
【Python】【爬虫】【爬狼】004_正则规则模板及其应用
# 正则规则模板 与 应用(一)
先看这些视频,是在哪个div里面的
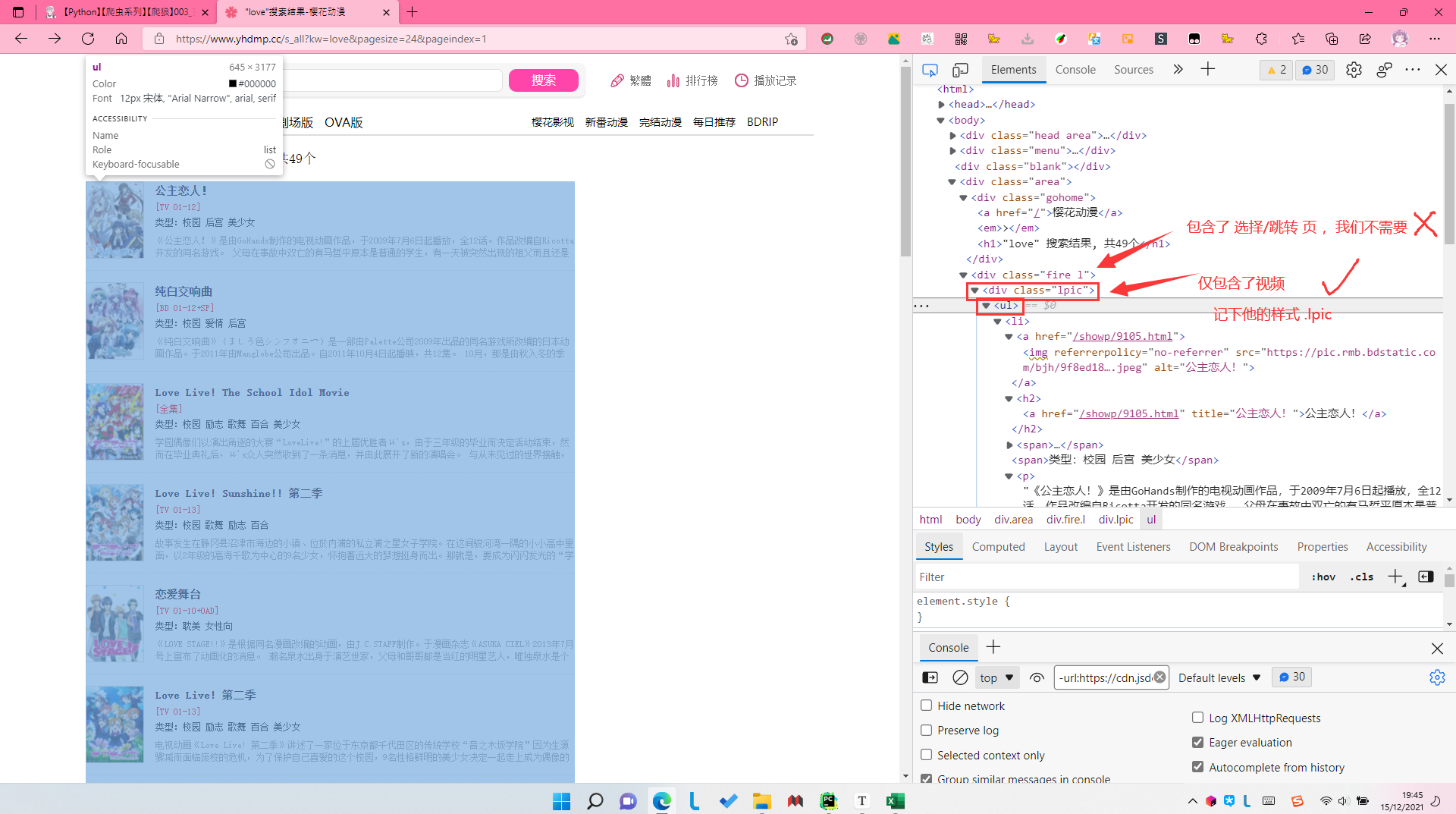
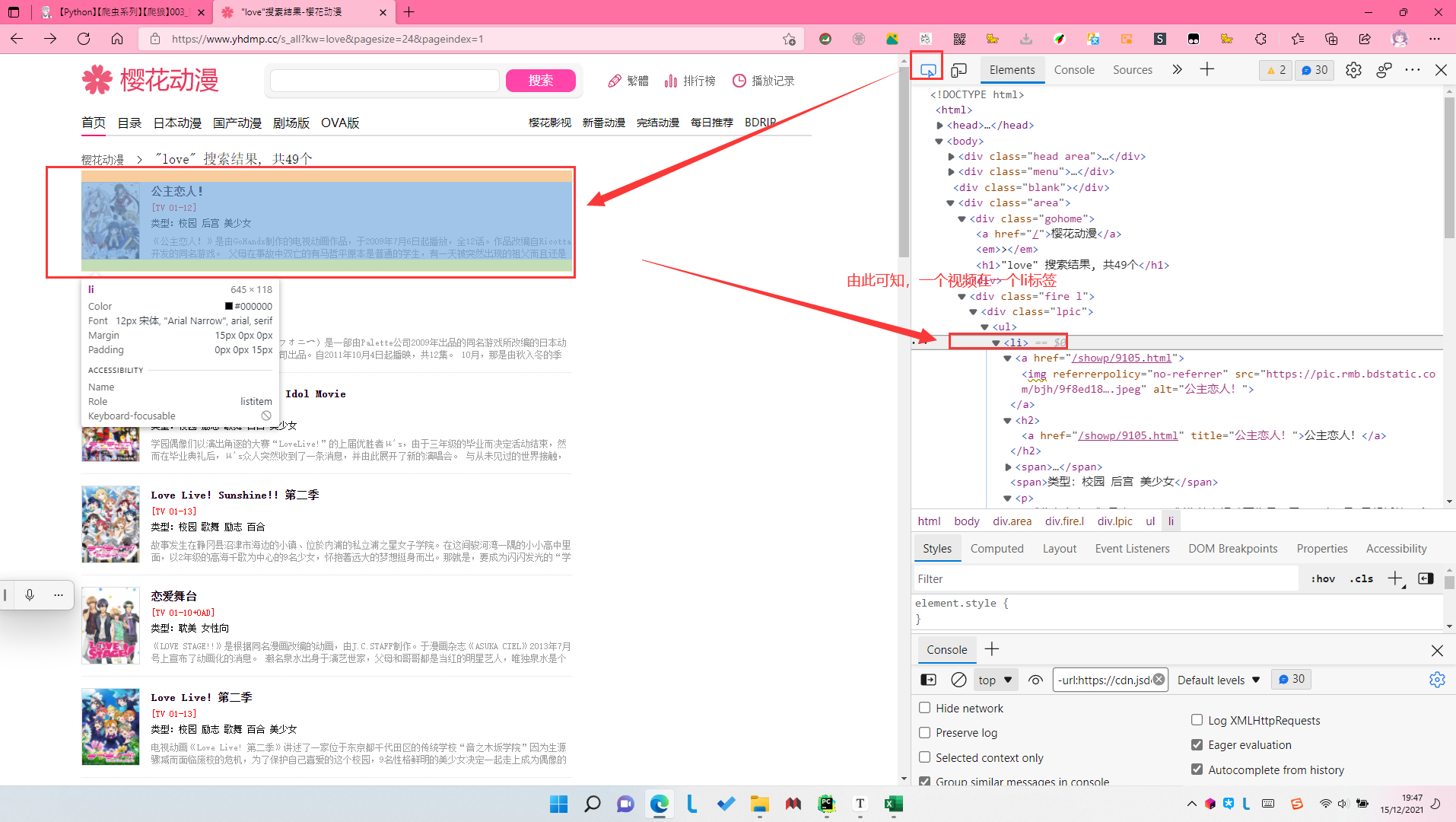
for datapage in soup.find_all("div", class_="lpic"):
# 一个li标签,包含一个视频
for data in datapage.find_all("li"):
# 不知道soup代表着什么,没关系,也别急着写,继续往后看
我们要获取的是
1.视频的标题
2.视频的类型
3.视频的介绍
4.视频的详情页链接
5.视频的封面图链接
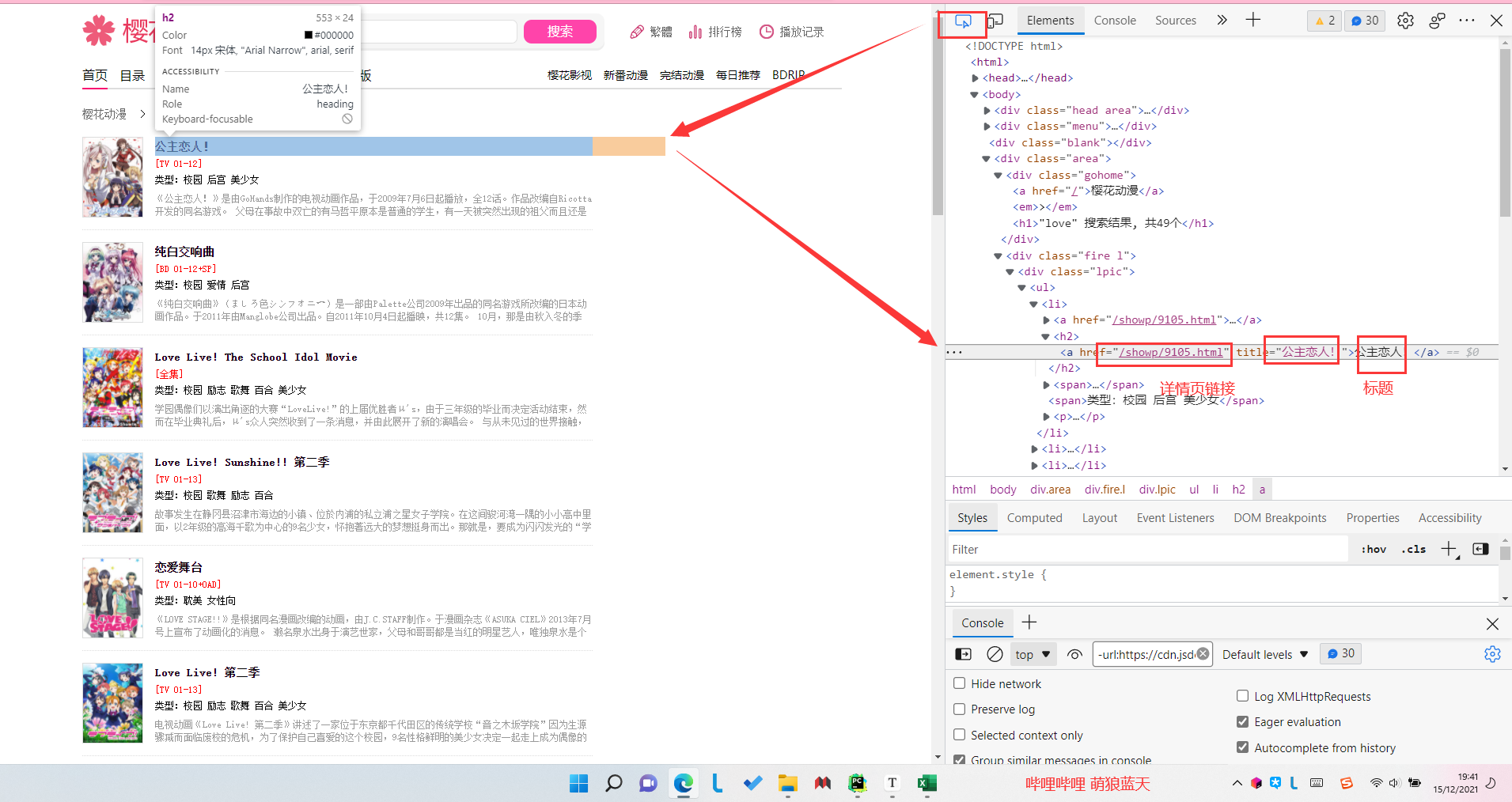
