
List,set,Map理解
集合
集合与数组
数组(可以存储基本数据类型)是用来存现对象的一种容器,但是数组的长度固定,不适合在对象数量未知的情况下使用。
集合(只能存储对象,对象类型可以不一样)的长度可变,可在多数情况下使用。
集合中接口和类的关系
Collection接口是集合类的根接口,Java中没有提供这个接口的直接的实现类。但是却让其被继承产生了两个接口,就是Set和List。Set中不能包含重复的元素。List是一个有序的集合,可以包含重复的元素,提供了按索引访问的方式。
Map是Java.util包中的另一个接口,它和Collection接口没有关系,是相互独立的,但是都属于集合类的一部分。Map包含了key-value对。Map不能包含重复的key,但是可以包含相同的value。
Iterator所有的集合类,都实现了Iterator接口,这是一个用于遍历集合中元素的接口,主要包含以下三种方法:
1.hasNext()是否还有下一个元素。
2.next()返回下一个元素。
3.remove()删除当前元素。
大致继承关系如下(图片来自网络)
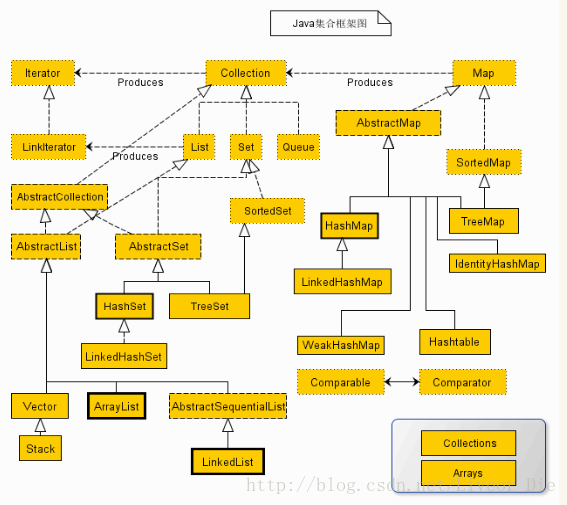

list,set,map对比
| 接口 | 子接口 | 是否有序 | 是否允许元素重复 |
|---|---|---|---|
| Collection | 是 | ||
| List | ArrayList | 是 | 是 |
| LinkedList | 是 | 是 | |
| Vector | 是 | 是 | |
| Set | AbstractSet | 否 | 否 |
| HashSet | 否 | 否 | |
| TreeSet | 是(用二叉排序树) | 否 | |
| Map | AbstractMap | 否 | 使用key-value来映射和存储数据,key必须唯一,value可以重复 |
| HashMap | 否 | ||
| TreeMap | 是(用二叉排序树) | 使用key-value来映射和存储数据,key必须唯一,value可以重复 |
list(有序、可重复)
List里存放的对象是有序的,同时也是可以重复的,List关注的是索引,拥有一系列和索引相关的方法,查询速度快。因为往list集合里插入或删除数据时,会伴随着后面数据的移动,所有插入删除数据速度慢。
ArrayList
ArrayList是基于数组的,在初始化ArrayList时,会构建空数组(Object[] elementData={})。ArrayList是一个无序的,它是按照添加的先后顺序排列,当然,他也提供了sort方法,如果需要对ArrayList进行排序,只需要调用这个方法,提供Comparator比较器即可
add操作:
1)如果是第一次添加元素,数组的长度被扩容到默认的capacity,也就是10.
