Interactive Crawler工具的使用
交互式爬虫是我之前一直想要尝试去做的一个东西,但由于时间问题一直都没有做,最近正好有点时间,写了初版上传到了github上,项目地址:https://github.com/smlins/Interactive-Crawl ,感兴趣的师傅们可以用用,有其他问题或建议在github上或留言都行,我有时间就去完善。
在我印象里,传统的爬虫就是简单的爬取页面上的超链接,但没有办法获取到页面触发事件所产生的http请求和响应,随着科技的发展,其实这种动态爬虫技术早在几年前就已经存在了,只是我们一直没有关注而已,不管怎样先接触下皮毛,再去深入了解。
一、简介
Interactive Crawler是一款交互式爬虫工具,不仅可以爬取页面中的超链接,还能获取通过页面的各种交互事件触发所发起的请求,支持代理设置,可结合其他漏洞扫描工具使用,目前支持以下事件的触发:
- Form表单的填写去自动提交;
- 获取页面的onclick事件并触发该事件;
- 触发a标签中JavaScript代码;
当然还有以下事件的触发未实现:
-
获取所有按钮并点击触发;
如果按钮不是通过JavaScript代码中绑定事件的基本上也都能触发, 因为button不像submit标签一样,button需要
onclick或其他事件来完成事件触发。 -
也可能还有类似于
onmousedown、onmouseup等事件的获取和触发; -
非form表单的输入框输入已经表单提交;
-
带有事件的隐藏标签触发;
还有很多,只能通过平时不断的实践来收集和完善功能。
二、安装
从github上下载此项目:
git clone https://github.com/smlins/Interactive-Crawl.git
进入目录并安装运行该项目所需要的模块:
cd Interactive-Crawl && pip install -r requirements.txt
最后就可以运行该项目
python crawler.py http://example.com
可通过python crawler.py -h来查看一些可选参数
可选参数:
-h, --help 帮助显示此帮助消息并退出
-t , --timeout 所有页面请求的超时时间,默认为5秒
--cookie 设置http请求Cookie
--proxy-server 设置爬虫的代理地址,爬虫会将所有请求转发至该服务端口
--headless 浏览器的无头操作模式,添加此选项后不会显示浏览器界面
--exclude-links 如果链接包含此关键字,支持正则表达式
--crawl-link-type 爬网程序爬网的网络资源类型,默认爬取xhr、fetch、document
--prohibit-load-type 禁止加载的网络资源类型,默认禁止加载image,media,font,manifest,该配置选项是优先级最高的