正则规则模板
# 正则规则开始
gz_fan_title = re.compile(r'''<a href=".*?" title=".*?">(.*?)</a>''',re.S)
gz_fan_url = re.compile(r'''<a href="(.*?)"''',re.S)
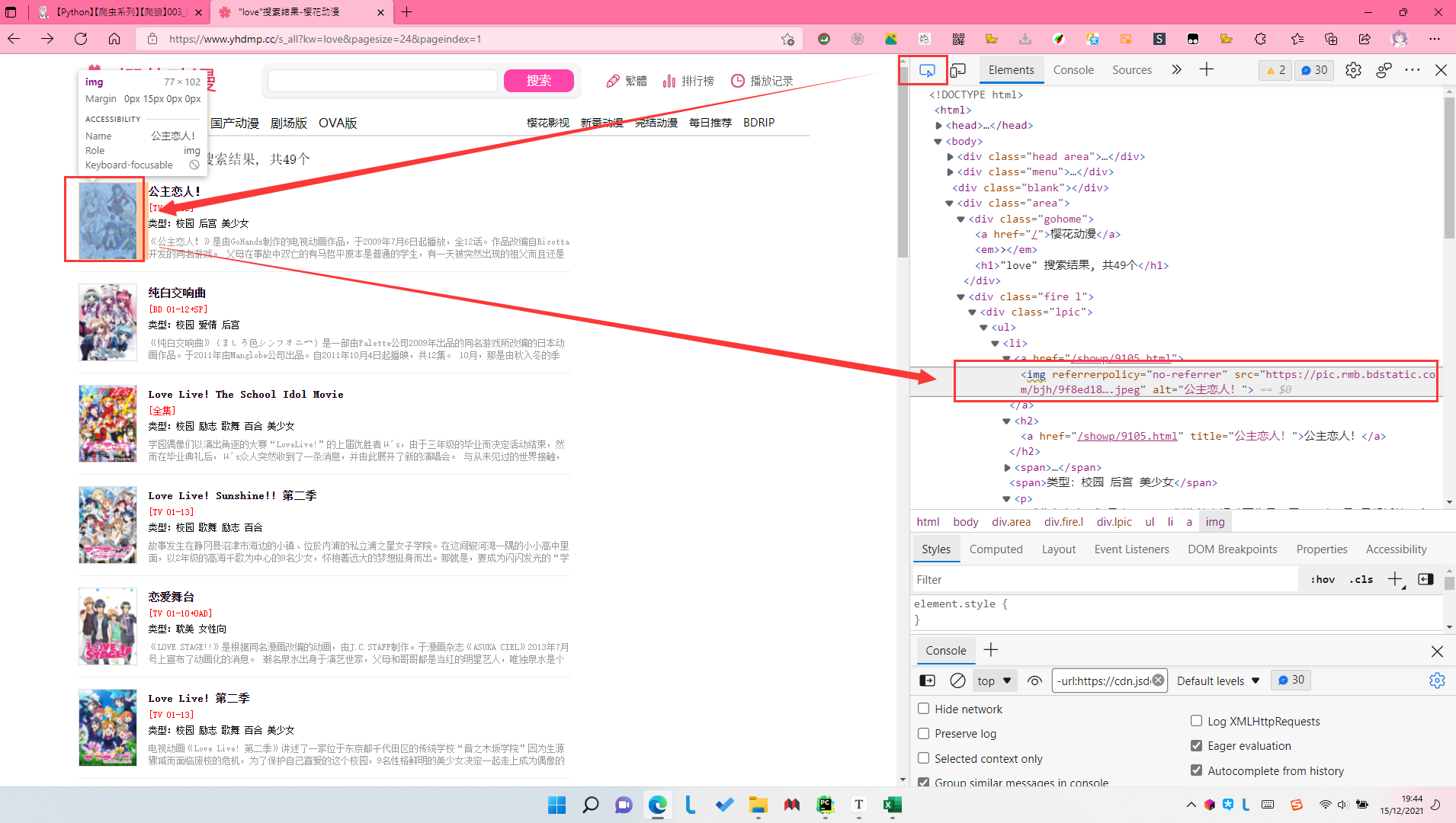
gz_fan_url_img = re.compile(r'''referrerpolicy="no-referrer" src="(.*?)"''',re.S)
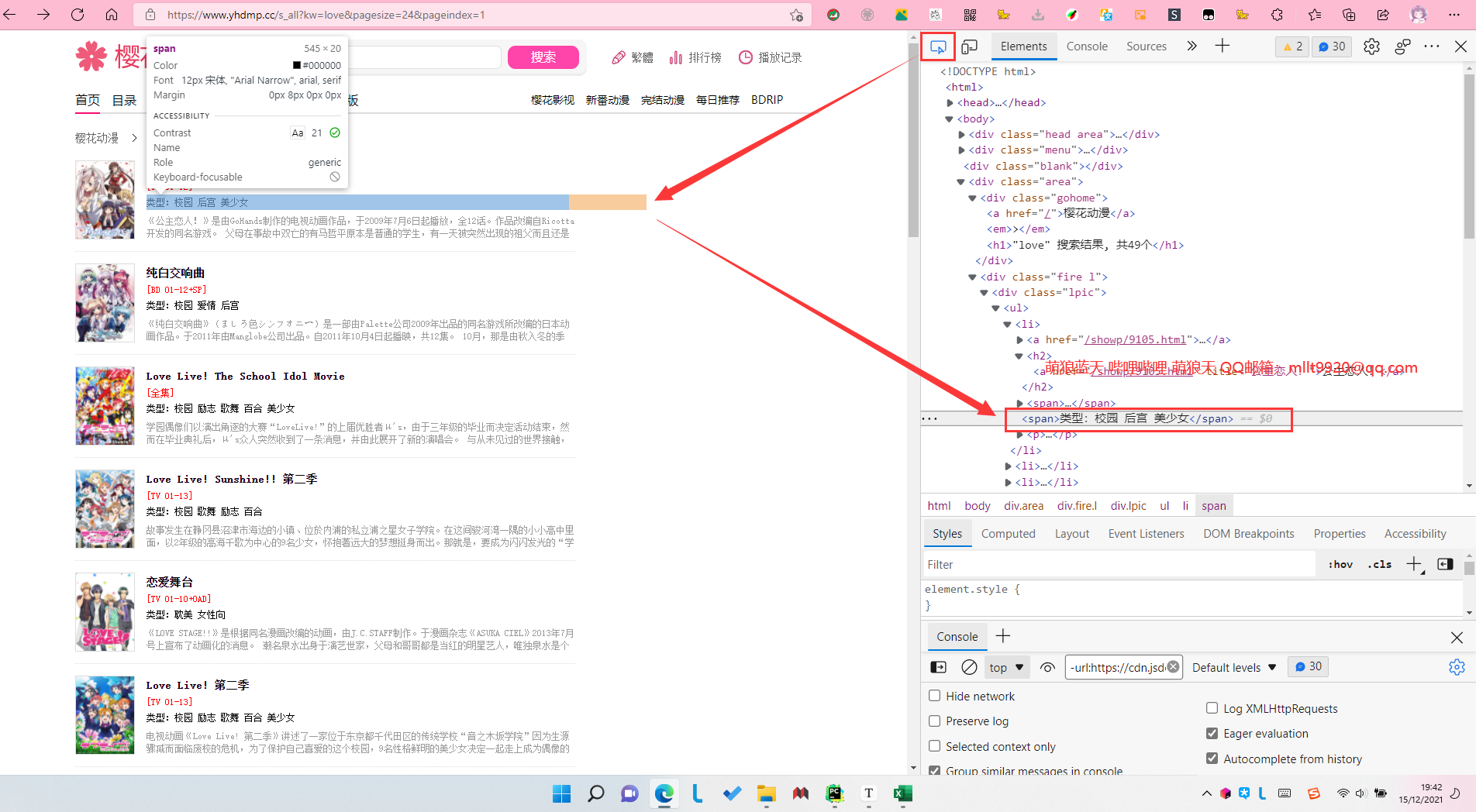
gz_fan_type = re.compile(r'''<span>类型:(.*?)</span>''',re.S)