2) 当发觉同时添加一个或者是多个元素,数组长度不够时,就扩容,这里有两种情况:
只添加一个元素,例如:原来数组的capacity为10,size已经为10,不能再添加了。需要扩容,新的capacity=old capacity+old capacity>>1=10+10/2=15.即新的容量为15。
当同时添加多个元素时,原来数组的capacity为10,size为10,当同时添加6个元素时。它需要的min capacity为16,而按照capacity=old capacity+old capacity>>1=10+10/2=15。new capacity小于min capacity,则取min capacity。
对于添加,如果不指定下标,就直接添加到数组后面,不涉及元素的移动,如果要添加到某个特定的位置,那需要将这个位置开始的元素往后挪一个位置,然后再对这个位置设置。
Remove操作:
Remove提供两种,按照下标和value。
1)remove(int index):首先需要检查Index是否在合理的范围内。其次再调用System.arraycopy将index之后的元素向前移动。
2)remove(Object o):首先遍历数组,获取第一个相同的元素,获取该元素的下标。其次再调用System.arraycopy将index之后的元素向前移动。
Get操作:
这个比较简单,直接对数组进行操作即可。
LinkedList
LinkedList是基于链表的,它是一个双向链表,每个节点维护了一个prev和next指针。同时对于这个链表,维护了first和last指针,first指向第一个元素,last指向最后一个元素。LinkedList是一个无序的链表,按照插入的先后顺序排序,不提供sort方法对内部元素排序。
Add元素:
LinkedList提供了几个添加元素的方法:addFirst、addLast、addAll、add等,时间复杂度为O(1)。
Remove元素:
LinkedList提供了几个移除元素的方法:removeFirst、removeLast、removeFirstOccurrence、remove等,时间复杂度为O(1)。
Get元素:
根据给定的下标index,判断它first节点、last直接距离,如果index<size(数组元素个数)/2,就从first开始。如果大于,就从last开始。这个和我们平常思维不太一样,也许按照我们的习惯,从first开始。这也算是一点小心的优化吧。
遍历
在类集中提供了以下四种的常见输出方式:
1)Iterator:迭代输出,是使用最多的输出方式。
2)ListIterator:是Iterator的子接口,专门用于输出List中的内容。
3)foreach输出:JDK1.5之后提供的新功能,可以输出数组或集合。
4)for循环
代码示例如下:
for的形式:for(int i=0;i<arr.size();i++){...}
foreach的形式: for(int i:arr){...}
iterator的形式:
Iterator it = arr.iterator();
while(it.hasNext()){ object o =it.next(); ...}
Set(无序、不能重复)
Set里存放的对象是无序,不能重复的,集合中的对象不按特定的方式排序,只是简单地把对象加入集合中。
HashSet
HashSet是基于HashMap来实现的,操作很简单,更像是对HashMap做了一次“封装”,而且只使用了HashMap的key来实现各种特性,而HashMap的value始终都是PRESENT。
HashSet不允许重复(HashMap的key不允许重复,如果出现重复就覆盖),允许null值,非线程安全。
构造方法
HashSet()
构造一个新的空 set,其底层 HashMap 实例的默认初始容量是 16,加载因子是 0.75。
HashSet(Collection<? extends E> c)
构造一个包含指定 collection 中的元素的新 set。
HashSet(int initialCapacity)
构造一个新的空 set,其底层 HashMap 实例具有指定的初始容量和默认的加载因子(0.75)。
HashSet(int initialCapacity, float loadFactor)
构造一个新的空 set,其底层 HashMap 实例具有指定的初始容量和指定的加载因子。
方法
boolean add(E e)
如果此 set 中尚未包含指定元素,则添加指定元素。
void clear()
从此 set 中移除所有元素。
** Object clone()
返回此 HashSet 实例的浅表副本:并没有复制这些元素本身。
boolean contains(Object o)
如果此 set 包含指定元素,则返回 true。
boolean isEmpty()**
如果此 set 不包含任何元素,则返回 true。
** Iterator iterator()
返回对此 set 中元素进行迭代的迭代器。
