【人工智能】神经网络八股
使用八股搭建神经网络
六步法搭建网络
用tensorflow API:tf.leras搭建网络八股
import # 导入相关模块
train,test # 告知要喂入网络的训练集和测试集。即指定训练集的输入特征x_train和训练集的标签y_train;指定测试集的输入特征x_test和测试集的标签y_test
model=tf.keras.models.Sequential # 在Sequential()中搭建网络结构,逐层描述每层网络,相当于走了一遍前向传播
model.compile # 在compile()中配置训练方法,告知训练时选择哪种优化器,选择哪个损失函数,选择哪种评测指标
model.fit # 在fit()中执行训练过程,告知训练集和测试集的输入标签和特征,告知,每个batch是多少,告知要迭代多少次数据集。
model.summary # 用summary()打印出网络的结构和参数统计
(1)tf.keras.models.Sequential
可以搭建出上层输出下层输入的神经网络结构,但是无法写出一些带有跳连的非顺序网络结构
model = tf.keras.models.Sequential([网络结构]) # 描述各层网络
网络结构举例:
拉直层:tf.keras.layers.Flatten()
这一层不含计算,只是形状转换。把输入特征拉直,变为一维数组
全连接层:tf.keras.layers.Dense(神经元个数、activation="激活函数",kernel_regularizer=哪种正则化)
activate(字符串给出)可选:
relu,softmax,tanh,sigmoid,
kernel_regularizer可选:,
tf.keras.regularizersl1(),tf.keras.regularizers.l2()
卷积层:tf.keras.layers.Conv2D(filters=卷积核个数,kernel_size=卷积核尺寸,strides=卷积步长,padding="valid"or"same")
LSTM层:tf.keras.layers.LSTM()
(2)model.compile
model.compile(optimizer=优化器,loss=损失函数,metrics=["准确率"])
Optimizer可选
"sgd" or tf.keras.optimizers.SGD(lr=学习率,momentum=动量参数)
"adagrad" or tf.keras.optimizers.Adagrad(lr=学习率)
"adadelta" or tf.keras.optimizers.Adadelta(lr=学习率)
"adam" or tf.keras.optimisers.Adam(lr=学习率,beta_1=0.9,beta_2=0.999)
建议初学者使用左边这些字符串形式的优化器名字
loss可选
"mes" or tf.keras.losses.MeanSquaredError()
"spaese_categorical_crossentropy" or tf.keras.losses.SparseCategoricalCrossentropy(from_logits=false)
Metrics可选
"accuracy":y_和y都是数值
"categorical_accuracy":y_和y都是独热码(概率分布)
"spare_categorical_accuracy":y_是数值,y是独热码(概率分布)
(3)model.fit
fit()执行训练过程
model.fit(训练集的输入特征,训练集的标签,
batch_size=?,epochs=?,
validation_data=(测试集的输入特征,测试集的标签),
validation_split=从训练集划分多少比例给测试集,
validation_freq=多少次epoch测试一次
)
batch_size:每次喂入神经网络的样本数
epochs:要迭代多少次数据集
validation_data 和 validation_split 二者选择其一使用
validation_freq:没多少次epoch迭代使用测试集验证一次结果
(4)model.summary
summary() 可以打印网络的结构和参数统计
总参数:Total params
可训练参数:Trainable params
不可训练参数:Non-Trainable params
源码
import tensorflow as tf
from sklearn import datasets
import numpy as np
x_train = datasets.load_iris().data
y_train = datasets.load_iris().target
np.random.seed(116)
np.random.shuffle(x_train)
np.random.seed(116)
np.random.shuffle(y_train)
tf.random.set_seed(116)
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(3, activation='softmax', kernel_regularizer=tf.keras.regularizers.l2())
])
model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=500, validation_split=0.2, validation_freq=20)
model.summary()
Epoch 1/500
4/4 [] - 0s 748us/step - loss: 2.3173 - sparse_categorical_accuracy: 0.3417
中间运行结果省略
Epoch 500/500
4/4 [] - 0s 3ms/step - loss: 0.3888 - sparse_categorical_accuracy: 0.9250 - val_loss: 0.3516 - val_sparse_categorical_accuracy: 0.8667
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_13 (Dense) (None, 3) 15
=================================================================
Total params: 15
Trainable params: 15
Non-trainable params: 0
_________________________________________________________________
(5)类class搭建神经网络
用class类封装一个神经网络结构
class MyModel(Model) model=MyModel
class MyModel(Model):
def __init__(self):
super(MyModel,self).__init__()
# 定义网络结构模块
def call(self,x):
# 调用网络结构模块,实现前向传播
return y
model = MyModel()
__init__()定义所需网络结构模块
call()写出前向传播
from tensorflow.keras import Model
class IrisModel(Model):
def __init__(self):
super(IrisModel,self).__init__()
self.d1 = Dense(3)
def call(self,x):
y = self.d1(x)
return y
model = IrisModel
import tensorflow as tf
from tensorflow.keras.layers import Dense
from tensorflow.keras import Model
from sklearn import datasets
import numpy as np
x_train = datasets.load_iris().data
