
爬虫-获取中信证券产品信息
import requests
from lxml import etree
import time
import re
'''
功能描述:手动输入抓取页数,将获取的产品名称、管理人等信息数据,并生成excel
'''
# 定义抓取方法
def get_url(url):
res = requests.get(url, headers=headers)
content = res.content.decode()
tree = etree.HTML(content)
a_list = tree.xpath('/html/body/div[4]/div/ul/li')
time.sleep(0.1)
with open('./证券数据.csv', 'a') as f:
for item in a_list:
name = item.xpath('./span/text()')[:-1]
# print(','.join(name))
f.write(','.join(name))
# f.write('\r\n')
f.write('\r')
if __name__ == '__main__':
# 先抓一次,获取到最大页
url = "http://www.cs.ecitic.com/newsite/cpzx/jrcpxxgs/zgcp/index.html"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36"
}
page_res = requests.get(url, headers=headers)
page_res.encoding = page_res.apparent_encoding
data = page_res.text
# 整数、page页,传入data页面源码,group提取page
total_num = int(re.search('var countPage = (?P<page>\d+)//共多少页', data).group('page'))
page_num = int(input('请输入抓取页码数:'))
for i in range(page_num):
url = f'http://www.cs.ecitic.com/newsite/cpzx/jrcpxxgs/zgcp/index_{i}.html'
if i == 0:
url = 'http://www.cs.ecitic.com/newsite/cpzx/jrcpxxgs/zgcp/index.html'
get_url(url)
time.sleep(0.1)
效果展示:

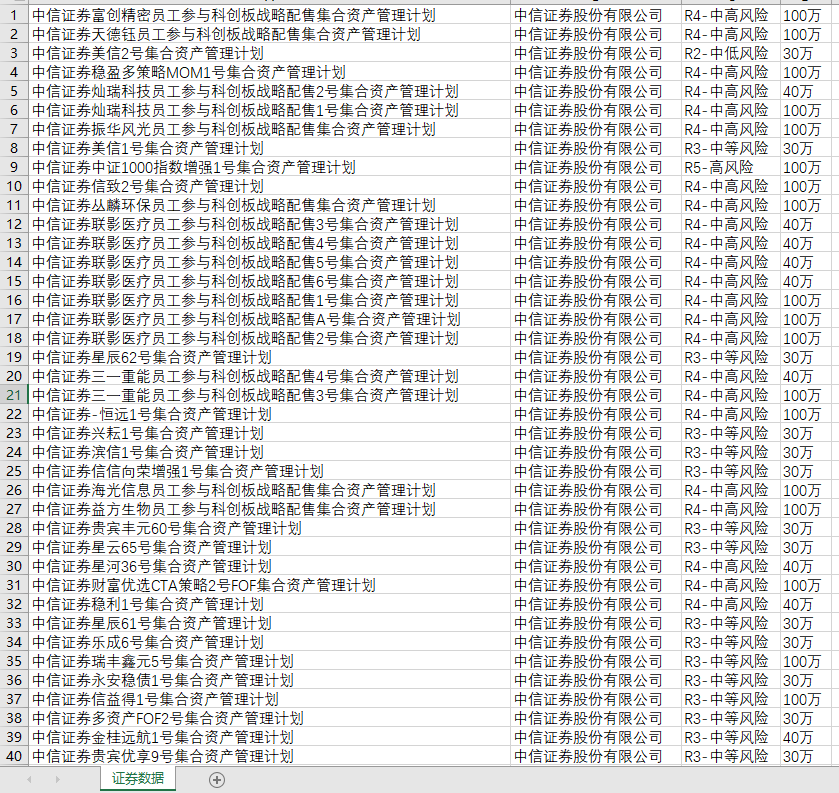
待完善。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号