boolean remove(Object o)
如果指定元素存在于此 set 中,则将其移除。
int size()**
返回此 set 中的元素的数量(set 的容量)。
TreeSet
基于 TreeMap 的 NavigableSet 实现。使用元素的自然顺序对元素进行排序,或者根据创建 set 时提供的 Comparator进行排序,具体取决于使用的构造方法。
构造方法和方法比较类似就不说了
遍历(和list相似)
对 set 的遍历
1.迭代遍历:
Set<String> set = new HashSet<String>();
Iterator<String> it = set.iterator();
while (it.hasNext()) {
String str = it.next();
System.out.println(str);
} 2.for(foreach)循环遍历:
for (String str : set) {
System.out.println(str);
} Map(键值对、键唯一、值不唯一)
Map集合中存储的是键值对,键不能重复,值可以重复。根据键得到值,对map集合遍历时先得到键的set集合,对set集合进行遍历,得到相应的值。
HashMap
数组方式存储key/value,线程非安全,允许null作为key和value,key不可以重复,value允许重复,不保证元素迭代顺序是按照插入时的顺序,key的hash值是先计算key的hashcode值,然后再进行计算,每次容量扩容会重新计算所以key的hash值,会消耗资源,要求key必须重写equals和hashcode方法
默认初始容量16,加载因子0.75,扩容为旧容量乘2,查找元素快,如果key一样则比较value,如果value不一样,则按照链表结构存储value,就是一个key后面有多个value;
方法
1、添加:
V put(K key, V value) (可以相同的key值,但是添加的value值会覆盖前面的,返回值是前一个,如果没有就返回null)
putAll(Map<? extends K,? extends V> m) 从指定映射中将所有映射关系复制到此映射中(可选操作)。
2、删除
remove() 删除关联对象,指定key对象
clear() 清空集合对象
3、获取
value get(key) 可以用于判断键是否存在的情况。当指定的键不存在的时候,返回的是null。
4、判断:
boolean isEmpty() 长度为0返回true否则false
boolean containsKey(Object key) 判断集合中是否包含指定的key
boolean containsValue(Object value) 判断集合中是否包含指定的value
4、长度:
Int size()
map的主要的方法就这几个
Hashtable
Hashtable与HashMap类似,是HashMap的线程安全版,它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtale在写入时会比较慢,它继承自Dictionary类,不同的是它不允许记录的键或者值为null,同时效率较低。
LinkedHashMap
LinkedHashMap保存了记录的插入顺序,在用Iteraor遍历LinkedHashMap时,先得到的记录肯定是先插入的,在遍历的时候会比HashMap慢,有HashMap的全部特性。
TreeMap
基于红黑二叉树的NavigableMap的实现,线程非安全,不允许null,key不可以重复,value允许重复,存入TreeMap的元素应当实现Comparable接口或者实现Comparator接口,会按照排序后的顺序迭代元素,两个相比较的key不得抛出classCastException。主要用于存入元素的时候对元素进行自动排序,迭代输出的时候就按排序顺序输出
遍历
第一种:KeySet()
将Map中所有的键存入到set集合中。因为set具备迭代器。所有可以迭代方式取出所有的键,再根据get方法。获取每一个键对应的值。 keySet():迭代后只能通过get()取key 。
取到的结果会乱序,是因为取得数据行主键的时候,使用了HashMap.keySet()方法,而这个方法返回的Set结果,里面的数据是乱序排放的。
Map map = new HashMap();
map.put("key1","lisi1");
map.put("key2","lisi2");
map.put("key3","lisi3");
map.put("key4","lisi4");
//先获取map集合的所有键的set集合,keyset()
Iterator it = map.keySet().iterator();
//获取迭代器
while(it.hasNext()){
Object key = it.next();
System.out.println(map.get(key));
}第二种: values() 获取所有的值.