y_train = datasets.load_iris().target
np.random.seed(116)
np.random.shuffle(x_train)
np.random.seed(116)
np.random.shuffle(y_train)
tf.random.set_seed(116)
class IrisModel(Model):
def __init__(self):
super(IrisModel, self).__init__()
self.d1 = Dense(3, activation='softmax', kernel_regularizer=tf.keras.regularizers.l2())
def call(self, x):
y = self.d1(x)
return y
model = IrisModel()
model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=500, validation_split=0.2, validation_freq=20)
model.summary()
Epoch 1/500
4/4 [] - 0s 748us/step - loss: 2.3173 - sparse_categorical_accuracy: 0.3417
Epoch 2/500
中间运行结果省略
Epoch 500/500
4/4 [] - 0s 4ms/step - loss: 0.3888 - sparse_categorical_accuracy: 0.9250 - val_loss: 0.3516 - val_sparse_categorical_accuracy: 0.8667
Model: "iris_model_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_14 (Dense) multiple 15
=================================================================
Total params: 15
Trainable params: 15
Non-trainable params: 0
_________________________________________________________________
MNIST数据集
提供六万张20 * 20像素点的0~9手写数字图片和标签,用于训练
提供一万张28 * 28像素点的0~9手写数字图片和标签,用于测试
导入MNIST数据集
mnist = tf.keras.datasets.mnist
(x_train,y_train),(x_test,y_test)=mnist.load_data()
作为输入特征,输入神经网络时,将数据拉伸为一维数组
tf.keras.layers.Flatten()
把训练集中的第一个样本x_train[0]可视化出来
plt.imshow(x_train[0],cmap="gray") # 绘制灰度图
plt.show
代码如下:
import tensorflow as tf
from matplotlib import pyplot as plt
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 可视化训练集输入特征的第一个元素
plt.imshow(x_train[0], cmap='gray') # 绘制灰度图
plt.show()
# 打印出训练集输入特征的第一个元素
print("x_train[0]:\n", x_train[0])
# 打印出训练集标签的第一个元素
print("y_train[0]:\n", y_train[0])
# 打印出整个训练集输入特征形状
print("x_train.shape:\n", x_train.shape)
# 打印出整个训练集标签的形状
print("y_train.shape:\n", y_train.shape)
# 打印出整个测试集输入特征的形状
print("x_test.shape:\n", x_test.shape)
# 打印出整个测试集标签的形状
print("y_test.shape:\n", y_test.shape)
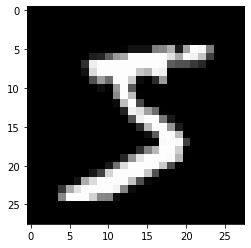
x_train[0]:
[[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 3 18 18 18 126 136
175 26 166 255 247 127 0 0 0 0]
[ 0 0 0 0 0 0 0 0 30 36 94 154 170 253 253 253 253 253
225 172 253 242 195 64 0 0 0 0]
[ 0 0 0 0 0 0 0 49 238 253 253 253 253 253 253 253 253 251
93 82 82 56 39 0 0 0 0 0]
[ 0 0 0 0 0 0 0 18 219 253 253 253 253 253 198 182 247 241
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 80 156 107 253 253 205 11 0 43 154
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 14 1 154 253 90 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 139 253 190 2 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 11 190 253 70 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 35 241 225 160 108 1
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 81 240 253 253 119
25 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 45 186 253 253
150 27 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 16 93 252
253 187 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 249
253 249 64 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 46 130 183 253
253 207 2 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 39 148 229 253 253 253
250 182 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 24 114 221 253 253 253 253 201
78 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 23 66 213 253 253 253 253 198 81 2
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 18 171 219 253 253 253 253 195 80 9 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 55 172 226 253 253 253 253 244 133 11 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 136 253 253 253 212 135 132 16 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]]
y_train[0]:
