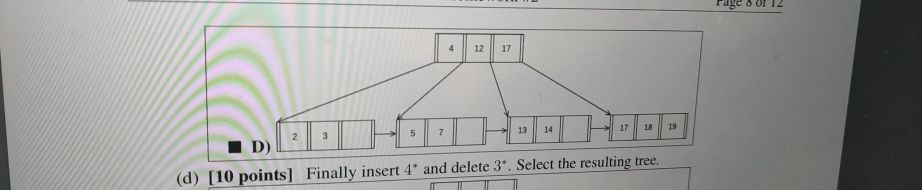
答案应该是下面
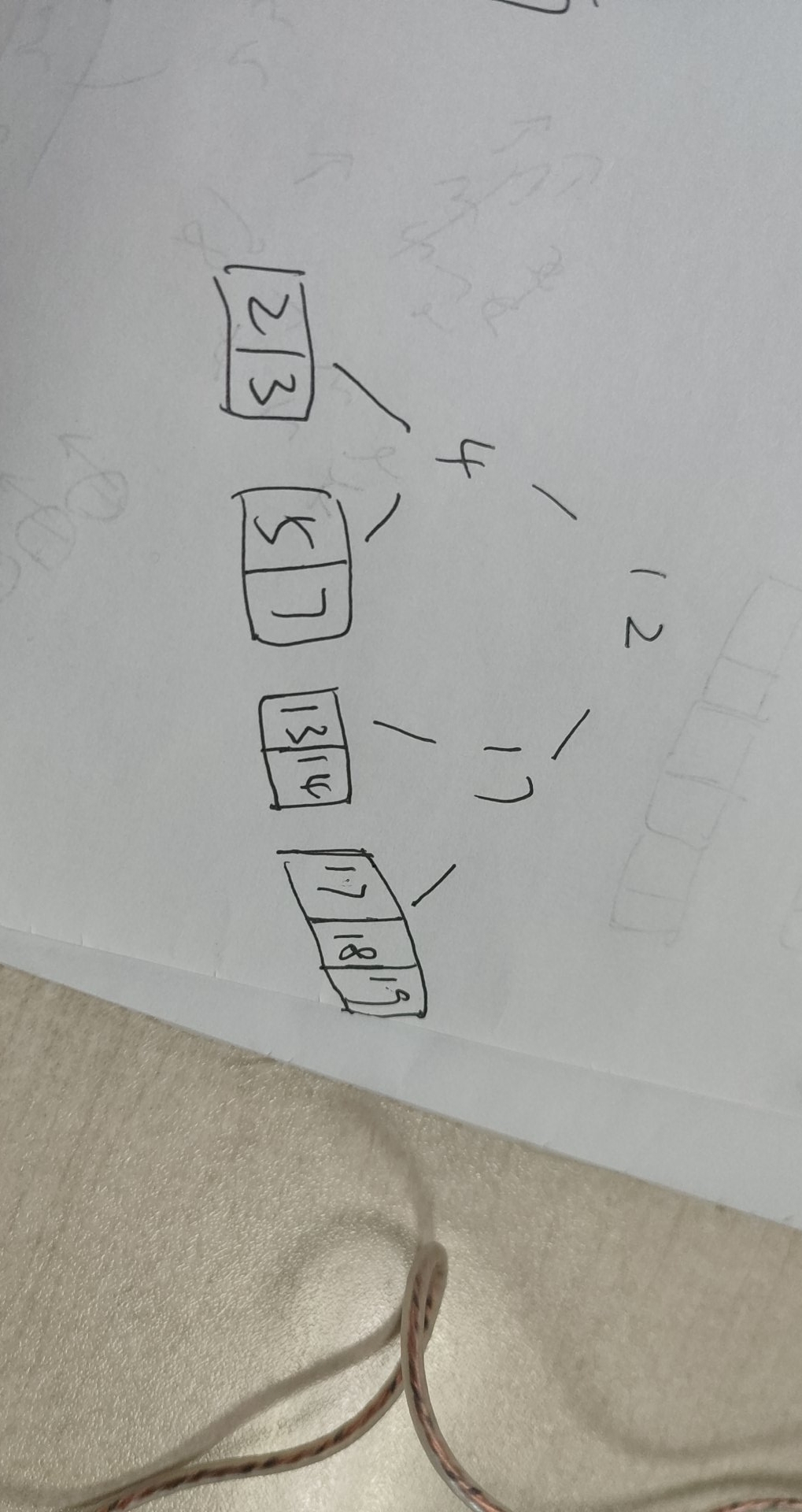
这啥意思?

还有这个?

时间
2022.02.26 - 2022.03.01
实验说明
-
B+ Tree内部节点指引搜索,叶子节点能够指向实际的数据entry
-
B+ Tree的正确性依赖与Buffer Pool的实现
-
CHECKPOINT #1
- TASK #1 - B+TREE PAGES:需要实现三个B+ Tree的Page class:
- B+ Tree Parent Page:不论是internal page 还是 leaf page,它们都继承于parent class,也就是它是个大父类,它只保留子类们所共有的信息:
![]()
- B+Tree Internal Page:,internal page不存真实数据,(对于m-way迭的B+ Tree)但是它会存储m个key与m + 1个孩子指针(在这里是page_id), 对于这句话的解释是?
![]() ,假设一个internal node中有三个child pointer,那么这时需要三个key,但是会有一个key是无效的,比如这里(猜测child pointer 与 key应该是存成了一个pair)
,假设一个internal node中有三个child pointer,那么这时需要三个key,但是会有一个key是无效的,比如这里(猜测child pointer 与 key应该是存成了一个pair)![]()
- B+Tree Leaf Page:一个Leaf Page有m个key与m个value entries,使用RID class来存储value entry,(这里存的是rid,那么lab2中的B+Tree是非聚簇索引),每个leaf/internal page对应与Buffer Pool中的Page(也就是Frane)对象中的data_成员变量
![]() 不过Sibling Pointers存在哪里?存在leaf node的meta data中,也就是
不过Sibling Pointers存在哪里?存在leaf node的meta data中,也就是next_page_id_
- B+ Tree Parent Page:不论是internal page 还是 leaf page,它们都继承于parent class,也就是它是个大父类,它只保留子类们所共有的信息:
- TASK #2.A - B+TREE DATA STRUCTURE (INSERTION & POINT SEARCH):lab2中的B+ Tree并不存在重复的key,如果要插入重复的key,不执行并且返回false
![]() 这句话啥意思?创建新根
这句话啥意思?创建新根![]() ,每次插入,如果导致了root_node分裂,那么需要用一个新的page去存储新的root_node,那么root_page_id也就会改变
,每次插入,如果导致了root_node分裂,那么需要用一个新的page去存储新的root_node,那么root_page_id也就会改变
- TASK #1 - B+TREE PAGES:需要实现三个B+ Tree的Page class:
-
CHECKPOINT #2
- TASK #2.B - B+TREE DATA STRUCTURE (DELETION)
- TASK #3 - INDEX ITERATOR
- 把leaf pages组织成linked list,并从单一方向遍历它们
- iterator需要实现
![]()
- TASK #4 - CONCURRENT INDEX
- 将使用latch crabbing实现并发
- 需要实现的是未优化的latch crabbing,也就是不需要使用到悲观锁与乐观锁
![]()

 ,假设一个internal node中有三个child pointer,那么这时需要三个key,但是会有一个key是无效的,比如这里(猜测child pointer 与 key应该是存成了一个pair)
,假设一个internal node中有三个child pointer,那么这时需要三个key,但是会有一个key是无效的,比如这里(猜测child pointer 与 key应该是存成了一个pair)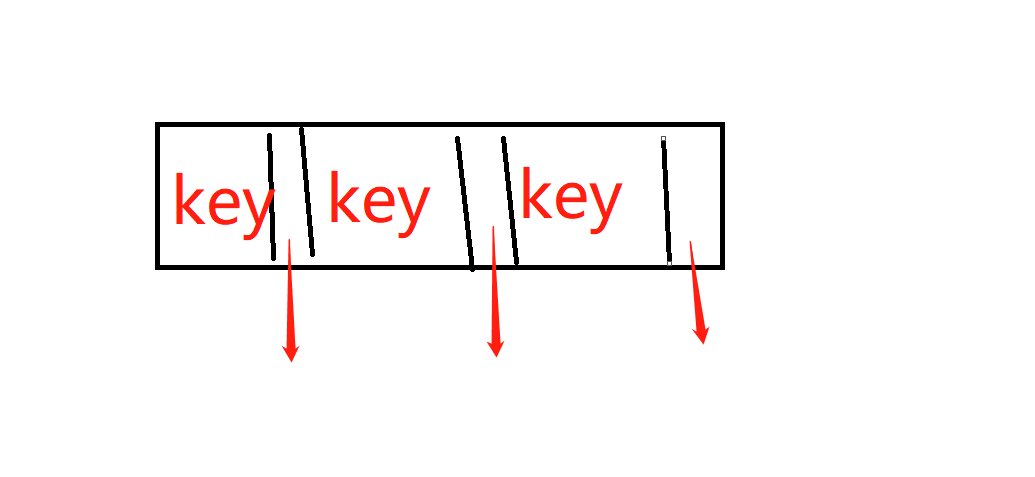
 不过Sibling Pointers存在哪里?存在leaf node的meta data中,也就是
不过Sibling Pointers存在哪里?存在leaf node的meta data中,也就是 这句话啥意思?创建新根
这句话啥意思?创建新根 ,每次插入,如果导致了root_node分裂,那么需要用一个新的page去存储新的root_node,那么root_page_id也就会改变
,每次插入,如果导致了root_node分裂,那么需要用一个新的page去存储新的root_node,那么root_page_id也就会改变
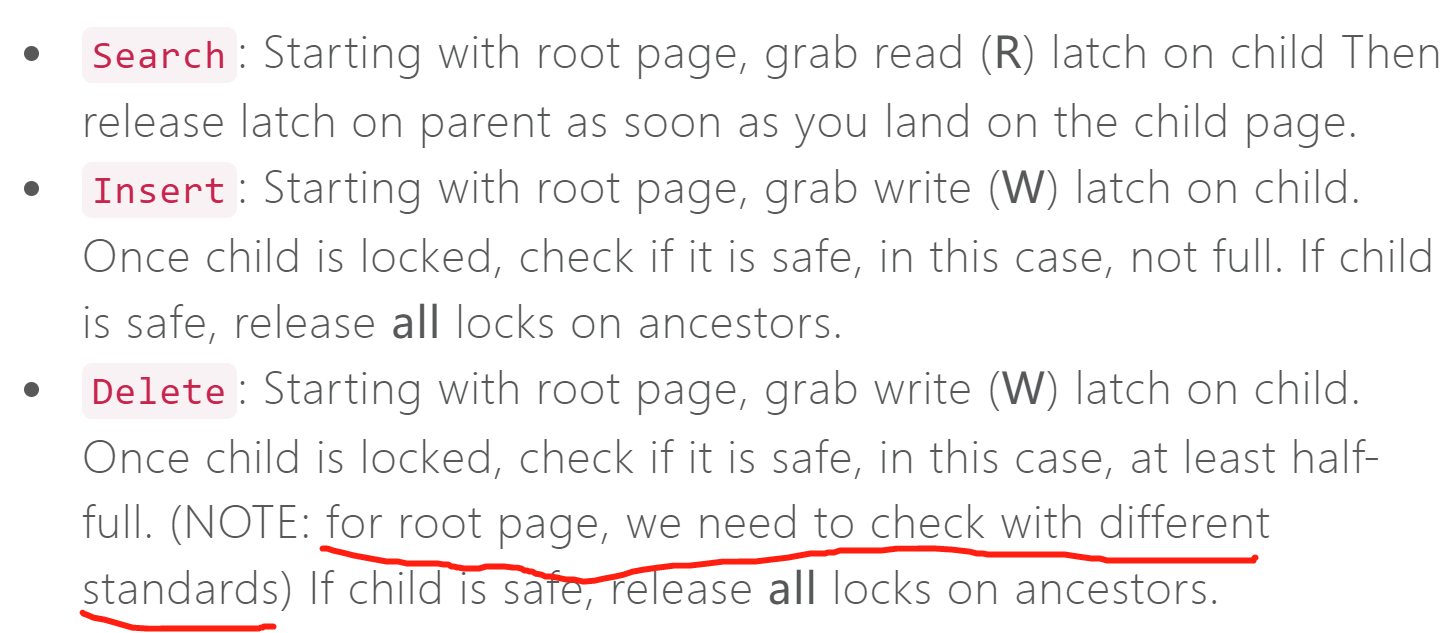
实验要求与提示
- 不能够像之前lab一样只是简单的,在每个操作的开始加锁,每个操作结束解锁,需要正确的实现latch crabbing
![]()
- 释放read-write latch的函数已经实现
- 对于trasaction的处理?FindLeafPage函数原来没有返回值,所以需要添加?
![]()
- latch是加在Page上的
![]()



陷阱(!!!)
- 这个lab不需要实现leaf node scan,对于一个leaf page不能够从sibling获取一个latch时,需要抛出std::exception
- 必须的先释放latch,在unpin一个页
![]()
- 必须要实现top to down地获取锁
- 这个root_page_id到底是啥?
