mysql 取出分组后价格最高的数据
如何用mysql 取出分组后价格最高的数据 ?
看到这个问题,就想到了用 max 函数和 group by 函数,先 group by 然后取得 max, 但是这样真的可以吗? 不可以 !
为什么? 因为要了解 :group by 后,select 取出的默认只是每个分组的第一条数据,但是这条数据和选出的 max,很有可能并不是同一条中的。
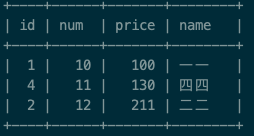
比如我们表的内容是这样的:
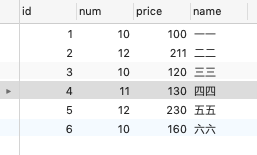
尝试一(失败)
执行sql语句 select * from test_group group by num; 得到的结果:
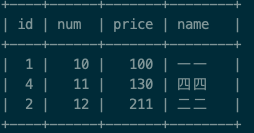
执行sql语句 select * , max(price) from test_group group by num; 得到的结果:
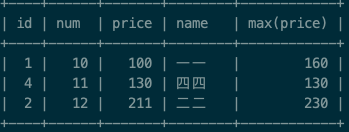
发现 max price 的价格和当前这条数据的实际价格根本对应不起来。由此可见: 这种写法其实是错误的,取出来的数据没有任何含义
尝试二(失败)
在网上看到这样一种写法:既然分组就取第一条数据,那我们先把表排序,再从排序的表中去分组取第一条数据
select * from test_group order by price desc;
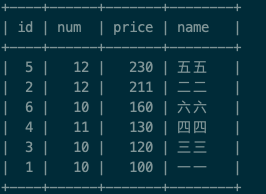
再从这个表中去分组取得第一条数据:select * from (select * from test_group order by price desc) as s group by s.num;
经过实际试验后,发现结果并不对,看一位博主介绍说,mysql 5.7之后对于这个顺序好像进行改变了,所以使用这个语句要特别小心mysql版本。
尝试三(失败)
另外还有一种写法是:先取得每个num下最大的price, 再根据得到的price去找对应的数据
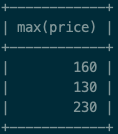
select max(price) from test_group group by num;
select * from test_group where price in (select max(price) from test_group group by num);
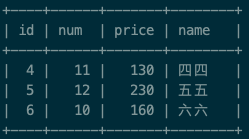
看起来可以了,是取出的每组下面最大的数据,但是如果遇到下面这种情况就会有问题啦!
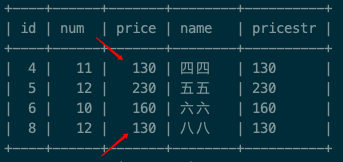
我们加了八八这条数据,属于 12 组下 价格为130的数据,这样最终的结果 四四 和 八八都被筛选出来了 !!因为我们筛选出来的max(price) 有130,而八八的价格恰好是130。

优化尝试三(成功)
可以优化下上面这条sql:我们选择max(price)时还把对应的组也筛选出来,去判断两个的num也是相同的,这就需要做一个表的连接
首先得到num及num下的最高价格:select num, max(price) as max_price from test_group group by num;
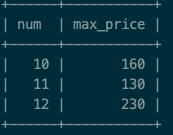
将上面的子表与原表进行连接,条件是num和price都要相同,得到结果如下:
select * from test_group as s1 left join (select num, max(price) as max_price from test_group group by num) as s2 on s1.num=s2.num and s1.price=s2.max_price;

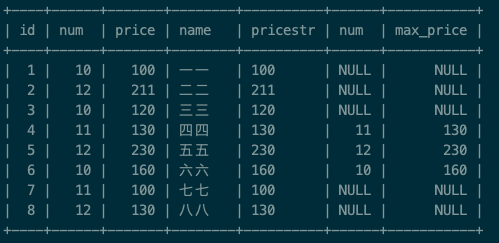
然后我们筛选出s2.num 不为空的数据即可
select s1.id as id, s1.num as num, s1.price as price, s1.name as name from test_group as s1 left join (select num, max(price) as max_price from test_group group by num) as s2 on s1.num=s2.num and s1.price=s2.max_price where s2.num is not null;
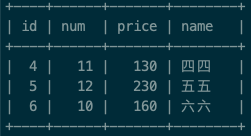
尝试四(成功)
我们将表自连接,连接条件是:1的价格<2的价格并且部门相同,这样的话那些价格最高的不会有数据和它连接,最后筛选2中id is null 的数据就可以了
先将表自连接:select * from test_group s1 left join test_group s2 on s1.price < s2.price and s1.num=s2.num;
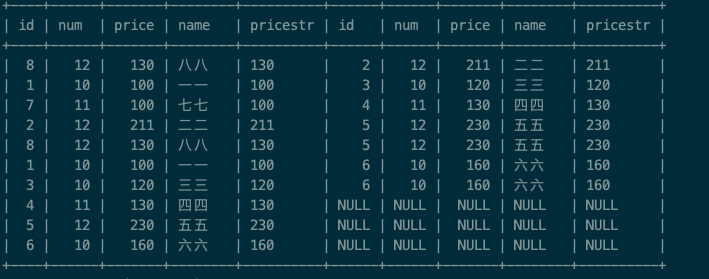
筛选 s2.id is null 的数据:
select s1.id as id, s1.num as num, s1.price as price, s1.name as name from test_group s1 left join test_group s2 on s1.price < s2.price and s1.num=s2.num where s2.id is null;
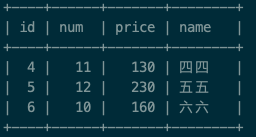
这样得到的结果和上面也一样
尝试五(未经过测试)
使用partition by函数来实现,但是这个函数只在mysql 8版本上运行,我的是5.7,太低了,运行不起来,没有经过验证。 这个函数也可以用在hive表中
over(partition by num order by price desc) : 这个语句的意思是先按照 num 进行分组,组内再按照price进行排序
row_number()over(partition by cno order by degree desc) mm: 这个语句的意思是对于上面的结果每组内进行编号,且这列编号列名为 mm
SELECT *
FROM (select sno,cno,degree,
row_number()over(partition by cno order by degree desc) mm
from score)
where mm = 1;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号