5
x_train.shape:
(60000, 28, 28)
y_train.shape:
(60000,)
x_test.shape:
(10000, 28, 28)
y_test.shape:
(10000,)
Sequential实现数字识别训练
完整代码如下:
方法1:
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1)
model.summary()
Epoch 1/5
1875/1875 [] - 2s 821us/step - loss: 0.2508 - sparse_categorical_accuracy: 0.9294 - val_loss: 0.1320 - val_sparse_categorical_accuracy: 0.9597
Epoch 2/5
1875/1875 [] - 1s 766us/step - loss: 0.1117 - sparse_categorical_accuracy: 0.9670 - val_loss: 0.1034 - val_sparse_categorical_accuracy: 0.9703
Epoch 3/5
1875/1875 [] - 1s 786us/step - loss: 0.0759 - sparse_categorical_accuracy: 0.9771 - val_loss: 0.0853 - val_sparse_categorical_accuracy: 0.9746
Epoch 4/5
1875/1875 [] - 1s 778us/step - loss: 0.0576 - sparse_categorical_accuracy: 0.9829 - val_loss: 0.0758 - val_sparse_categorical_accuracy: 0.9762
Epoch 5/5
1875/1875 [==============================] - 1s 757us/step - loss: 0.0441 - sparse_categorical_accuracy: 0.9864 - val_loss: 0.0744 - val_sparse_categorical_accuracy: 0.9761
Model: "sequential_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_5 (Flatten) (None, 784) 0
_________________________________________________________________
dense_15 (Dense) (None, 128) 100480
_________________________________________________________________
dense_16 (Dense) (None, 10) 1290
=================================================================
Total params: 101,770
Trainable params: 101,770
Non-trainable params: 0
_________________________________________________________________
上边的是使用Sequential方法
下边用类实现手写数字识别模型训练
import tensorflow as tf
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras import Model
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
class MnistModel(Model):
def __init__(self):
super(MnistModel, self).__init__()
self.flatten = Flatten()
self.d1 = Dense(128, activation='relu')
self.d2 = Dense(10, activation='softmax')
def call(self, x):
x = self.flatten(x)
x = self.d1(x)
y = self.d2(x)
return y
model = MnistModel()
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1)
model.summary()
Epoch 1/5
1823/1875 [>.] - ETA: 0s - loss: 0.2640 - sparse_categorical_accuracy: 0.9253WARNING:tensorflow:Callbacks method on_test_batch_end is slow compared to the batch time (batch time: 0.0000s vs on_test_batch_end time: 0.0010s). Check your callbacks.
1875/1875 [] - 2s 894us/step - loss: 0.2601 - sparse_categorical_accuracy: 0.9264 - val_loss: 0.1423 - val_sparse_categorical_accuracy: 0.9550
Epoch 2/5
1875/1875 [] - 1s 735us/step - loss: 0.1130 - sparse_categorical_accuracy: 0.9665 - val_loss: 0.1014 - val_sparse_categorical_accuracy: 0.9699
Epoch 3/5
1875/1875 [] - 1s 728us/step - loss: 0.0760 - sparse_categorical_accuracy: 0.9772 - val_loss: 0.0878 - val_sparse_categorical_accuracy: 0.9729
Epoch 4/5
1875/1875 [] - 1s 787us/step - loss: 0.0575 - sparse_categorical_accuracy: 0.9825 - val_loss: 0.0720 - val_sparse_categorical_accuracy: 0.9768
Epoch 5/5
1875/1875 [==] - 1s 732us/step - loss: 0.0440 - sparse_categorical_accuracy: 0.9865 - val_loss: 0.0786 - val_sparse_categorical_accuracy: 0.9764
Model: "mnist_model_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_6 (Flatten) multiple 0
_________________________________________________________________
dense_17 (Dense) multiple 100480
_________________________________________________________________
dense_18 (Dense) multiple 1290
=================================================================
Total params: 101,770
Trainable params: 101,770
Non-trainable params: 0
_________________________________________________________________
FASHION数据集
提供6万张20 * 28像素点的衣裤等图片和标签,用于训练