![]()


B+树操作
https://www.mathcs.emory.edu/~cheung/Courses/554/Syllabus/3-index/
Insert
总览
- 首先是将新的k/v插入到leaf node,有可能能会造成溢出,那么需要分裂
- 分裂也会造成internal node的插入,internal node 与 leaf node的插入是不一样的
middle key


流程
假定待插入的k/v被称作x
- 首先找到x所属的leaf node
- 如果该leaf node插入x之后,没有full,那么插入完成
- 否则需要分裂该leaf node
![]()
- 如果该leaf node是root,那么需要创建一个新的root
- 否则需要把k/v = (km, R)插入到parent(L)
![]()
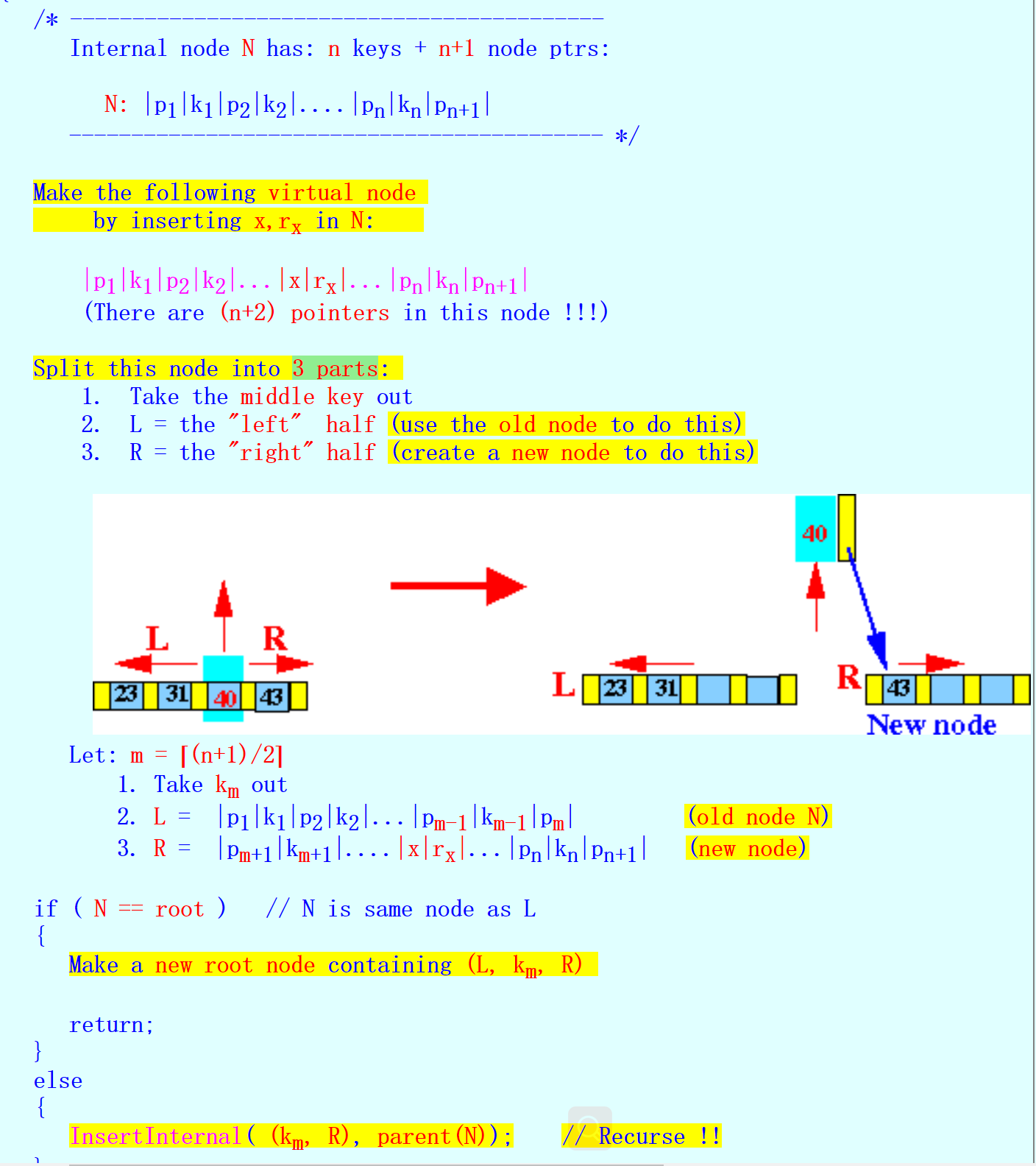
- 对于internal node的插入,主要是将(x, RSub(x))插入到internal node N中,其中x是key,RSub(x)是value
- 如果在internal node中找到合适的位置插入(x, RSub(x))之后,该internal node没有full,那么插入结束
- 否则,
![]()
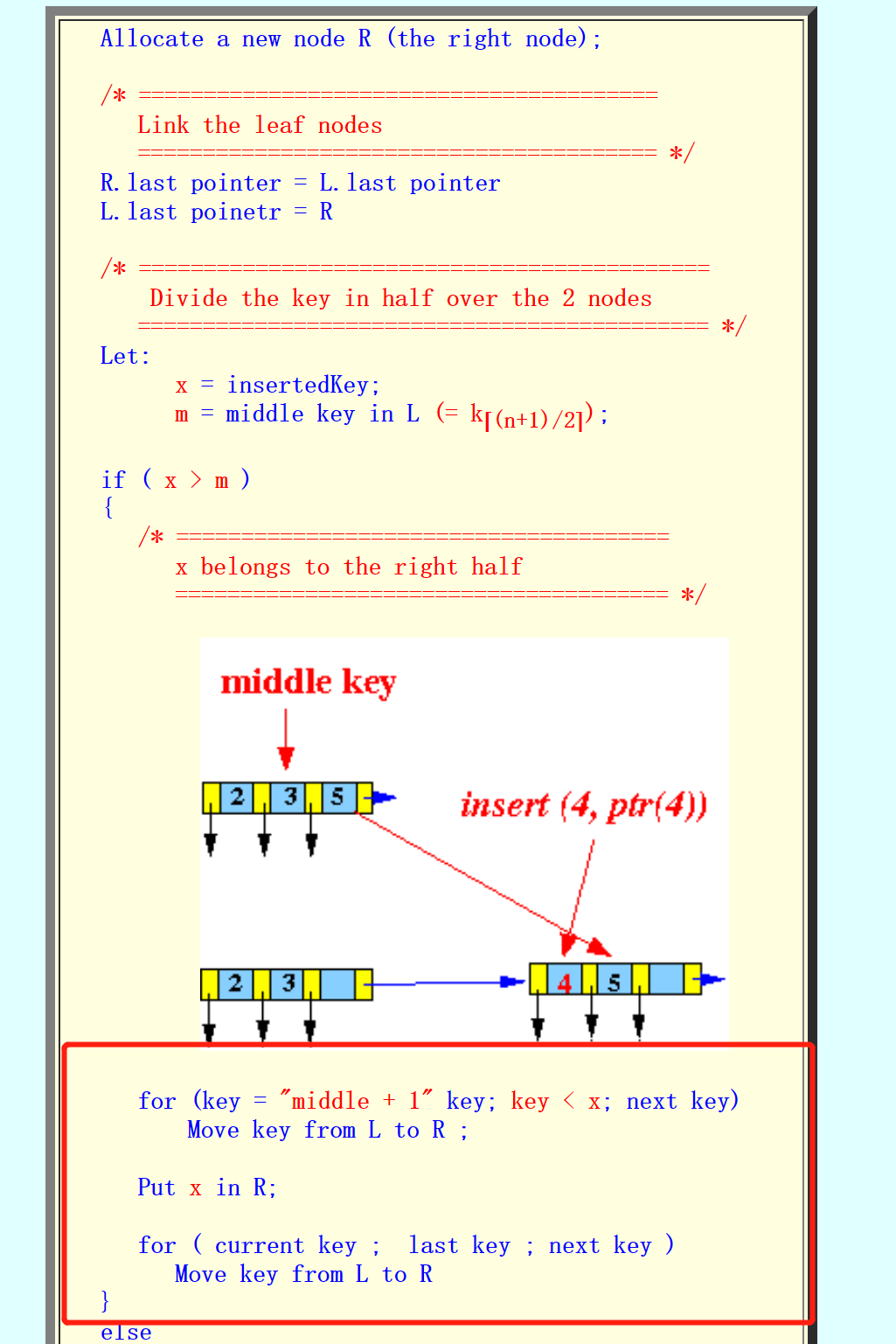
- 对于如何分裂,此处的算法,当待插入k/v,也就是x,如果属于R,先把在R节点中应该属于x的左边的值从L移到R,在把x插入R中,之后把在R中应该在x右边的值从L移到R中
![]()
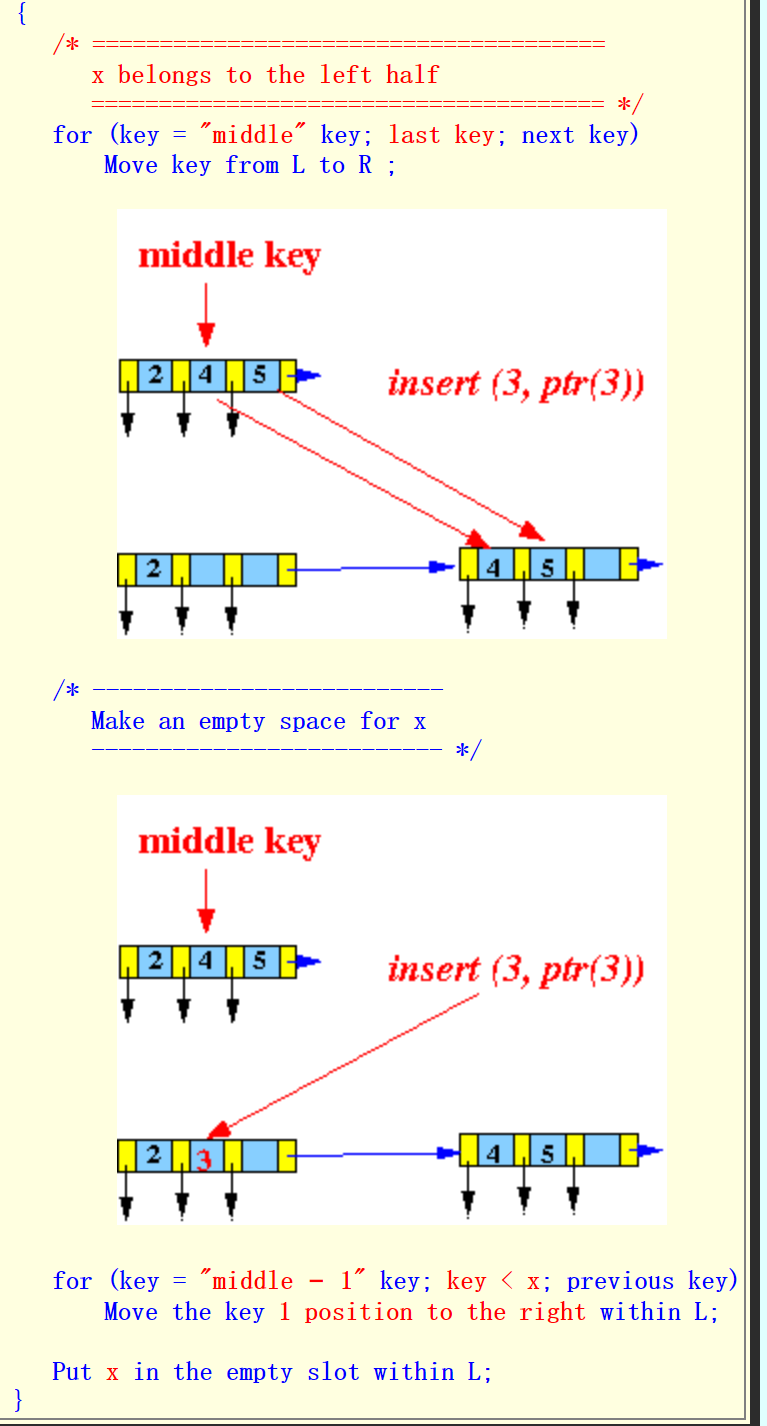
对于x属于L的情况![]()


Delete
假定待删除的key是x
流程
- 首先找到x所属的leaf node,称作L
- 如果没有找到,结束
- 如果找到,那么将x在L中删除,如果删除后,L至少是half full,那么结束
- 否则,需要从左右节点transfer key或者合并
-
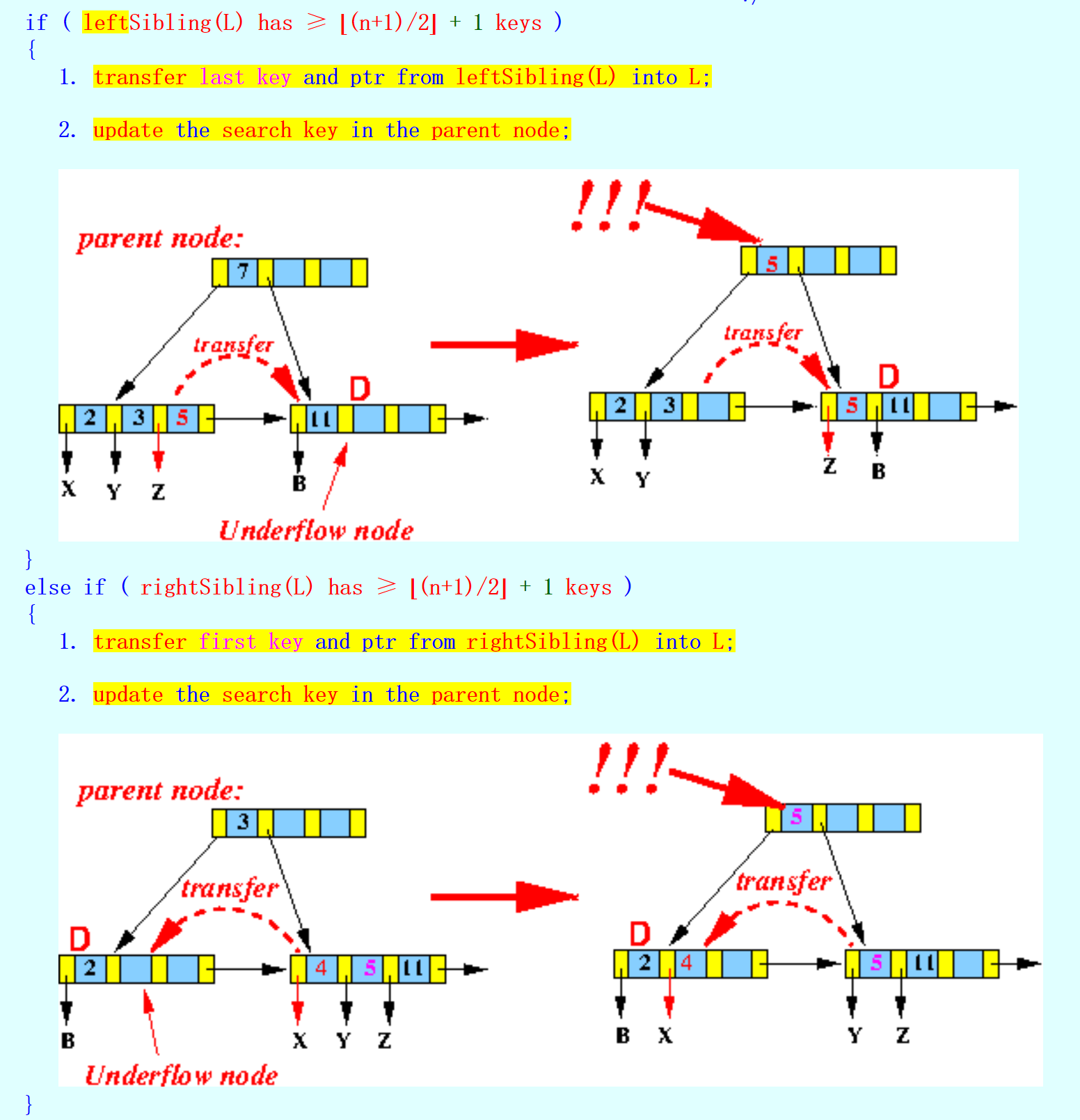
对于transfer,采取先left后right的顺序,注意需要更新parent node中的search key
![]()
-
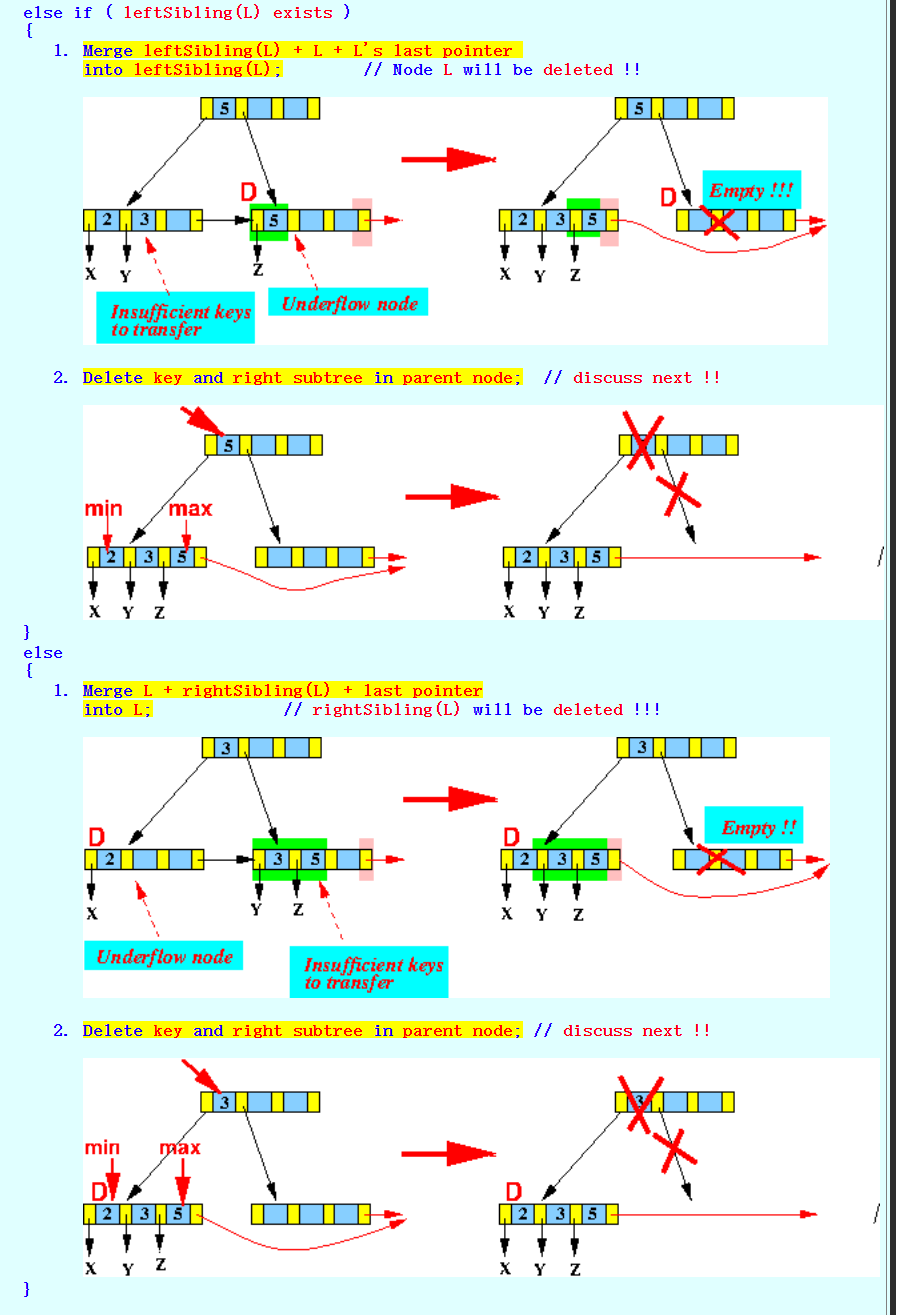
如果左右Sibling都不够,那么需要合并,合并的原则是右边的leaf node的全部节点放到左边的leaf node
![]()
-
- 删除了leaf node中的x之后,如果发生合并的话,那么会涉及internal node节点的deletion,同样有可能会发生合并于transfer。假定需要删除internal node的search key x与它的右子树
- 如果,删除了x,该intenal node至少half full,注意internal node的half full与leaf node的half full不一样,那么结束
- 否则,首先选择transfer或者合并
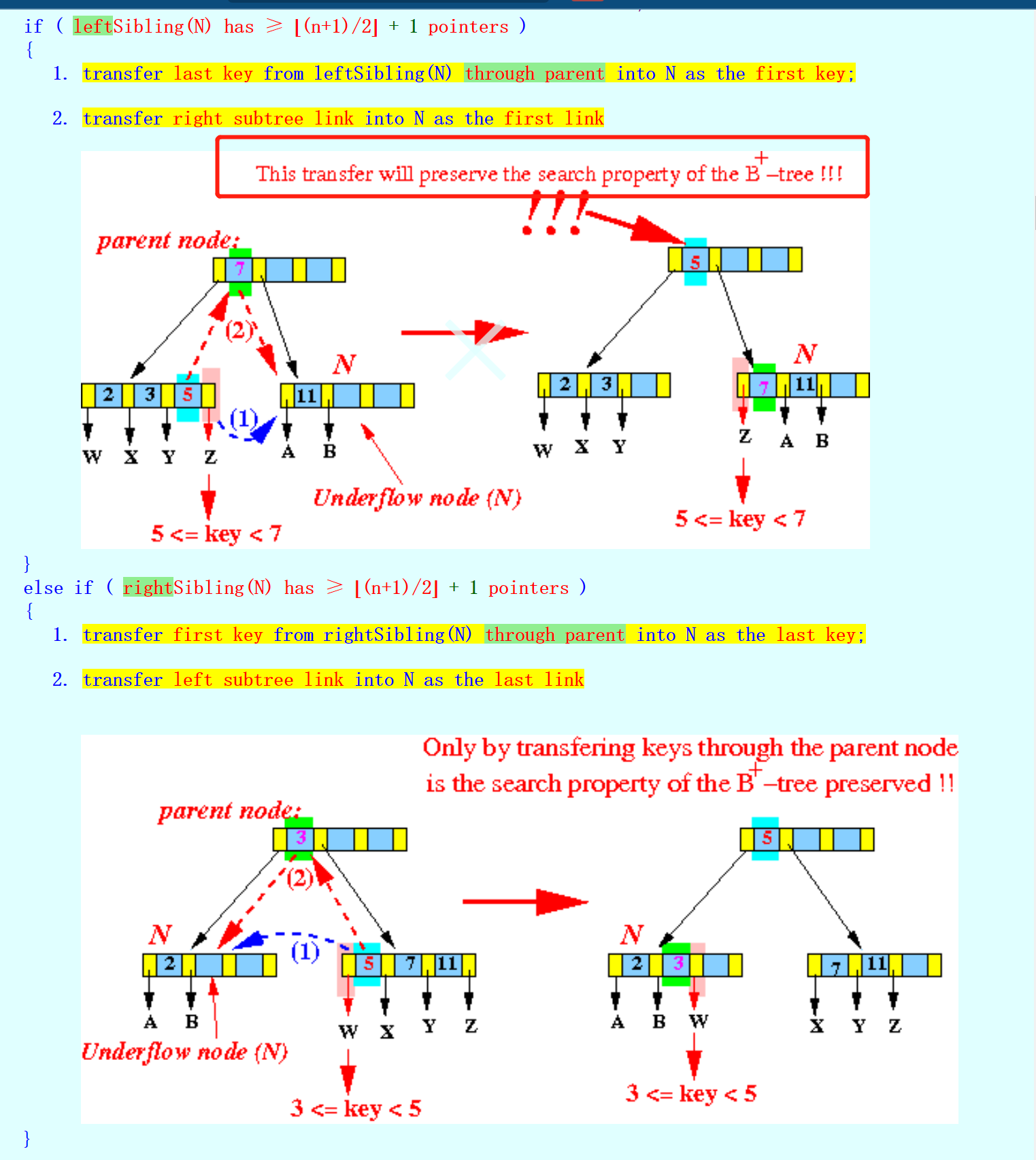
- transfer也是先left后right,需要注意,对于internal node的transfer,不会删除search key
