Python爬虫之Scrapy框架的UA池和代理池
一 下载Scrapy的下载中间件
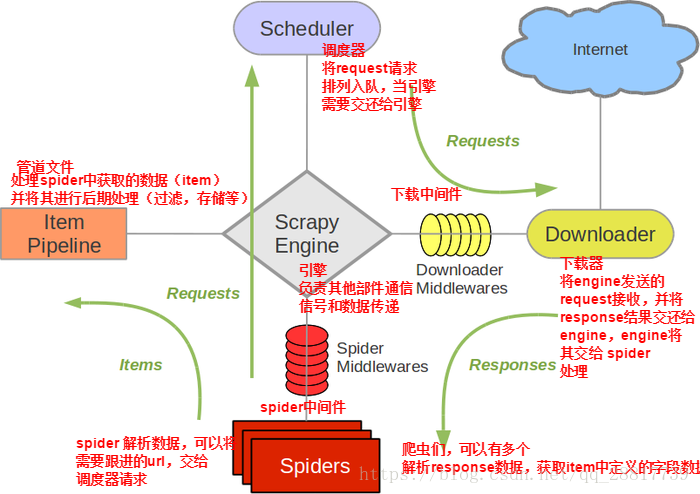
下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件。
下载中间件的作用:
(1)引擎请求传递给下载器的过程中,下载中间件可以对请求进行一系列处理。比如:设置User-Agent,设置代理等。
(2)在下载器完成将Response传递给引擎中,下载中间件可以对响应进行一系列的处理。
我们主要使用下载中间件处理请求,设置随机的代理IP,对请求设置随机的User-Agent。目的在于防止爬取网站时的反爬虫策略。
二 UA池:User-Agent
作用是:尽量将scrapy工程中的请求伪装成不同类型的浏览器身份。
步骤如下:
(1) 在下载中间件中拦截请求
(2)将拦截到的请求的请求信息中的UA进行篡改伪装
(3)在配置文件中开启下载中间件
middlewares.py中
import random
class MiddleproDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 "
"(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
#拦截所有未发生异常的请求(正常的请求)
def process_request(self, request, spider):
print('process_request')
# 使用UA池进行请求的UA伪装
#请求头信息 获取到的是字典
#这一步可有可无 因为你可以在settings中设置一个共同的User-Agent
request.headers['User-Agent'] = random.choice(self.user_agent_list)
print(request.headers['User-Agent'])
return None
三 代理池
作用是:将Scrapy工程中的请求中的IP设置成不同的
步骤:(与UA池基本上是一样的)
(1)在下载中间件中拦截请求
(2) 将拦截到的请求中的IP修改成某一个代理的IP
(3)在配置文件中开启下载中间件
middlewares.py
class MiddleproDownloaderMiddleware(object):
#写两个列表 原因是代理IP的类型中有 http 和 https两种类型
# 可被选用的代理IP
PROXY_http = [
'153.180.102.104:80',
'195.208.131.189:56055',
]
PROXY_https = [
'120.83.49.90:9000',
'95.189.112.214:35508',
]
#拦截所有的异常请求
def process_exception(self, request, exception, spider):
#这一步是必须要用的 因为当你访问一个网站次数过多的时候 你可以使用代理IP继续爬取该网站的数据
## #使用代理池进行请求代理ip的设置
# request.url 返回的是请求对象所对应的URL
print('process_exception')
if request.url.split(':')[0] == 'http':
request.meta['proxy'] = random.choice(self.PROXY_http)
else:
request.meta['proxy'] = random.choice(self.PROXY_https)
在settings.py中将下载中间件打开即可
#在第55行
DOWNLOADER_MIDDLEWARES = {
'middlePro.middlewares.MiddleproDownloaderMiddleware': 543,
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号