--crawl-external-links 设置是否爬取外部链接爬网,默认情况下,仅对同一网站链接进行爬网(不推荐)
--intercept-request 开启http请求拦截,只有当该选项开启后,--prohibit-load-type参数才生效
三、用法
1. 基础用法
# 本次演示爬取本地搭建的dvwa页面,与logout有关的链接和事件一律不触发(不退出登陆),另外带上Cookie
python crawler.py http://192.168.88.150:8080 --exclude-links="logout" --cookie="csrftoken=adr5Tc4LBxVQkwKngnCuZvP1iAO9YtT4GhwgqodBn7JzdFE5sxjcC6crZhwKcqCf; sessionid=0j0ko147842bpojsxcv4yu3038yr2gxo; PHPSESSID=vgcnl569r3rlncuvt0hb4gqe87; security=impossible"
- 若无需显示浏览器界面,在后面加上
--headless即可;- 若网页图片等媒体资源加载过慢时,可加上
--intercept-request参数禁止其加载,从而加快页面加载;
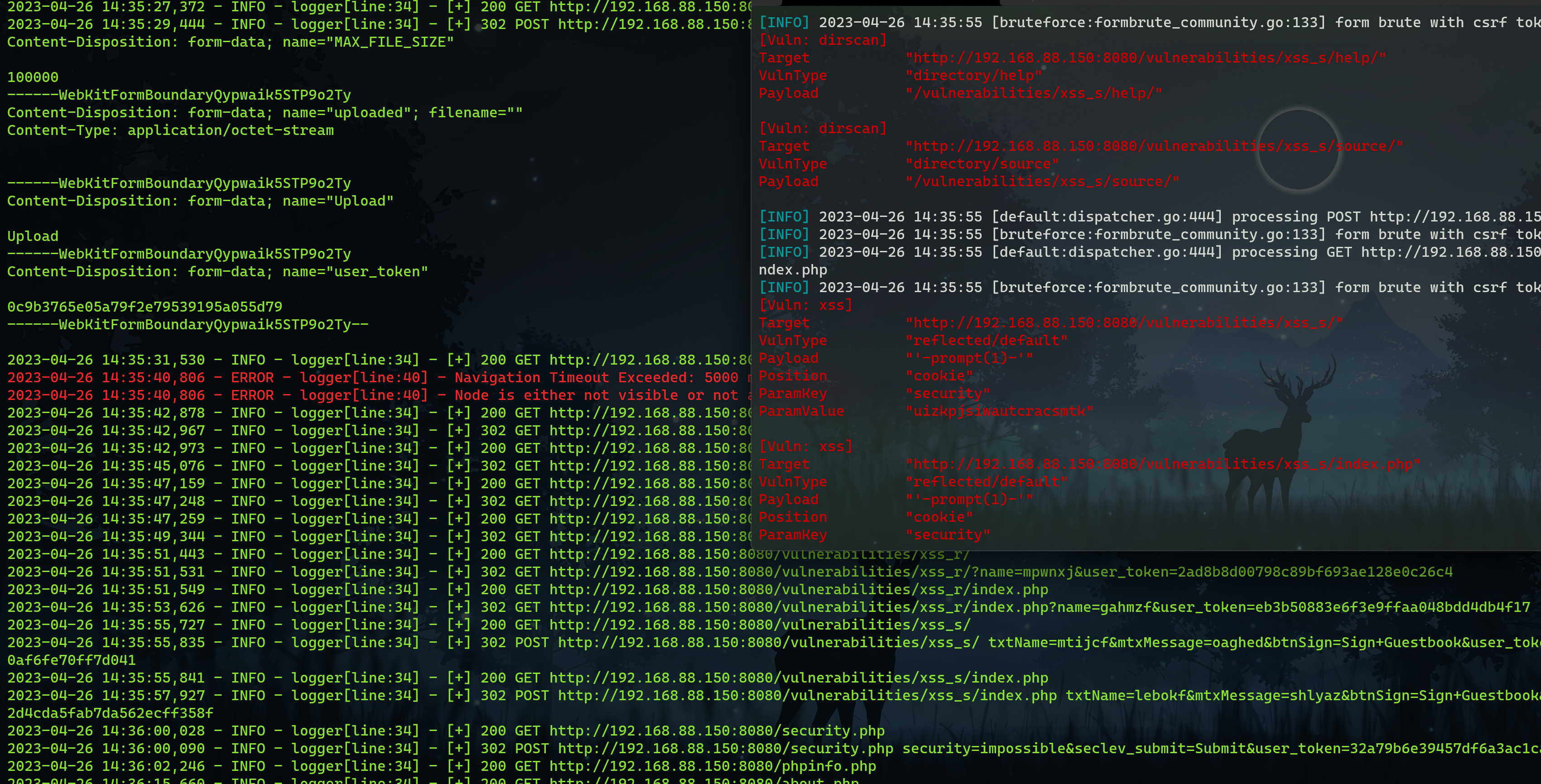
2. 结合xray进行漏洞扫描
# 以被动扫描模式启动xray
./xray webscan --listen 127.0.0.1:8080 --html-output test.html
# 以代理模式启动爬虫且无需启动浏览器界面
python crawler.py http://192.168.88.150:8080 --exclude-links="logout" --cookie="csrftoken=adr5Tc4LBxVQkwKngnCuZvP1iAO9YtT4GhwgqodBn7JzdFE5sxjcC6crZhwKcqCf; sessionid=0j0ko147842bpojsxcv4yu3038yr2gxo; PHPSESSID=vgcnl569r3rlncuvt0hb4gqe87; security=impossible" --proxy-server="127.0.0.1:8080" --headless
四、问题总结
该爬虫脚本主要是采用Python的pyppeteer模块编写,目前只支持单个网站的线性爬取,速度较慢,日后再寻思将优化方案。Python也有一些局限性,例如多线程只能并发无法做到并行,故i/o编程使用协程是最优方案,pyppeteer本身也存在一些问题尚未修复,自己还是得研究下Chrome Devtools协议的使用,对于爬虫这块自己其实还有很多其他想法都还没有实现,又或者以后也可能会用Golang语言来重写这个工具。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号