![]()
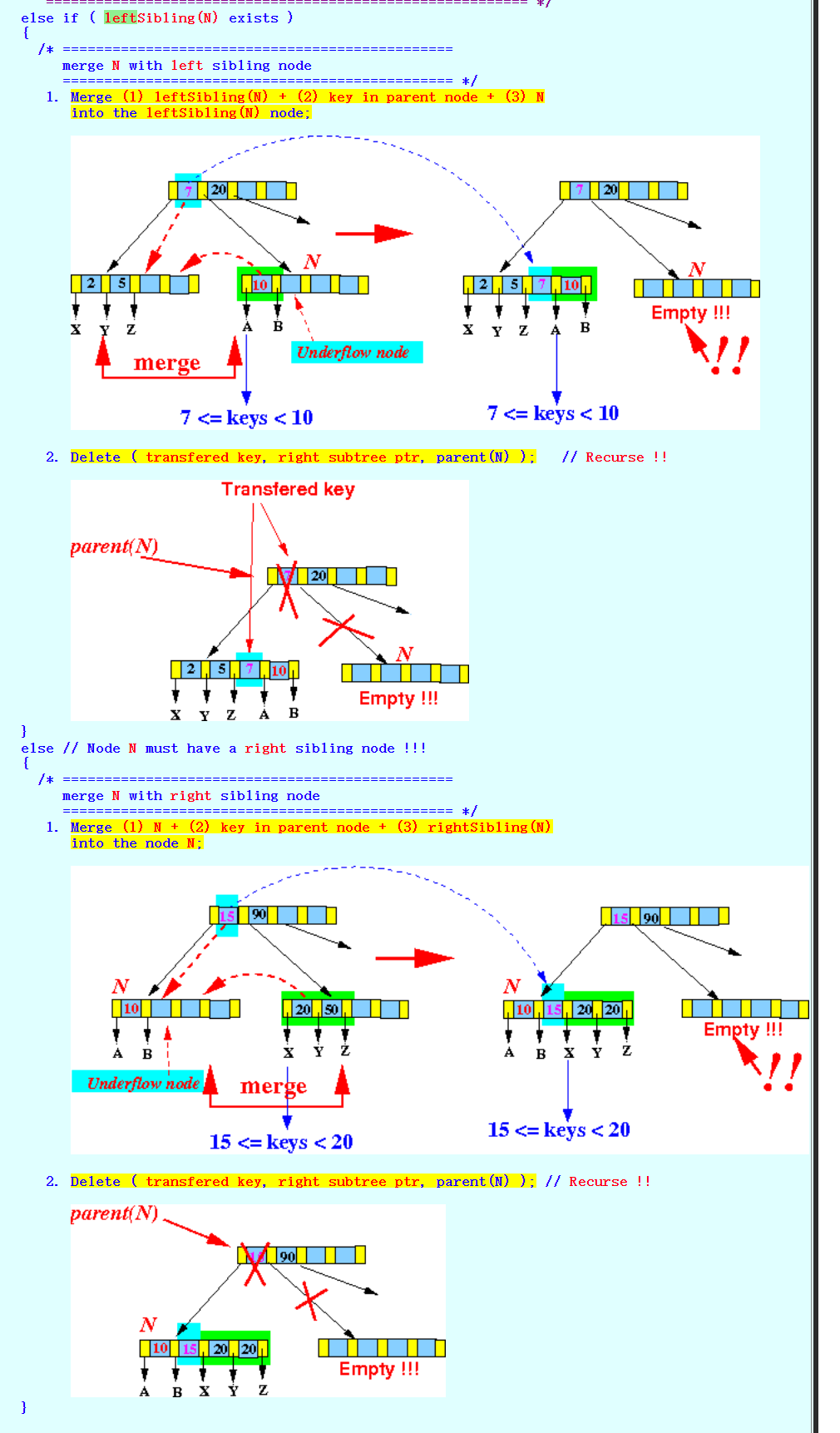
- 合并的原则是右边的leaf node的全部节点放到左边的leaf node,由于合并会使得parent node删除一个key,那么有可能会触发递归的更上一层的合并或transfer
![]()
- transfer也是先left后right,需要注意,对于internal node的transfer,不会删除search key
其他
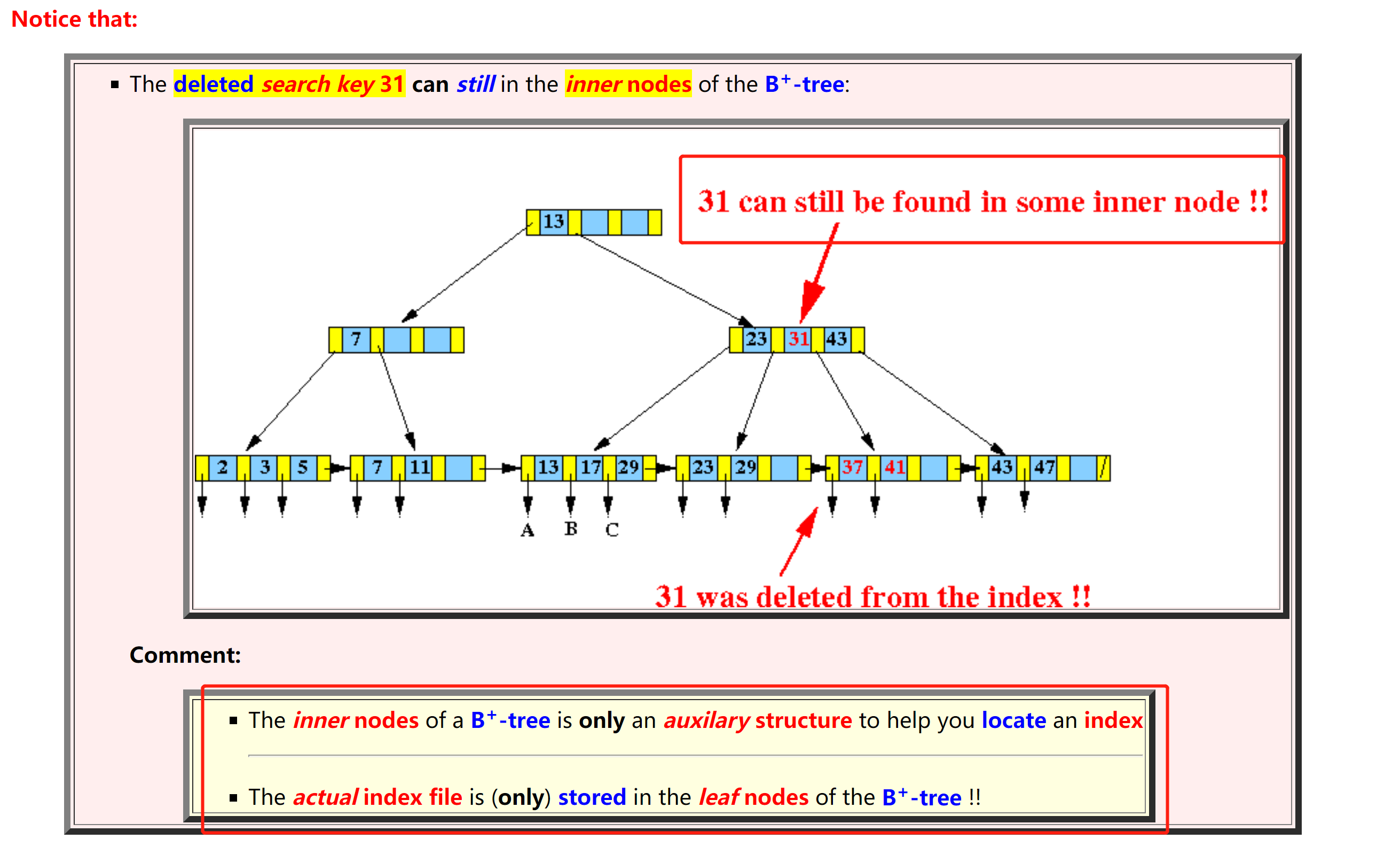
- 可以看到即使在leaf node中把某个key删除了,在inner node任然可以存在这个key
![]()
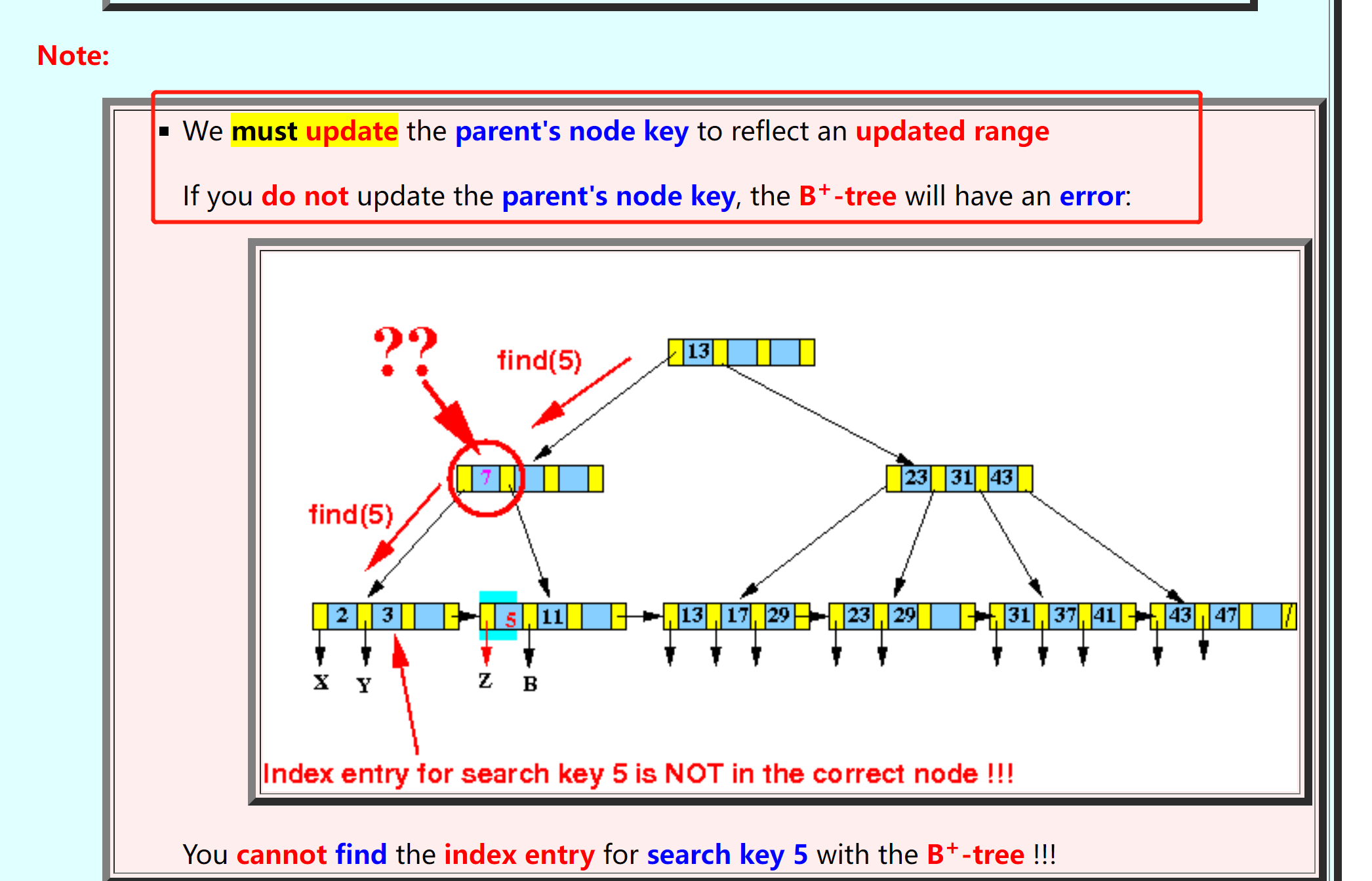
- 当删除一个leaf node中的key时,一定要更新parent中的key,不然会出错
![]()
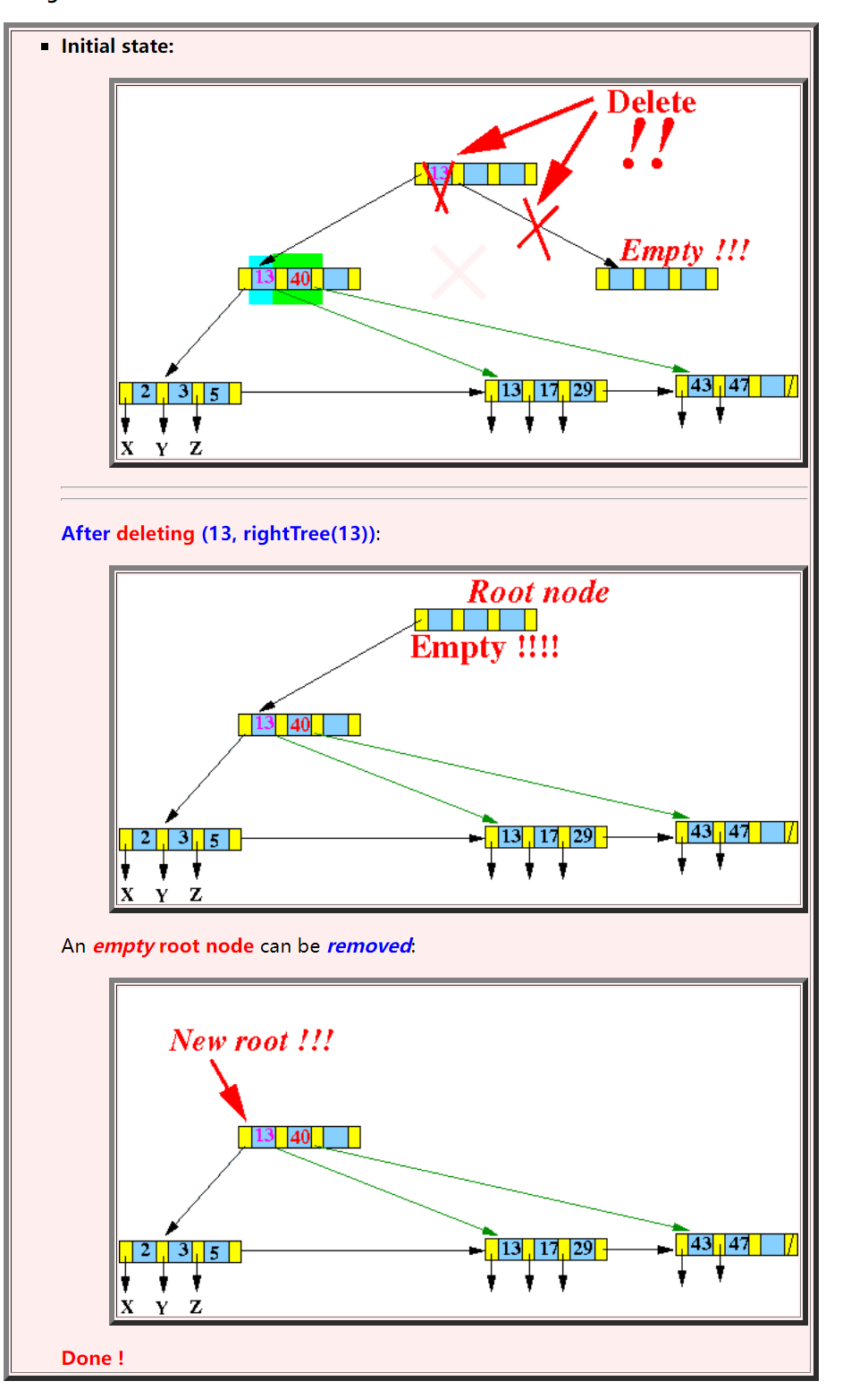
- 在连续的merge之后可能会出现根节点为空的情况
![]()
Search
实现
TASK #1 - B+TREE PAGES
B+Tree Parent Page
- 注意MinSize()的定义
![]()

TASK #3 - INDEX ITERATOR
TASK #4 - CONCURRENT INDEX
这个lab给的互斥🔒的实现是读写公平竞争,关于读者优先与写者优先可以看这个,简而言之,读者优先是设置一个读者队列,而写者优先是设置一个写者队列。
Wlock(),获取写🔒
- 首先查看是否存在其他线程获取了写🔒
- 如果已经有写者在等待,那么需要将该写者放到reader_的等待队列中,也就是说writer_的等待队列中至多只有一个线程?猜测是为了保证公平性,如果把所有的之后的写者放到reader_的等待队列中,那么每次写🔒解锁时,只会唤醒其他写者,那么对读者不公平,后面的读🔒的解锁也巧妙的保证了公平性,也就是新来的写者一定会比后来的读者更早的进入临界区,并且比更早的的读者更晚的进入临界区
- 否则置位写者存在变量,并查看是否存在读者,如果存在那么将该写者放入writer_的等待队列中
/**
* Acquire a write latch.
*/
void WLock() {
std::unique_lock<mutex_t> latch(mutex_);
while (writer_entered_) {
reader_.wait(latch);
}
writer_entered_ = true;
while (reader_count_ > 0) {
writer_.wait(latch);
}
}
/**
* Release a write latch.
*/
void WUnlock() {
std::lock_guard<mutex_t> guard(mutex_);
writer_entered_ = false;
reader_.notify_all();
}
/**
* Acquire a read latch.
*/
void RLock() {
std::unique_lock<mutex_t> latch(mutex_);
