
【Python】【爬虫】【爬狼】003_获取搜索结果的页数
# 获取搜索内容的页数
需要的包
import urllib.request # 获取网页源码
import re # 正则表达式,进行文字匹配
from bs4 import BeautifulSoup # 解析网页
解析网页
第一步,解析网页为网页源码(【Python】【爬虫系列】【爬狼】002_自定义获取网页源码的函数 - 萌狼蓝天 - 博客园 (cnblogs.com/mllt))
# 获取网页源码
response_html = xrilang_UrlToDocument(Url)
# xrilang_UrlToDocument是我自定义函数,如果你没写这个函数,直接使用,会报错的。
# 如果你想了解这个函数的具体内容,请看【爬狼系列】笔记第002篇
获取搜索内容的页数
分析网页

切换页数,观察地址栏变化。
根据观察第二页、第三页链接如下
# 第二页
https://www.yhdmp.cc/s_all?kw=love&pagesize=24&pageindex=1
# 第三页
https://www.yhdmp.cc/s_all?kw=love&pagesize=24&pageindex=2
由此可以推测出,第一页的地址为
https://www.yhdmp.cc/s_all?kw=love&pagesize=24&pageindex=0
s_all:Search All 搜索全部
kw:Key Word
pagesize:页面大小(一页有多少个视频)
pageindex:页面索引(索引从0开始,代表页数。索引0是第一页,索引1是第二页,以此类推)
获取视频数量

此处会显示视频数量,我们只需取出这个“数字”就可以了。
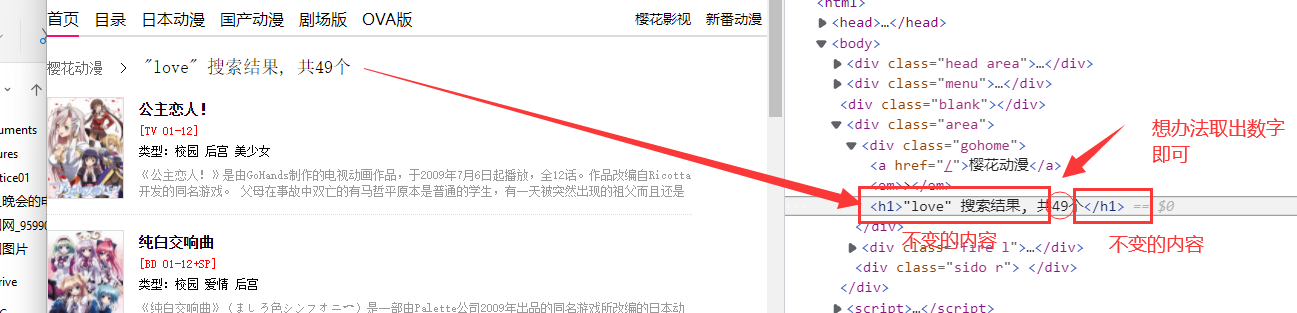
方法1
# 1.获取所搜结果视频数量
reStr1 = r'''搜索结果, 共(.*?)个''' # 正则规则
# temp = re.findall(reStr1, response_html) # 在 response_html 中查找符合上述正则规则(reStr1)的内容
# 运行结果为:['49']
mvNumber = re.findall(reStr1, response_html)[0] # 取出列表的第一项(索引为0) 设置变量mvNumber(搜索得到的视频数量)
# 运行结果为:49
方法2(推荐使用)
# 1.获取所搜结果视频数量
reStr1 = re.compile(r'''搜索结果, 共(.*?)个''') # 正则规则
# temp = re.findall(reStr1, response_html) # 在 response_html 中查找符合上述正则规则(reStr1)的内容
# 运行结果为:['49']
mvNumber = re.findall(reStr1, response_html)[0] # 取出列表的第一项(索引为0) 设置变量mvNumber(搜索得到的视频数量)
# 运行结果为:49
通过视频数量获取页数
通过分析,我们知道,一页有24个视频,视频总数在上面已经求出来了,那么会有多少页呢,这就是一个小学的题了。
视频总数/每页展示视频数=总页数
即:视频总数/24=总页数
注意,如果有余数,则直接+1,结果为整数
# 通过视频数量判断有多少页
# pageNumber = int(mvNumber) / 24
# 运行结果为:2.0416666666666665
# 求出页数
if (int(mvNumber) % 24) == 0:
pageNumber = int(mvNumber) / 24
else:
pageNumber = int(int(mvNumber) / 24) + 1
# 最终得到页数结果 pageNumber
# mvNumber是视频总数
将此功能编写为函数
为了方便求页数,我们需要将次功能编写为函数方便我们使用
def xrilag_SearchAll(keyword):
"""
'获取搜索内容的总页数'
:param keyword:搜索的关键字
:return:int 搜索结果的总页数
"""
# 基础链接
baseUrl = "https://www.yhdmp.cc/s_all?ex=1&kw="
Url = baseUrl + keyword
# 获取网页源码
response_html = xrilang_UrlToDocument(Url)
# 1.获取所搜结果视频数量
reStr1 = re.compile(r'''搜索结果, 共(.*?)个''') # 正则规则
# temp = re.findall(reStr1, response_html) # 在 response_html 中查找符合上述正则规则(reStr1)的内容
# 运行结果为:['49']
mvNumber = re.findall(reStr1, response_html)[0] # 取出列表的第一项(索引为0) 设置变量mvNumber(搜索得到的视频数量)
# 运行结果为:49
# 通过视频数量判断有多少页
# pageNumber = int(mvNumber) / 24
# 运行结果为:2.0416666666666665
# 求出页数
if (int(mvNumber) % 24) == 0:
pageNumber = int(mvNumber) / 24
else:
pageNumber = int(int(mvNumber) / 24) + 1
# 最终得到页数结果 pageNumber
return pageNumber
学习本文,最重要的是学习思维和处理方式
版 权 声 明
作者:萌狼蓝天
QQ:3447902411(仅限技术交流,添加请说明方向)
转载请注明原文链接:https://www.cnblogs.com/zwj/p/python_pc_pl_edu_003.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号