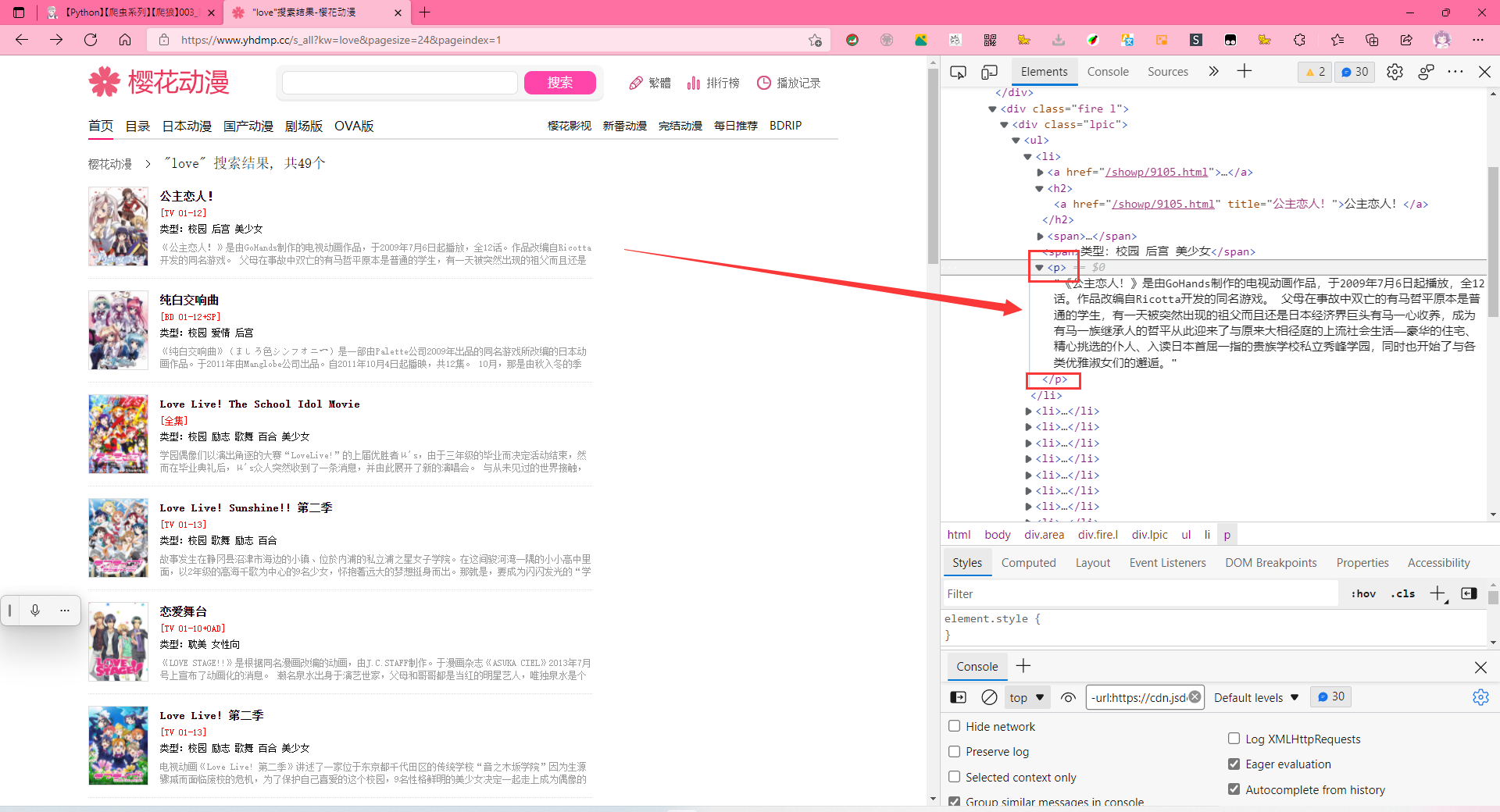
gz_fan_message = re.compile(r'''<p>(.*?)</p>''', re.S)
# 正则规则结束
应用正则规则模板
data = str(data)
fan_title = re.findall(gz_fan_title, data)
fan_url = re.findall(gz_fan_url, data)
fan_img = re.findall(gz_fan_url_img, data)
fan_type = re.findall(gz_fan_type, data)
fan_message = re.findall(gz_fan_message, data)
那么上面的data是什么,怎么获得呢?
# 假设搜索love
pageNumber = xrilag_SearchAll("love")