while (writer_entered_ || reader_count_ == MAX_READERS) {
reader_.wait(latch);
}
reader_count_++;
}
/**
* Release a read latch.
*/
void RUnlock() {
std::lock_guard<mutex_t> guard(mutex_);
reader_count_--;
if (writer_entered_) {
if (reader_count_ == 0) {
writer_.notify_one();
}
} else {
if (reader_count_ == MAX_READERS - 1) {
reader_.notify_one();
}
}
}
- 定义操作的枚举类,来处理并发
![]()
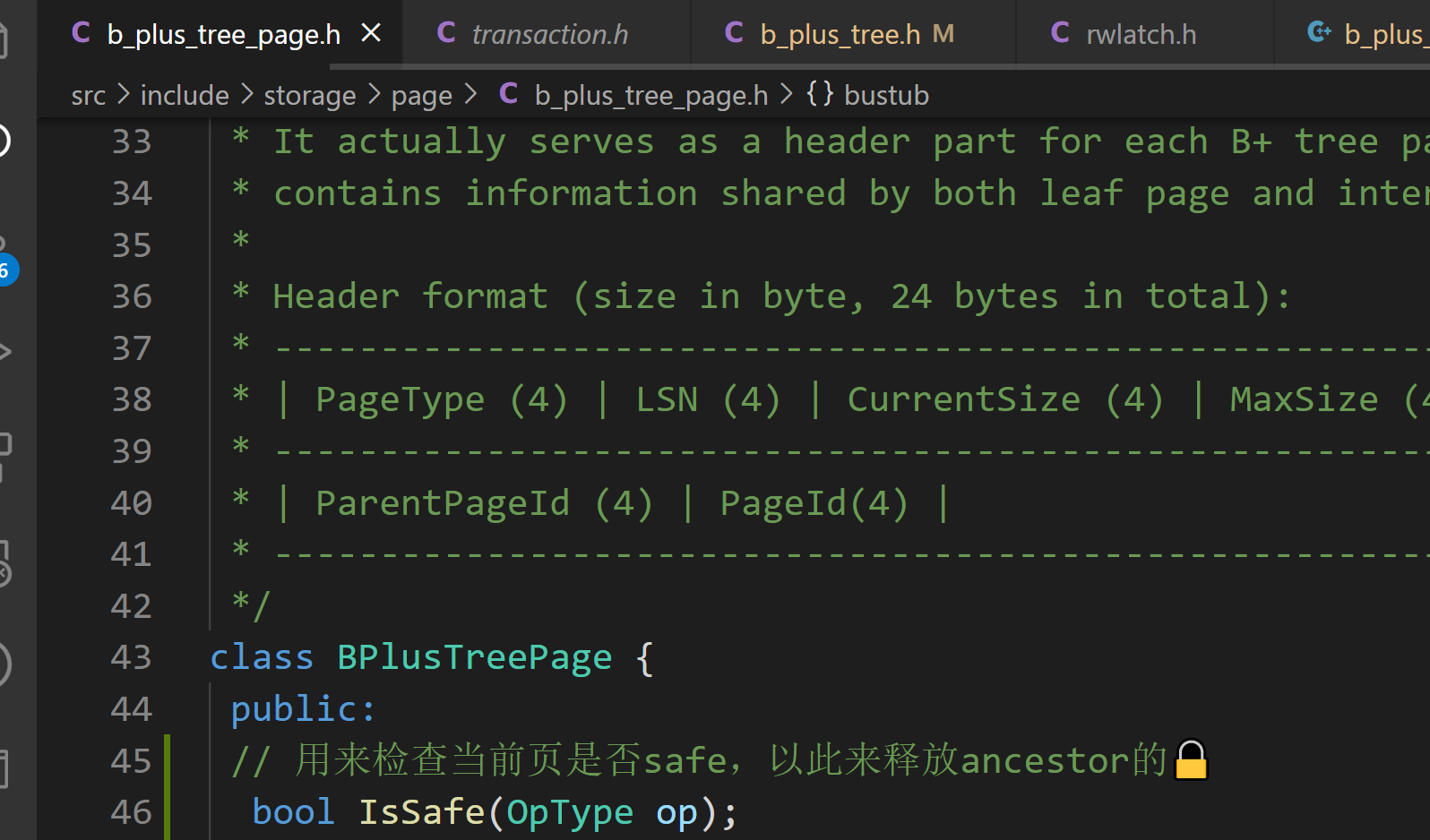
- 用来检查当前页是否safe,以此来释放ancestor的🔒
![]()
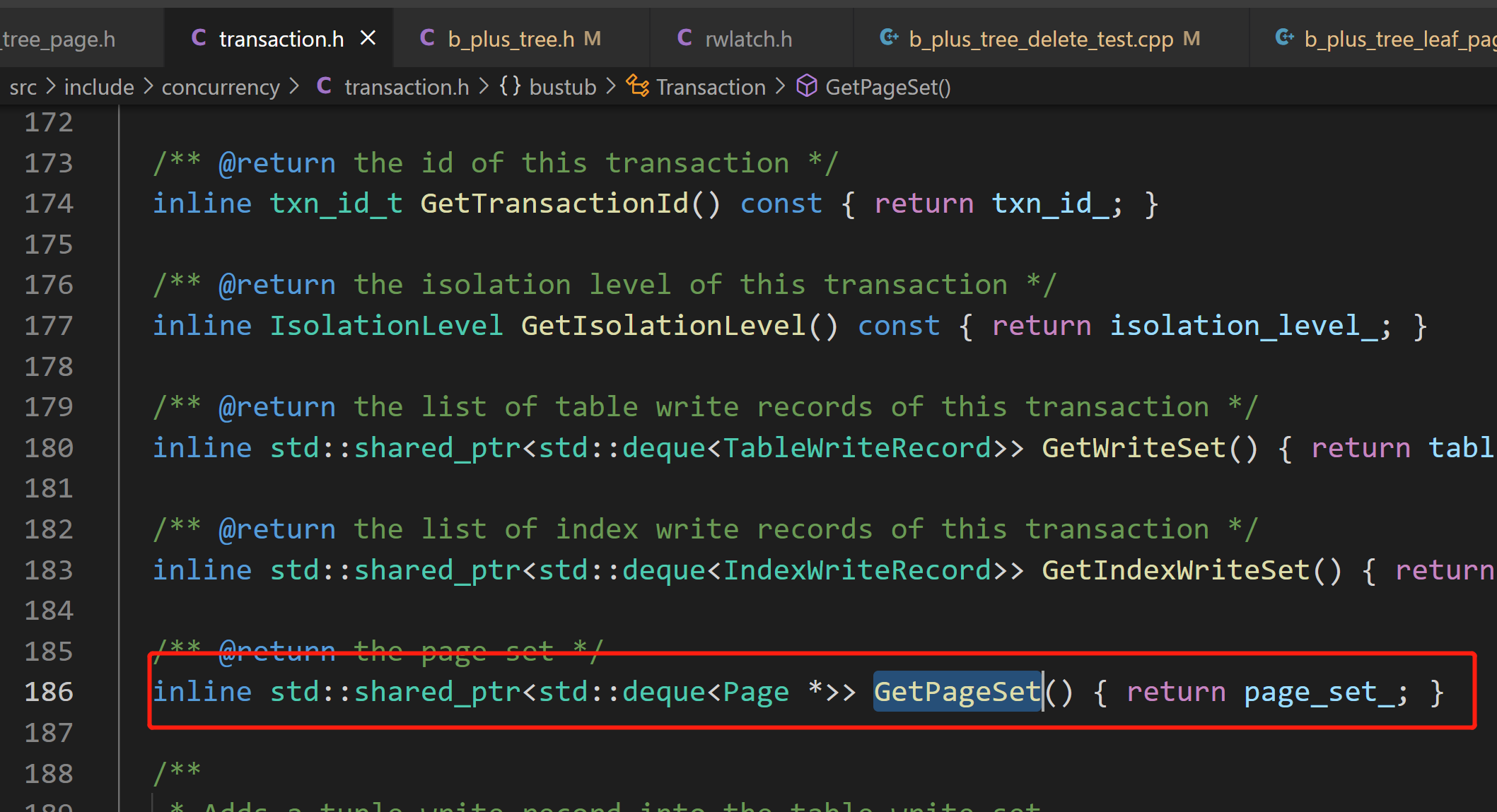
- 这个函数用来获取一个transaction访问过的page
![]()
- 为了处理这段话,需要设置一个函数先解锁再unpin,因为如果还没解🔒,就先Unpin,那么
该page有可能会被刷会磁盘?如果提前刷入磁盘,那么该page在buffer_pool中的元数据会表现的的不同,如果![]()
- transaction既要处理latch crabbing, 也要处理待删除的page
![]()
- 第一种情况,对于insert,由于是通过root_page_id_ == INVALID_PAGE_ID来判断是否是空树,以及来判断是否需要建立新树,那么当不互斥访问root_page_id时,就可能去建立多次调用StartNewTree;第二种情况是,FindLeafPage,当两个线程拿到root_page的时候,其中一个线程的级联delete导致root_page变化时,另一个线程这时拿的就是错误的root_page
![]()



测试
make
make b_plus_tree_print_test
make format
make check-lint
make check-clang-tidy
make b_plus_tree_delete_test
./test/b_plus_tree_delete_test
遇到的问题
- 这里的template不是很好理解
![]() 我的理解是对于临时的internal node这些类型
我的理解是对于临时的internal node这些类型![]() 这里是template的偏特化,模板偏特化主要分为两种,一种是指对部分模板参数进行全特化,另一种是对模板参数特性进行特化,包括将模板参数特化为指针、引用或是另外一个模板类。偏特化的目的是对于一般的类模板,模板参数T是在编译的时候编译器根据你传入的参数自动生成对应的代码,这样的好处是显而易见的对于同样的处理或者同样的操作过程可以很好的封装在一个模板当中,根据传入的不同的参数具体实现对于不同的数据或者对象的操作。