Collection values()不能获取到key对象
Collection<String> vs = map.values();
Iterator<String> it = vs.iterator();
while (it.hasNext()) {
String value = it.next();
System.out.println(" value=" + value);
}第三种:entrySet()
Set<Map.Entry<K,V>> entrySet() //返回此映射中包含的映射关系的 Set 视图。(一个关系就是一个键-值对),就是把(key-value)作为一个整体一对一对地存放到Set集合当中的。Map.Entry表示映射关系。entrySet():迭代后可以e.getKey(),e.getValue()两种方法来取key和value。返回的是Entry接口。
典型用法如下:
// 返回的Map.Entry对象的Set集合 Map.Entry包含了key和value对象
Set<Map.Entry<Integer, String>> es = map.entrySet();
Iterator<Map.Entry<Integer, String>> it = es.iterator();
while (it.hasNext()) {
// 返回的是封装了key和value对象的Map.Entry对象
Map.Entry<Integer, String> en = it.next();
// 获取Map.Entry对象中封装的key和value对象
Integer key = en.getKey();
String value = en.getValue();
System.out.println("key=" + key + " value=" + value);
} 推荐使用第三种方式,即entrySet()方法,效率较高。
对于keySet其实是遍历了2次,一次是转为iterator,一次就是从HashMap中取出key所对于的value。而entryset只是遍历了第一次,它把key和value都放到了entry中,所以快了。两种遍历的遍历时间相差还是很明显的。
总结:
Vector和ArrayList
1,vector是线程同步的,所以它也是线程安全的,而arraylist是线程异步的,是不安全的。如果不考虑到线程的安全因素,一般用arraylist效率比较高。
2,如果集合中的元素的数目大于目前集合数组的长度时,vector增长率为目前数组长度的100%,而arraylist增长率为目前数组长度的50%。如果在集合中使用数据量比较大的数据,用vector有一定的优势。
3,如果查找一个指定位置的数据,vector和arraylist使用的时间是相同的,如果频繁的访问数据,这个时候使用vector和arraylist都可以。而如果移动一个指定位置会导致后面的元素都发生移动,这个时候就应该考虑到使用linklist,因为它移动一个指定位置的数据时其它元素不移动。
ArrayList 和Vector是采用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,都允许直接序号索引元素,但是插入数据要涉及到数组元素移动等内存操作,所以索引数据快,插入数据慢,Vector由于使用了synchronized方法(线程安全)所以性能上比ArrayList要差,LinkedList使用双向链表实现存储,按序号索引数据需要进行向前或向后遍历,但是插入数据时只需要记录本项的前后项即可,所以插入数度较快。
arraylist和linkedlist
1.ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
2.对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
3.对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。 这一点要看实际情况的。若只对单条数据插入或删除,ArrayList的速度反而优于LinkedList。但若是批量随机的插入删除数据,LinkedList的速度大大优于ArrayList. 因为ArrayList每插入一条数据,要移动插入点及之后的所有数据。
HashMap与TreeMap
1、 HashMap通过hashcode对其内容进行快速查找,而TreeMap中所有的元素都保持着某种固定的顺序,如果你需要得到一个有序的结果你就应该使用TreeMap(HashMap中元素的排列顺序是不固定的)。
2、在Map 中插入、删除和定位元素,HashMap是最好的选择。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。使用HashMap要求添加的键类明确定义了hashCode()和 equals()的实现。
两个map中的元素一样,但顺序不一样,导致hashCode()不一样。
同样做测试:
在HashMap中,同样的值的map,顺序不同,equals时,false;
而在treeMap中,同样的值的map,顺序不同,equals时,true,说明,treeMap在equals()时是整理了顺序了的。
HashTable与HashMap
1、同步性:Hashtable是线程安全的,也就是说是同步的,而HashMap是线程序不安全的,不是同步的。
2、HashMap允许存在一个为null的key,多个为null的value 。
3、hashtable的key和value都不允许为null。
4、初始容量,HashMap为16,hashTable为11,扩容逻辑,HashMap为 oldSize*2,HashTable为oldSize*2+1
5、HashMap作者多了 Doug Lea,继承抽象Map,HashTable继承字典类
文章作者:
杨立果
文章地址:https://www.cnblogs.com/yangliguo/p/7476788.html 有改动

 浙公网安备 33010602011771号
浙公网安备 33010602011771号