提供一万张28 * 28像素点的衣裤等图片和标签,用于测试
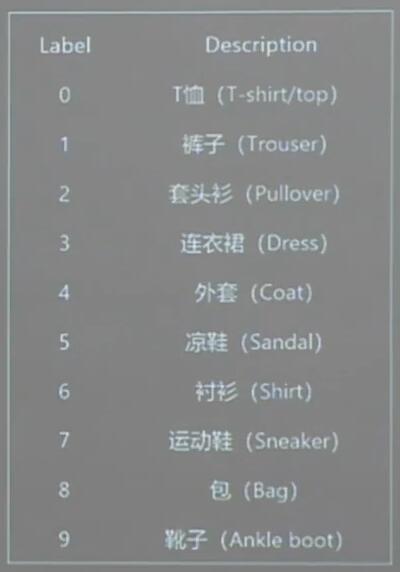
导入FASHION数据集
fashion = tf.keras.datasets.fashion_mnist
(x_train,y_train),(x_test,y_test) = fashion.load_data()
完整代码如下
(1)Sequential方法
import tensorflow as tf
fashion = tf.keras.datasets.fashion_mnist
(x_train, y_train),(x_test, y_test) = fashion.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1)
model.summary()
Epoch 1/5
1875/1875 [] - 2s 908us/step - loss: 0.5022 - sparse_categorical_accuracy: 0.8241 - val_loss: 0.4137 - val_sparse_categorical_accuracy: 0.8531
Epoch 2/5
1875/1875 [] - 1s 764us/step - loss: 0.3777 - sparse_categorical_accuracy: 0.8642 - val_loss: 0.4052 - val_sparse_categorical_accuracy: 0.8574
Epoch 3/5
1875/1875 [] - 1s 733us/step - loss: 0.3383 - sparse_categorical_accuracy: 0.8766 - val_loss: 0.3890 - val_sparse_categorical_accuracy: 0.8609
Epoch 4/5
1875/1875 [] - 1s 751us/step - loss: 0.3157 - sparse_categorical_accuracy: 0.8838 - val_loss: 0.3711 - val_sparse_categorical_accuracy: 0.8637
Epoch 5/5
1875/1875 [==============================] - 1s 731us/step - loss: 0.2976 - sparse_categorical_accuracy: 0.8903 - val_loss: 0.3641 - val_sparse_categorical_accuracy: 0.8667
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_7 (Flatten) (None, 784) 0
_________________________________________________________________
dense_19 (Dense) (None, 128) 100480
_________________________________________________________________
dense_20 (Dense) (None, 10) 1290
=================================================================
Total params: 101,770
Trainable params: 101,770
Non-trainable params: 0
_________________________________________________________________
(2)类方法
import tensorflow as tf
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras import Model
fashion = tf.keras.datasets.fashion_mnist
(x_train, y_train),(x_test, y_test) = fashion.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
class MnistModel(Model):
def __init__(self):
super(MnistModel, self).__init__()
self.flatten = Flatten()
self.d1 = Dense(128, activation='relu')
self.d2 = Dense(10, activation='softmax')
def call(self, x):
x = self.flatten(x)
x = self.d1(x)
y = self.d2(x)
return y
model = MnistModel()
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1)
model.summary()
Epoch 1/5
1875/1875 [] - 2s 831us/step - loss: 0.4998 - sparse_categorical_accuracy: 0.8241 - val_loss: 0.4051 - val_sparse_categorical_accuracy: 0.8543
Epoch 2/5
1875/1875 [] - 1s 738us/step - loss: 0.3737 - sparse_categorical_accuracy: 0.8652 - val_loss: 0.4044 - val_sparse_categorical_accuracy: 0.8572
Epoch 3/5
1875/1875 [] - 1s 726us/step - loss: 0.3347 - sparse_categorical_accuracy: 0.8785 - val_loss: 0.3784 - val_sparse_categorical_accuracy: 0.8629
Epoch 4/5
1875/1875 [] - 1s 701us/step - loss: 0.3126 - sparse_categorical_accuracy: 0.8857 - val_loss: 0.3707 - val_sparse_categorical_accuracy: 0.8645
Epoch 5/5
1875/1875 [==============================] - 1s 780us/step - loss: 0.2967 - sparse_categorical_accuracy: 0.8917 - val_loss: 0.3506 - val_sparse_categorical_accuracy: 0.8698
Model: "mnist_model_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_8 (Flatten) multiple 0
_________________________________________________________________
dense_21 (Dense) multiple 100480
_________________________________________________________________
dense_22 (Dense) multiple 1290
=================================================================
Total params: 101,770
Trainable params: 101,770
Non-trainable params: 0
_________________________________________________________________

 浙公网安备 33010602011771号
浙公网安备 33010602011771号