这里是template的偏特化,模板偏特化主要分为两种,一种是指对部分模板参数进行全特化,另一种是对模板参数特性进行特化,包括将模板参数特化为指针、引用或是另外一个模板类。偏特化的目的是对于一般的类模板,模板参数T是在编译的时候编译器根据你传入的参数自动生成对应的代码,这样的好处是显而易见的对于同样的处理或者同样的操作过程可以很好的封装在一个模板当中,根据传入的不同的参数具体实现对于不同的数据或者对象的操作。
但是这样也是有些问题是解决不了的,当有些数据类型或者对象不支持和其他的数据类型或者对象相同的操作的时候,就需要用其他的方式去实现同样一个过程,这个时候仅仅改变一个模板参数T是远远不行的。
![]()
Page *BufferPoolManager::FetchPageImpl(page_id_t page_id)将Page类型强制转换为a leaf or an internal page![]()
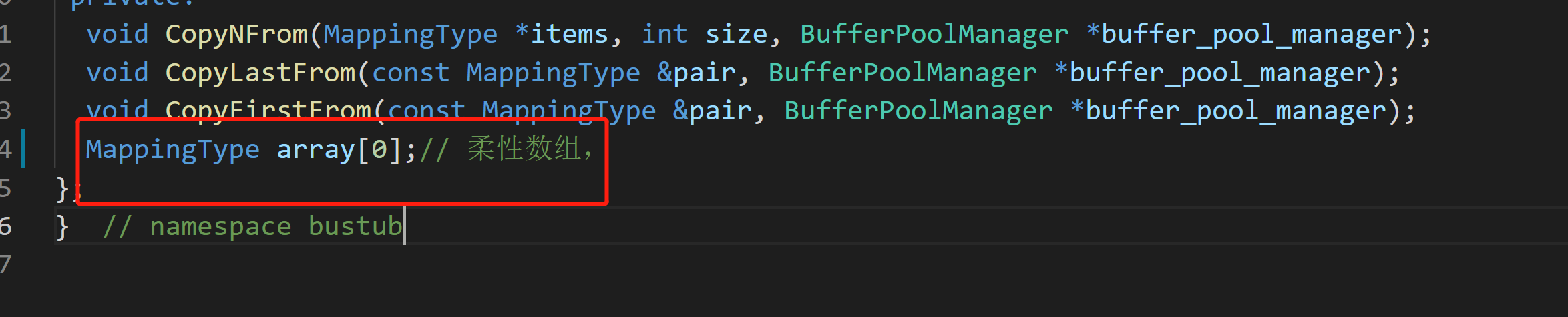
- 柔性数组
![]()
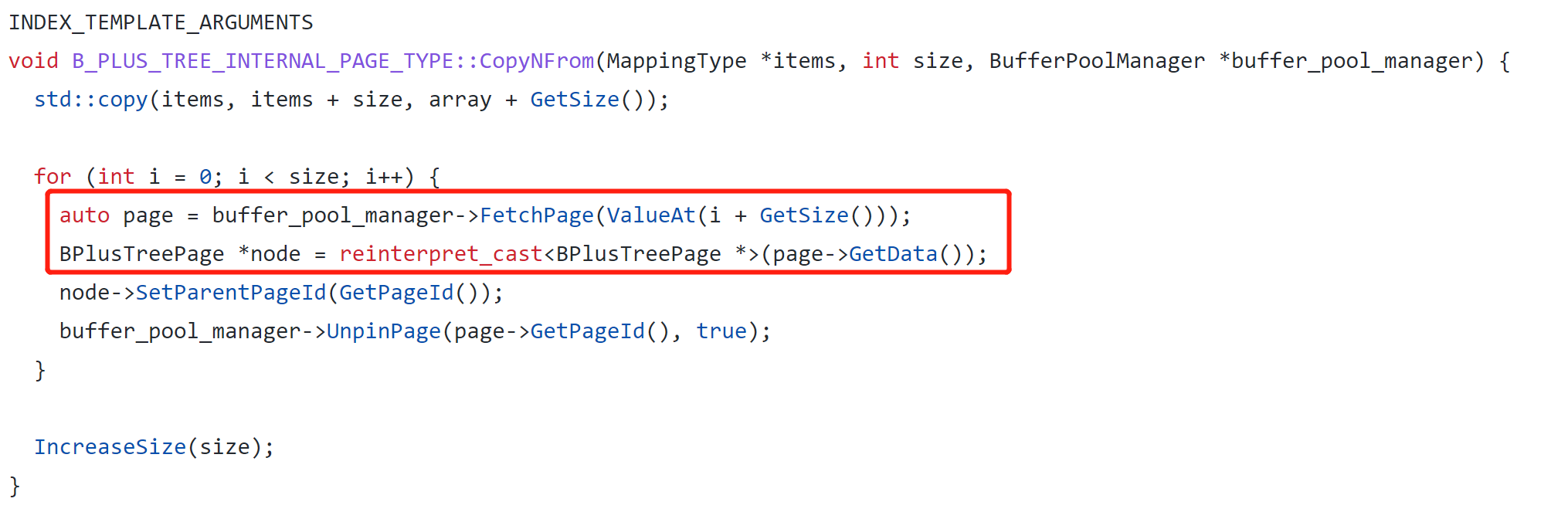
- 对于这句话,转为代码表示是
![]()
![]()
- 对于leaf node,不存在无效的key
![]()
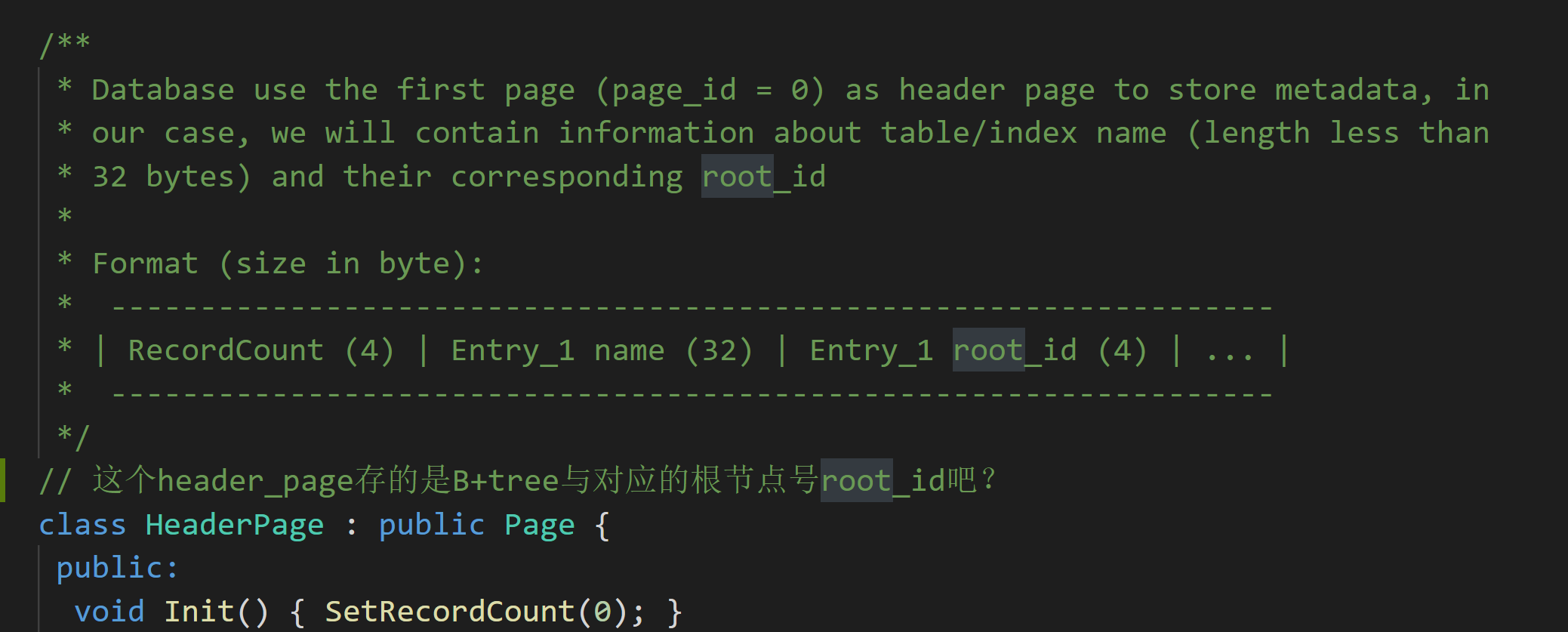
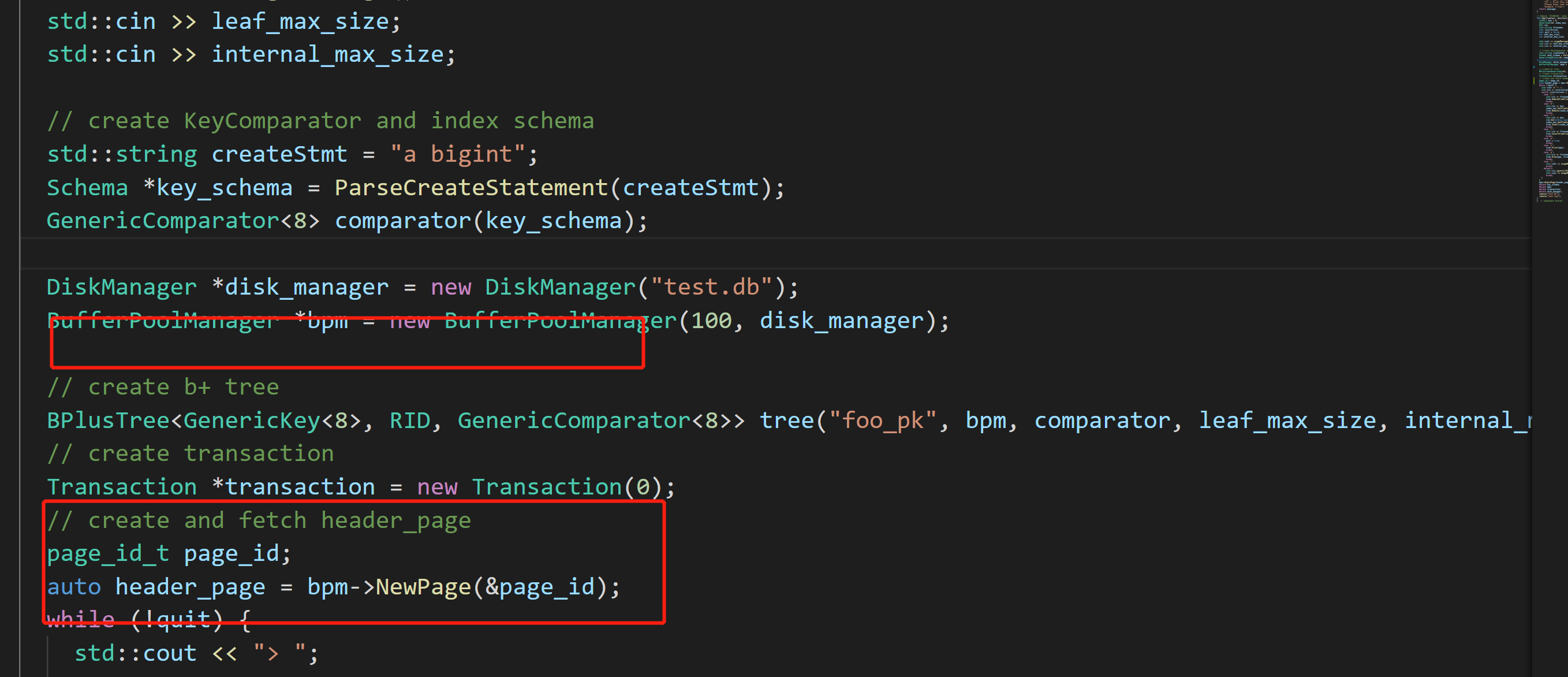
- 需要在header page中更新B+树index与其对应的root_id(也就是root节点所在的页id)
![]()
![]() 在一颗b+树index中存有index_name与root_page_id
在一颗b+树index中存有index_name与root_page_id![]()
- 这里的
max_size与max_size_,前者应该指的是字节上的大小,后者指的是k/v数![]() B+树的度 必须大于等于3
B+树的度 必须大于等于3 - 在lab2中的internal_node的分裂处理十分的巧妙,由于每个intrnal node的第一个k/v的k是无效的,那么我们将old_node的一半节点放到new_node中,在讲new_node的第0号k/v的k弹上parent_node,这样leaf node与internal node可以公用一个Split函数,并减少判断语句,也能够很好的把new_node的第0号k/v的当作是无效的
- 此处leaf node的max_size_是2,是指它可以由两个key,而internal node的max_size_是3,是指一个internal node最多可以有3个value,也就是指向下一层节点的pointer,pointe一般就是页号,本质上是一样的
![]()
![]() 特殊处理是指
特殊处理是指![]() 不过对于根节点的特殊处理有啥用,如果是写🔒,这个UnlatchAndUnpin处理的操作,不是用来解来🔒ancestor的吗,根节点又没有ancestors?还存在级联
不过对于根节点的特殊处理有啥用,如果是写🔒,这个UnlatchAndUnpin处理的操作,不是用来解来🔒ancestor的吗,根节点又没有ancestors?还存在级联Coalesce的这种情况,那么根节点会被🔒上,以及根节点的孩子会被🔒上- 只能给Page加🔒
![]()
- 函数声明有了默认参数,那么函数定义里就不可以有
![]()
![]()
- 把下面这段代码从上面移下来就能过了?