# xrilag_SearchAll是自定义函数,想了解其具体代码的请查看博客https://www.cnblogs.com/mllt/p/python_pc_pl_edu_003.html
# pageNumber是搜索结果的总页数
# 使用for循环,一页一页进行处理
for page in range(pageNumber):
# 根据页面跳转的地址改变规则写出页面含变量链接,然后进行源码获取,后面便可以对这一页展开分析与爬取数据了(https://www.cnblogs.com/mllt/p/python_pc_pl_edu_003.html)
html_Document = xrilang_UrlToDocument("https://www.yhdmp.cc/s_all?kw=love&pagesize=24&pageindex=" + str(page))
# xrilang_UrlToDocument是自定义函数,作用是获取网页源码。想了解其具体内容,请查看博客https://www.cnblogs.com/mllt/p/python_pc_pl_edu_002.html
# 创建一个Beautiful Soup对象
soup = BeautifulSoup(html_Document, "html.parser") # parser是解释器
# 使用了.kpic样式的div,包含且只包含了此页的所有视频列表
for datapage in soup.find_all("div", class_="lpic"):
# 一个li标签,包含一个视频
for data in datapage.find_all("li"):
# 应用正则规则模板
data = str(data)
fan_title = re.findall(gz_fan_title, data)
fan_url = re.findall(gz_fan_url, data)
fan_img = re.findall(gz_fan_url_img, data)
fan_type = re.findall(gz_fan_type, data)
fan_message = re.findall(gz_fan_message, data)
版 权 声 明
作者:萌狼蓝天
QQ:3447902411(仅限技术交流,添加请说明方向)
转载请注明原文链接:https://www.cnblogs.com/zwj/p/python_pc_pl_edu_004.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号