![]()
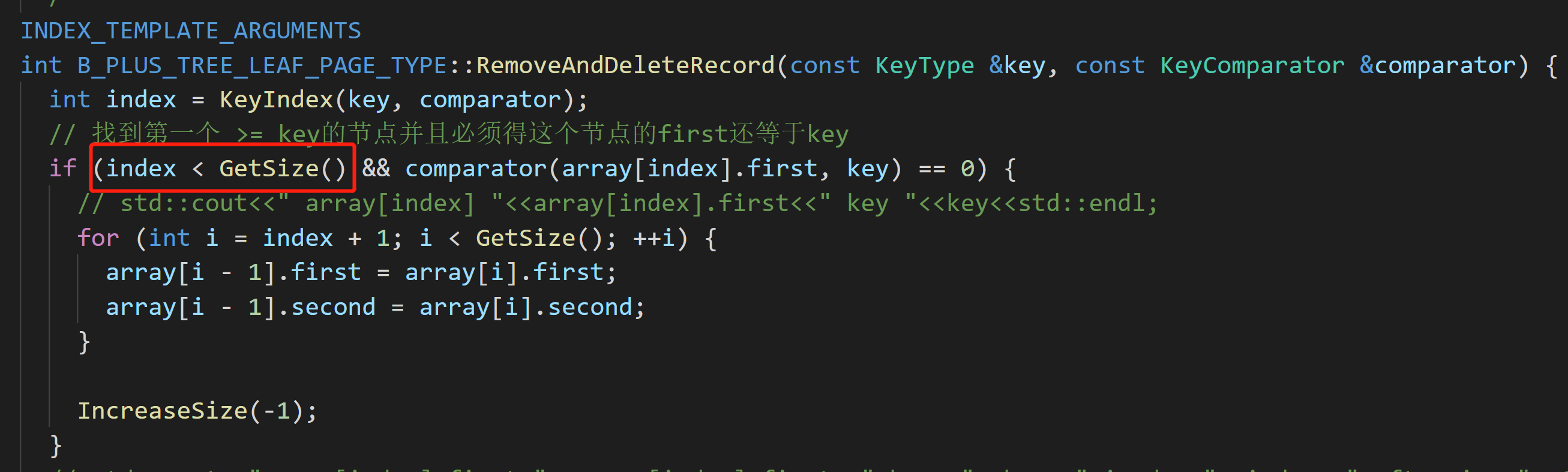
- 这里需要判断,如果
index == GetSize(),那么就说明没找到,需要不处理,在并发删除相同的数组元素时,有可能现在leaf node中的元素正好是数组边界外的第一个元素,会导致错误的size的减少![]()
 我的理解是对于临时的internal node这些类型
我的理解是对于临时的internal node这些类型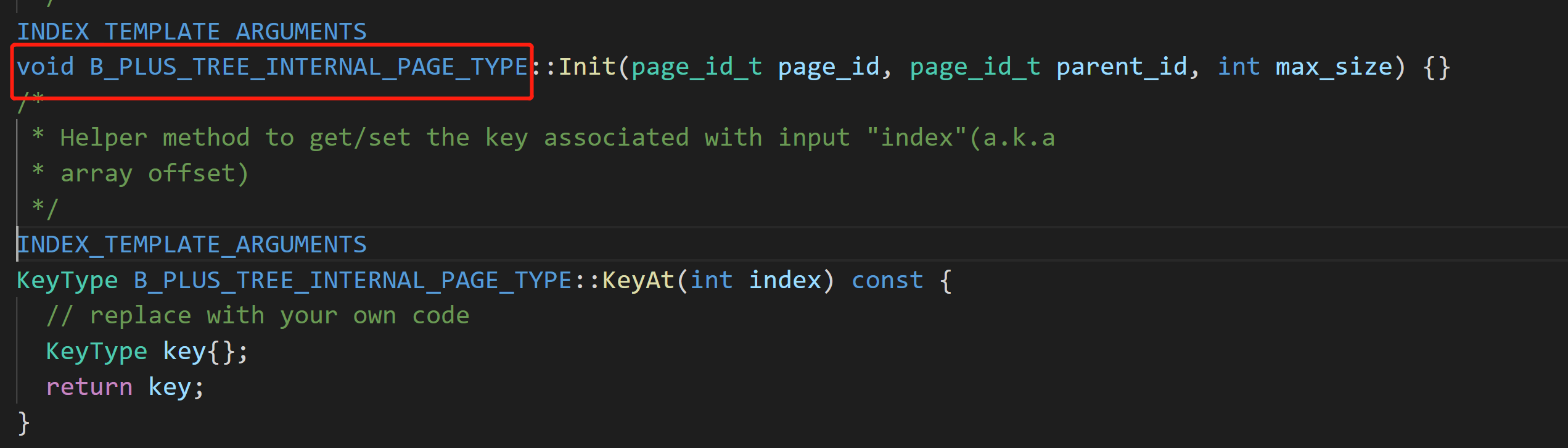 这里是template的偏特化,模板偏特化主要分为两种,一种是指对部分模板参数进行全特化,另一种是对模板参数特性进行特化,包括将模板参数特化为指针、引用或是另外一个模板类。偏特化的目的是对于一般的类模板,模板参数T是在编译的时候编译器根据你传入的参数自动生成对应的代码,这样的好处是显而易见的对于同样的处理或者同样的操作过程可以很好的封装在一个模板当中,根据传入的不同的参数具体实现对于不同的数据或者对象的操作。
这里是template的偏特化,模板偏特化主要分为两种,一种是指对部分模板参数进行全特化,另一种是对模板参数特性进行特化,包括将模板参数特化为指针、引用或是另外一个模板类。偏特化的目的是对于一般的类模板,模板参数T是在编译的时候编译器根据你传入的参数自动生成对应的代码,这样的好处是显而易见的对于同样的处理或者同样的操作过程可以很好的封装在一个模板当中,根据传入的不同的参数具体实现对于不同的数据或者对象的操作。


 在一颗b+树index中存有index_name与root_page_id
在一颗b+树index中存有index_name与root_page_id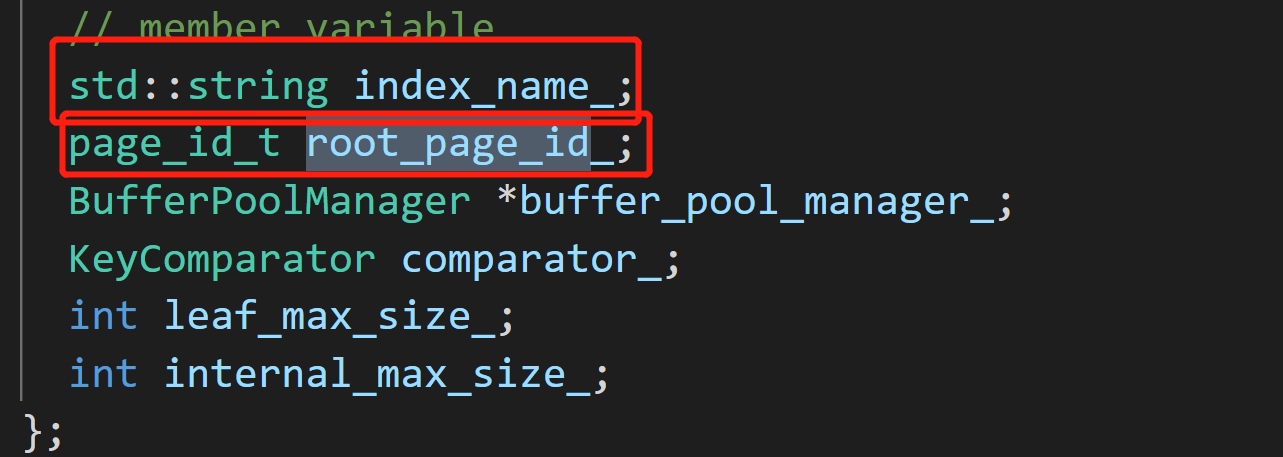
 B+树的度 必须大于等于3
B+树的度 必须大于等于3
 特殊处理是指
特殊处理是指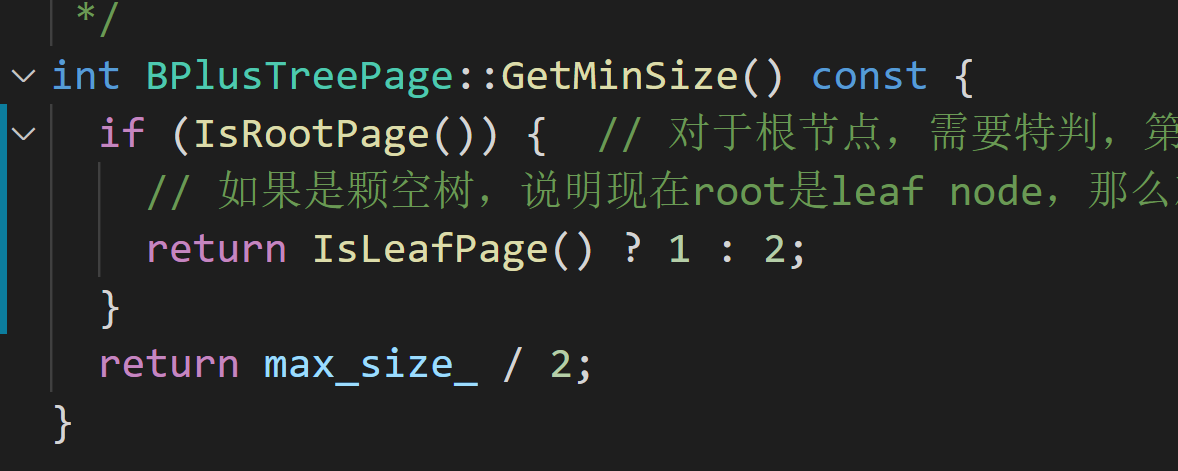 不过对于根节点的特殊处理有啥用,如果是写🔒,这个UnlatchAndUnpin处理的操作,不是用来解来🔒ancestor的吗,根节点又没有ancestors?还存在级联
不过对于根节点的特殊处理有啥用,如果是写🔒,这个UnlatchAndUnpin处理的操作,不是用来解来🔒ancestor的吗,根节点又没有ancestors?还存在级联


bug
-
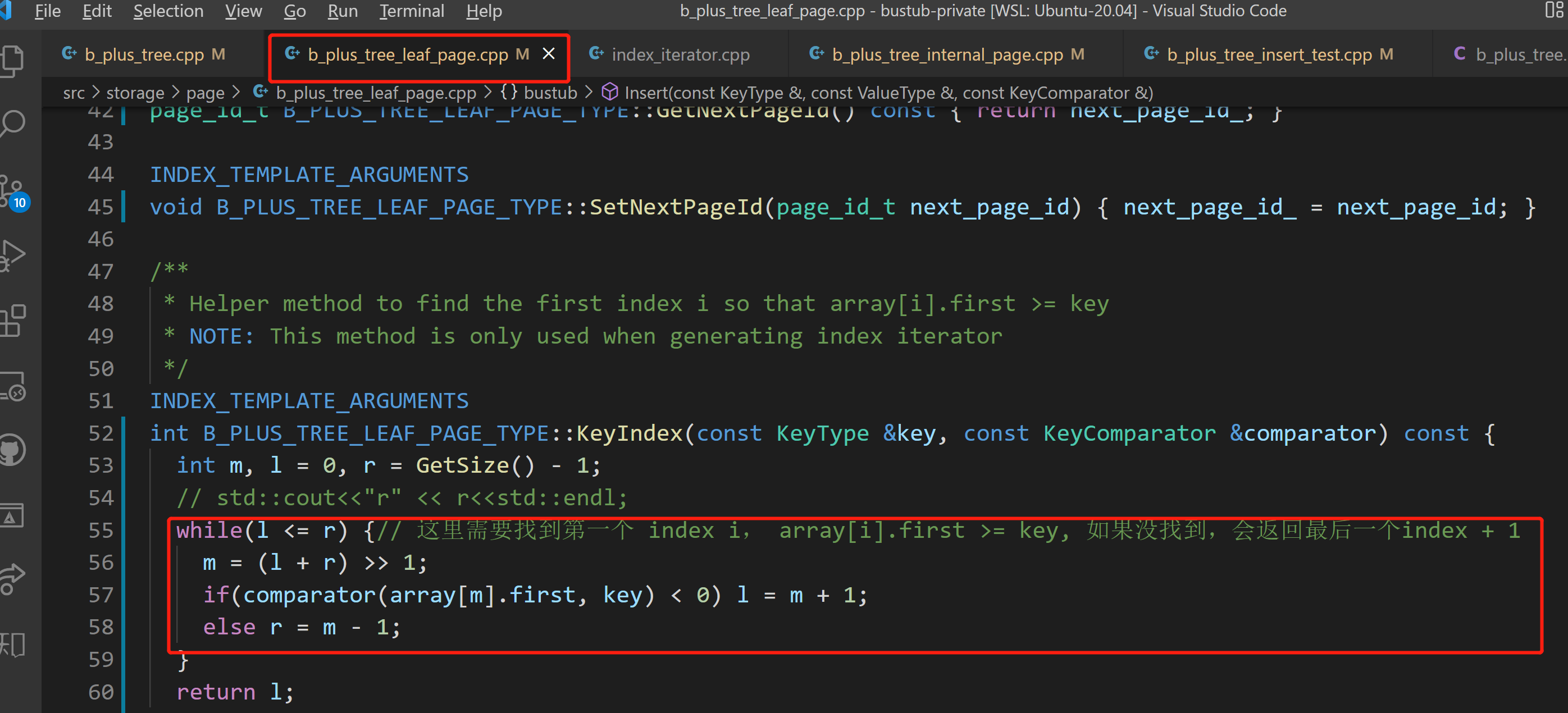
这里二分写错了,对于完全找不到大于当前插入的元素的元素时,需要特殊处理
![]()
-
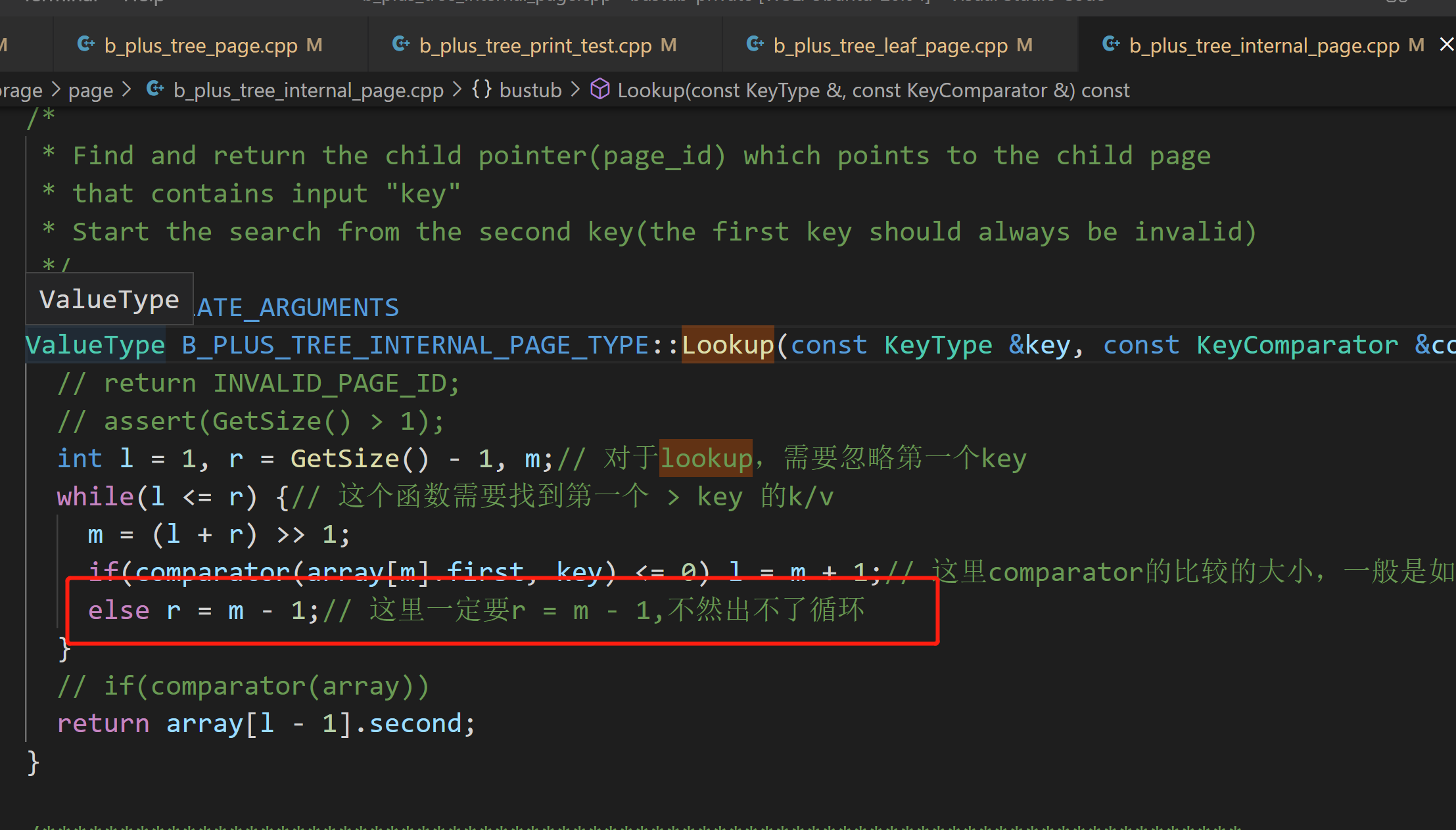
这个二分也是写错了
![]()
-
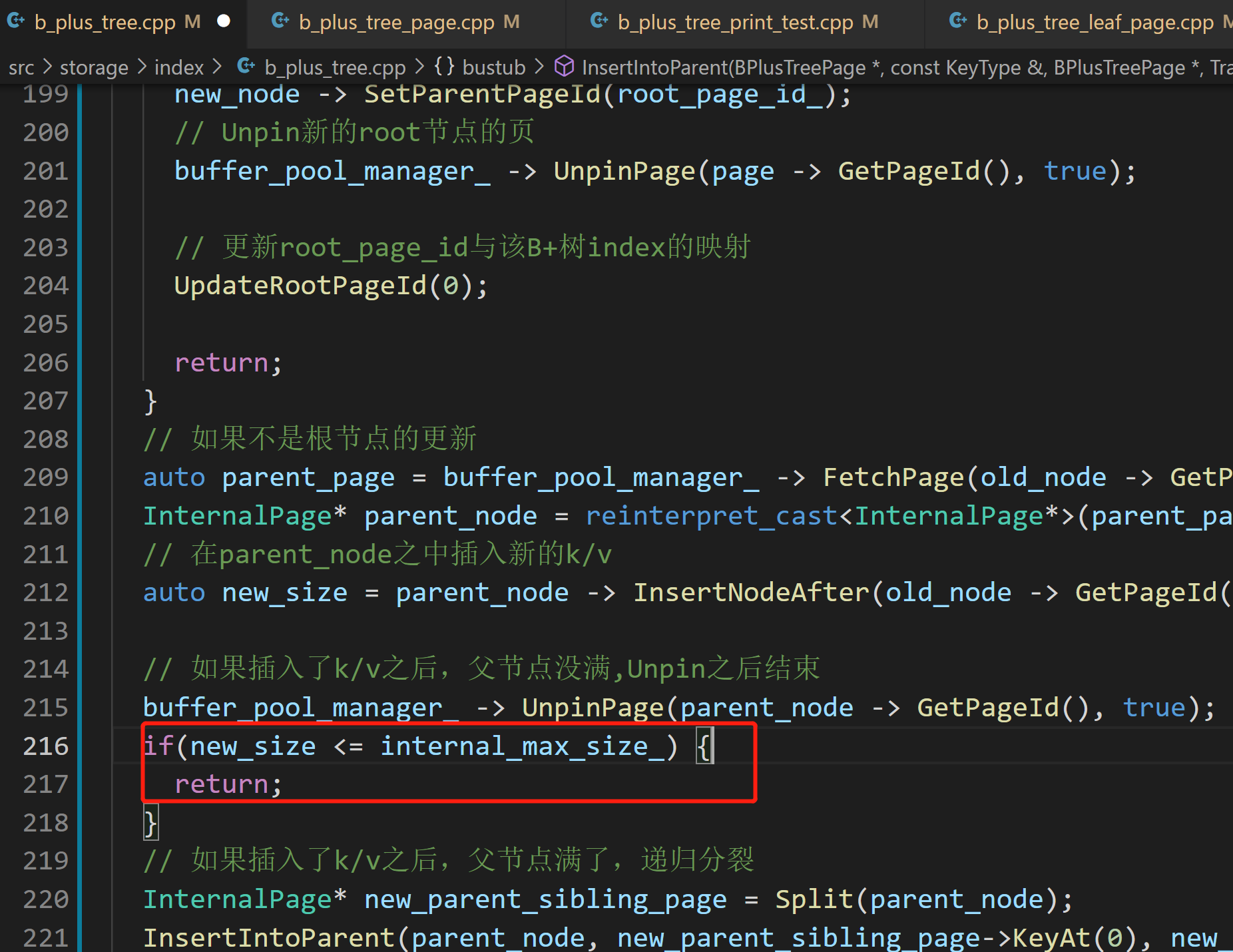
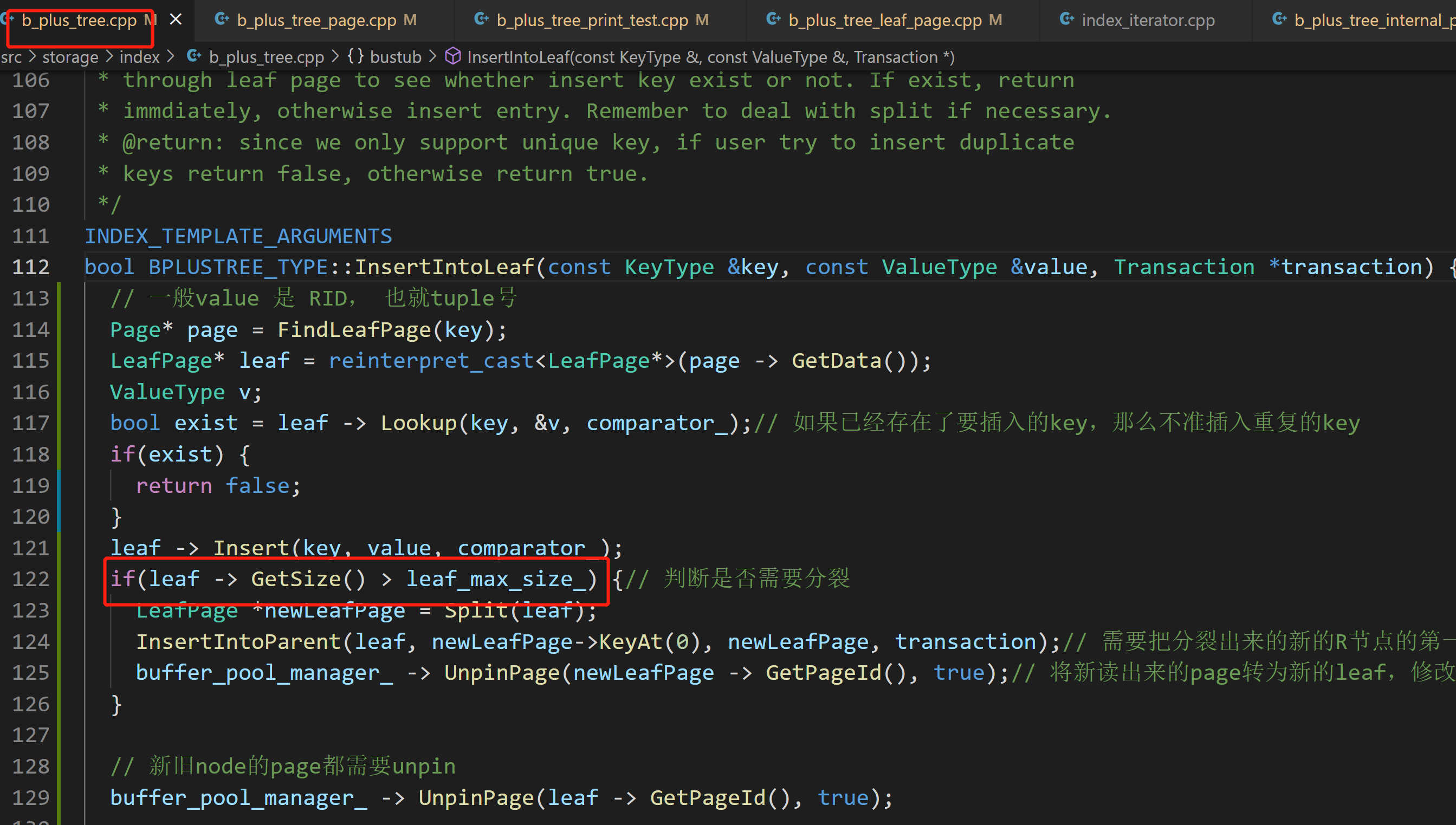
注意是插入之前达到max_size,再插入一个,才要分裂
![]()
此处是通过max_size来判断internal node的分裂![]()
此处是通过max_size来判断leaf node的分裂![]()
-
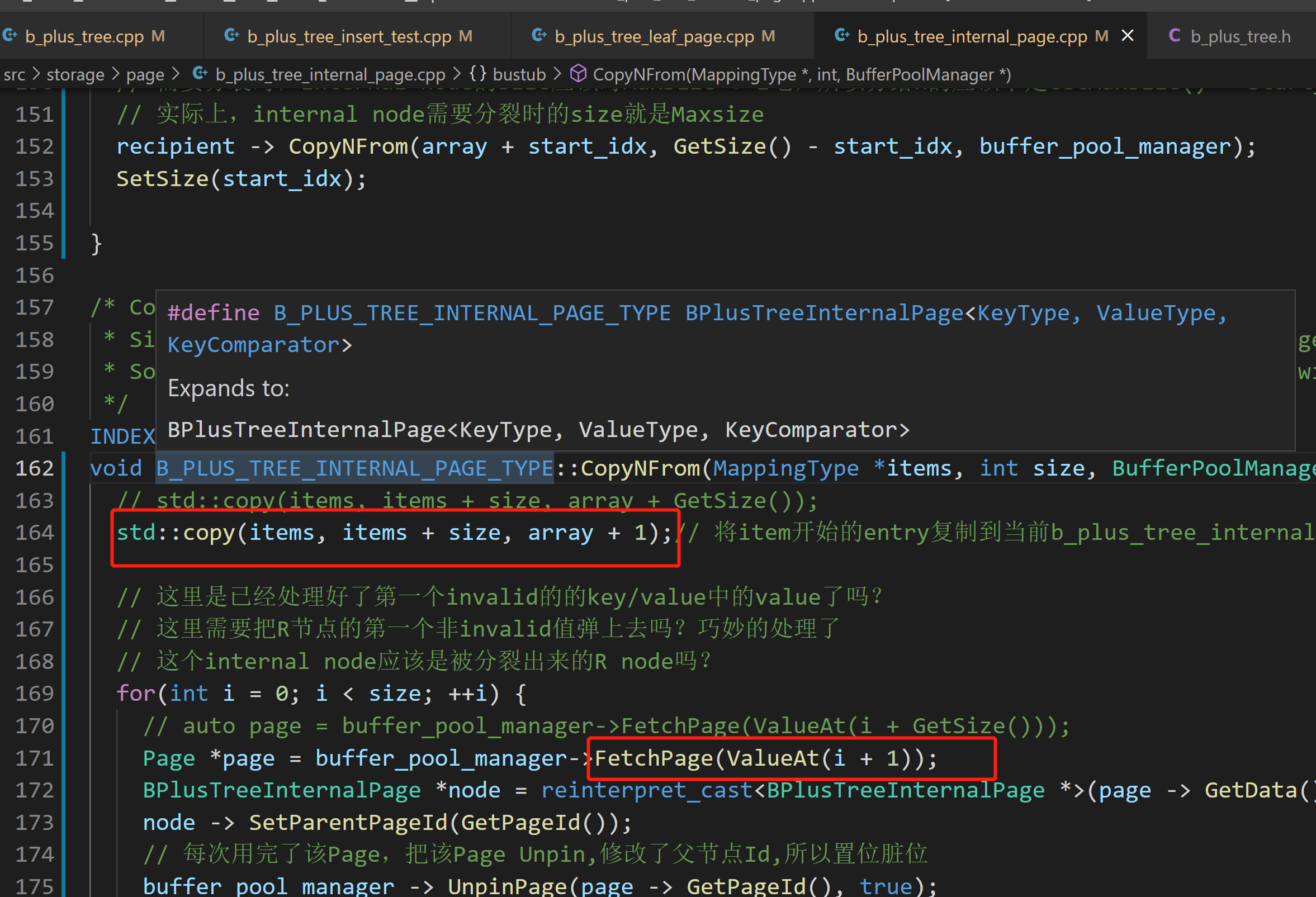
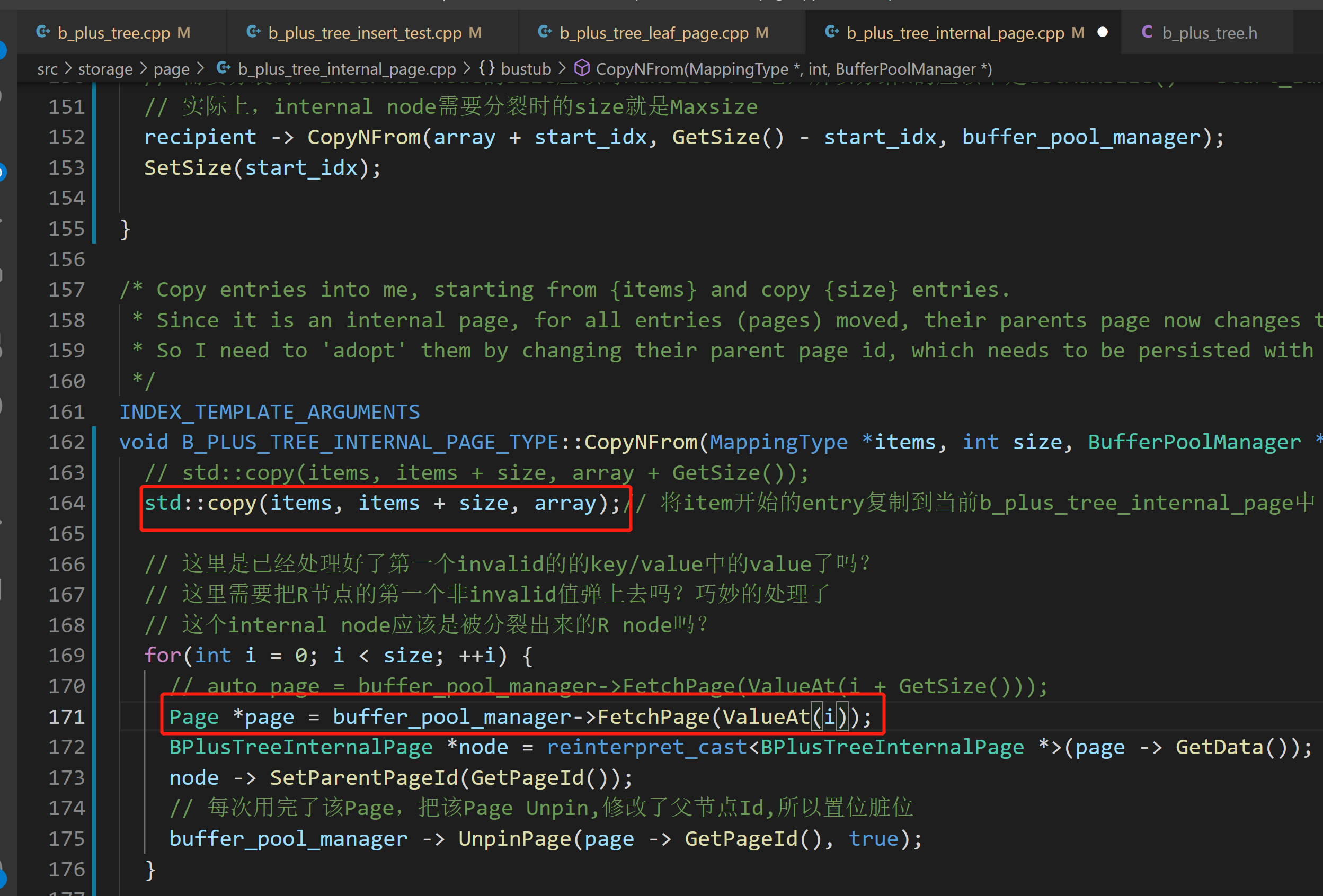
注意,由于对于internal node分裂的巧妙处理,所以分裂出来的R node需要从第0个元素开始接收copy,之后第0号k/v会被设置为无效,也就是抛到父节点
![]()
![]()
-
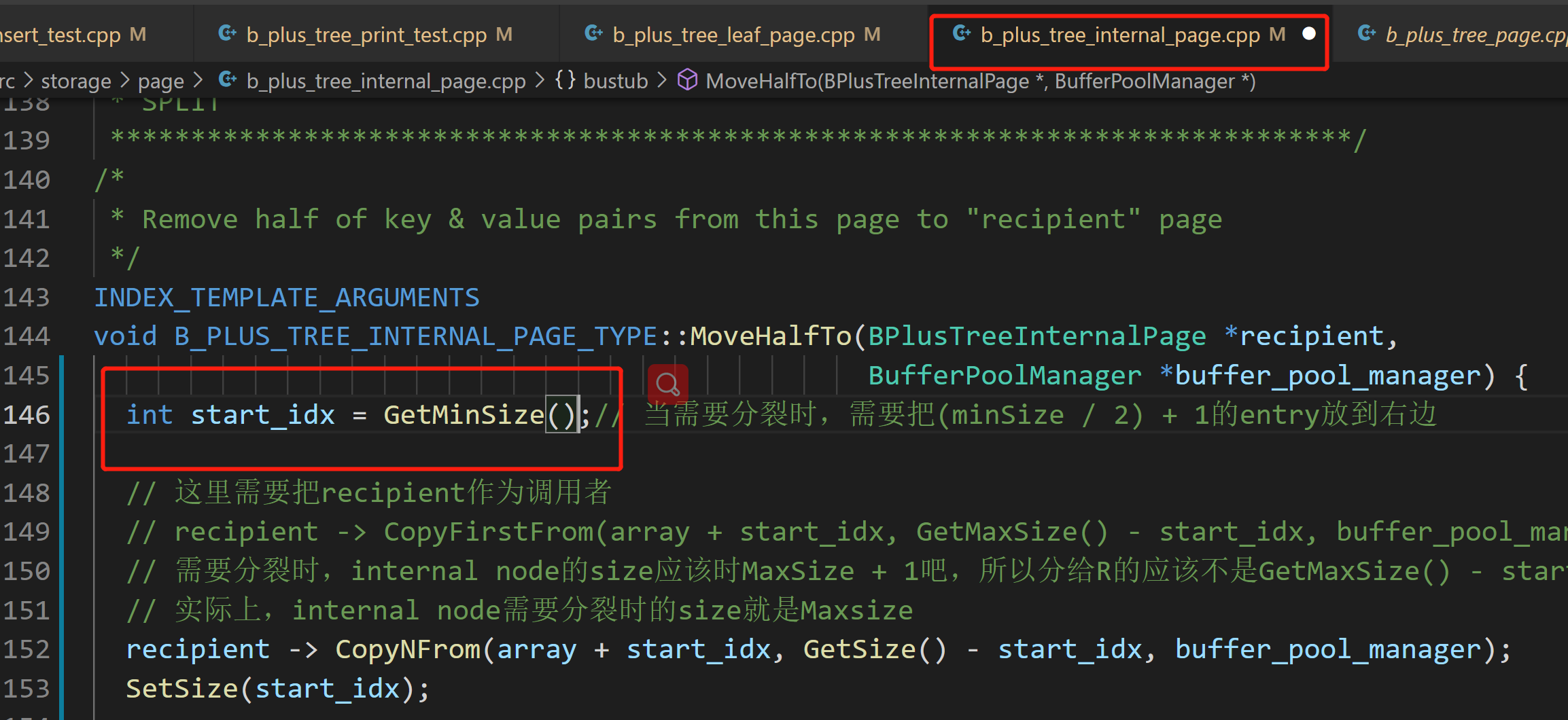
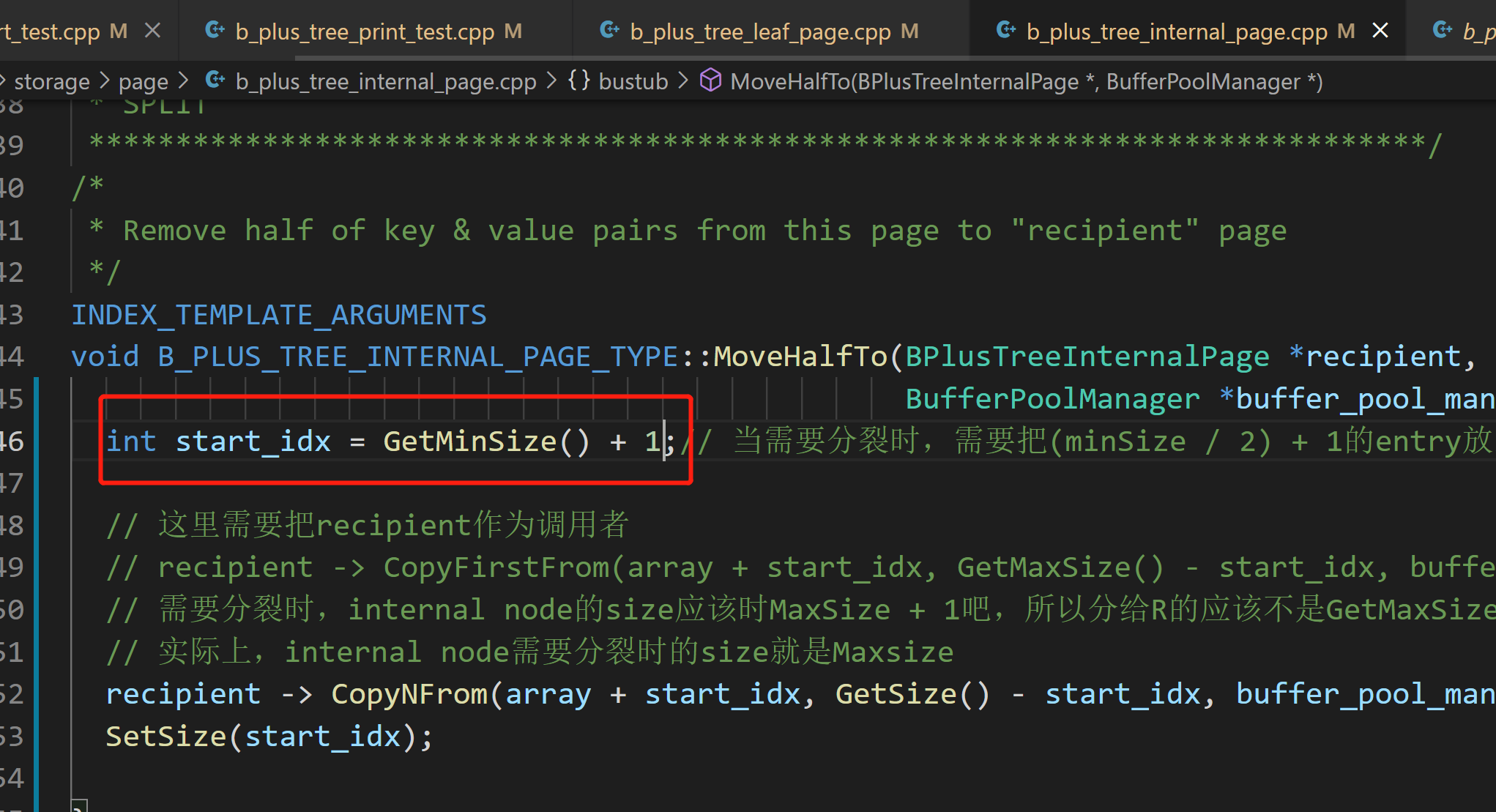
注意这里需要把Min_Size个元素放到分裂出来的左边节点,也就是要使得middle key弹上去
![]()
![]()
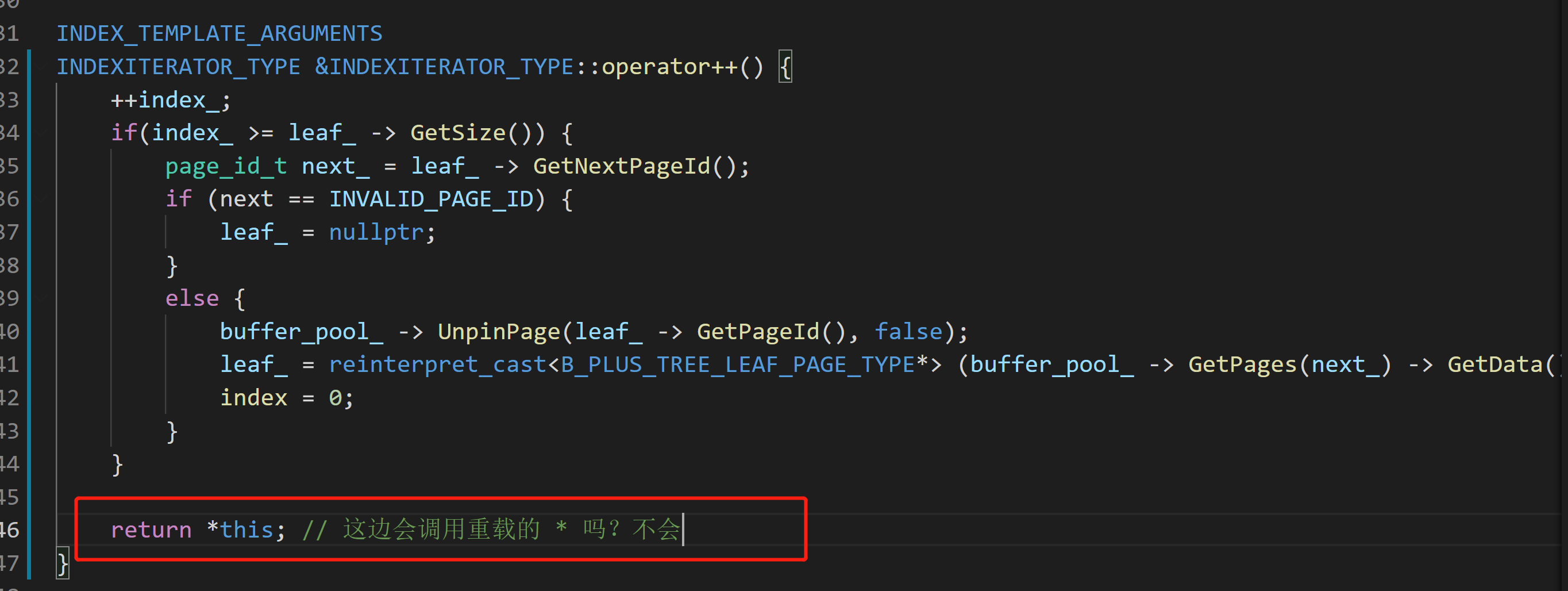
-
这里的this指针不会调用重载的
*,因为其解引用得到的是对象本身,而该对象调用*就会调用重载的*![]()
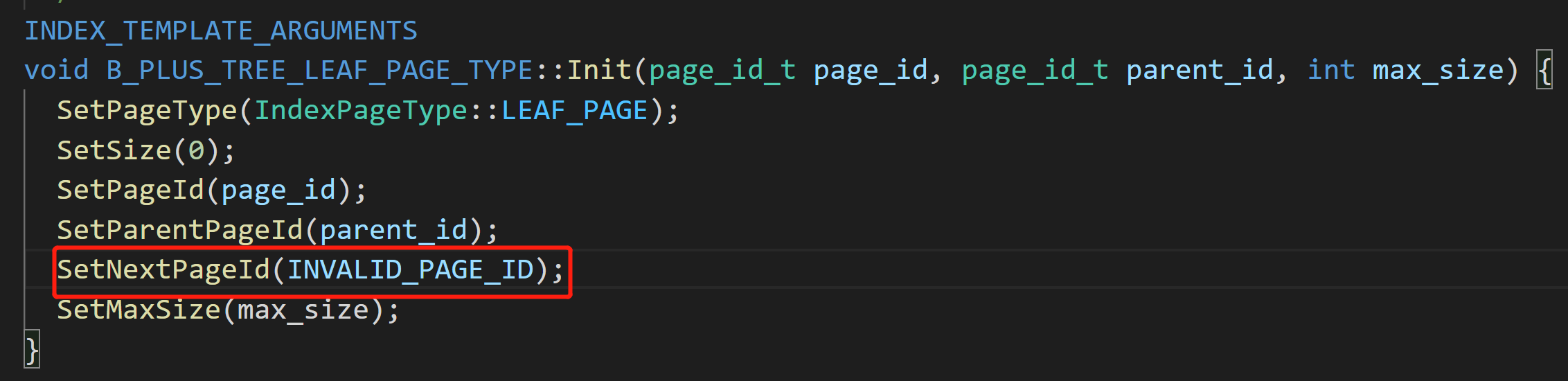
-
别忘了初始化leaf node的时候需要设置nextpageid
![]()
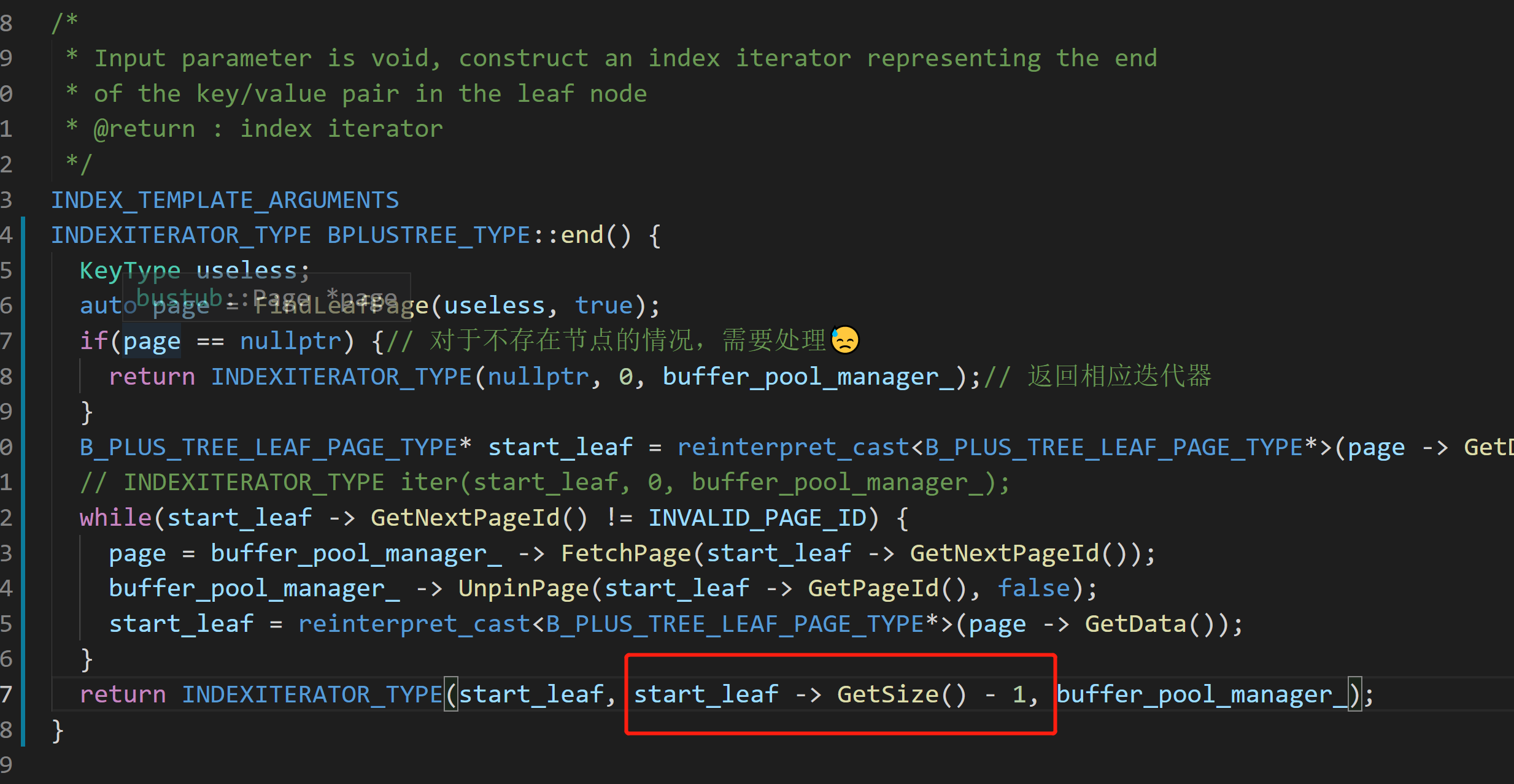
-
这里应该是GetSize()
![]()
-
这两个函数
isEnd()和operator++()应该这样写

INDEX_TEMPLATE_ARGUMENTS
bool INDEXITERATOR_TYPE::isEnd() { return (leaf_ -> GetNextPageId() == INVALID_PAGE_ID) && index_ == leaf_ -> GetSize(); }
INDEX_TEMPLATE_ARGUMENTS
const MappingType &INDEXITERATOR_TYPE::operator*() { return leaf_ -> GetItem(index_); }
INDEX_TEMPLATE_ARGUMENTS
INDEXITERATOR_TYPE &INDEXITERATOR_TYPE::operator++() {
++index_;
if(index_ >= leaf_ -> GetSize()) {
page_id_t next_ = leaf_ -> GetNextPageId();
// if (next_ == INVALID_PAGE_ID) {
// leaf_ = nullptr;
// }
// else {
// buffer_pool_ -> UnpinPage(leaf_ -> GetPageId(), false);
// leaf_ = reinterpret_cast<B_PLUS_TREE_LEAF_PAGE_TYPE*> (buffer_pool_ -> FetchPage(next_) -> GetData());
// index_ = 0;
// }
if(next_ != INVALID_PAGE_ID) {
buffer_pool_ -> UnpinPage(leaf_ -> GetPageId(), false);
leaf_ = reinterpret_cast<B_PLUS_TREE_LEAF_PAGE_TYPE*> (buffer_pool_ -> FetchPage(next_) -> GetData());
index_ = 0;
}
}
return *this; // 这边会调用重载的 * 吗?不会
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号