大数据处理技术学习
大数据处理技术
主要环节
1.大数据采集:数据是指通过RFID射频数据、传感器数据、社交网络交互数据及移动互联网数据等方式获得的各种类型海量数据,是大数据知识服务模型的根本。
2.大数据预处理:完成对已接收数据的辨析、抽取、清洗等操作。抽取是指将复杂的数据类型转换成便于处理的类型。清洗是指消除无关数据。
3.大数据存储及管理技术:大数据存储与管理要用存储器把采集到的数据存储起来,建立相应的数据库,并进行管理和调用。
4.大数据分析及挖掘技术:大数据分析就是改进已有数据挖掘和机器学习技术。数据挖掘就是从大量杂乱的数据中提取有用信息的过程,这个过程中会使用到机器学习的方法来分类获得的数据。
5.大数据展现和应用:利用之前环节得到的模型,获得有用的数据信息。这些信息主要用于这三个重大领域:商业智能 、政府决策、公共服务
这些处理环节都涉及到许多复杂的技术,并且环节之间是相互依赖的关系。
主流的大数据处理框架技术
了解了大数据处理的主要环节之后,我们知道了这些环节之间是相互依赖的关系,故我们可以将各个环节以组件或者其他形式组合到框架之中,方便使用。
不同的公司采用的大数据处理技术和框架可能存在差异。最早开始进行这个技术的研究的是谷歌公司。谷歌在2000年左右由于业务的扩张以及互联网的膨胀式发展,要处理大量的来自爬虫程序,交互数据,网页请求等渠道的原始数据。这些数据由于过于庞大,在当时无法在单机服务器上进行处理,所以谷歌开始着手研究如何采用分布式的方式处理庞大的原始数据,同时还要解决分布式计算中的并行计算以及分配数据等问题。
针对于解决以上的庞大数据处理问题,谷歌决定开发一种抽象的模型来处理繁杂的数据,并隐藏模型中复杂的细节。最终诞生了MapReduce。MapReduce可以运行在廉价的PC机上,让大众能体验到大数据计算,并且MapReduce提供了很好的扩展性以及容错性,将大数据处理从集中式过渡至分布式计算的阶段。
但是由于MapReduce不开源,故伟大的网友们秉持着开源的精神,创造出了开源的大数据处理框架,也就是大名鼎鼎的Hadoop。从此大数据处理框架随着大数据处理的需求发展而飞速迭代。
大数据处理框架的分类
不论是系统中存在的历史数据,还是持续不断接入系统中的实时数据,只要数据是可访问的,我们就可以对数据进行处理。按照对所处理的数据形式和得到结果的时效性分类,数据处理框架可以分为两类:
1.批处理系统:批处理是一种用来计算大规模数据集的方法。批处理的过程包括将任务分解为较小的任务,分别在集群中的每个计算机上进行计算,根据中间结果重新组合数据,然后计算和组合最终结果。当处理非常巨大的数据集时,批处理系统是最有效的。
2.流处理系统:流处理则对由连续不断的单条数据项组成的数据流进行操作,注重数据处理结果的时效性。
3.混合处理系统:同时具备批处理与流处理的能力
<!--下面按照批处理系统,流处理系统,混合处理系统的类别,分别介绍主流以及最新的大数据处理系统,例如批处理系统可以介绍Hadoop,流处理系统介绍Samza,kafka,混合处理系统Spark-->
MapReduce(批处理系统)
首先设想一个场景,如果你想统计一本书中某个单词出现的次数,你可以把这本书通过扫描的方式读入一台计算机中,然后通过写代码完成一个简单的单词次数统计程序。例如在java语言下,你可以使用HashMap来完成单词统计,对没出现过的单词加入HashMap中,并且值加一。
但是,在数据量十分庞大的情况下,单机无法完成对海量数据的存储和计算。故人们提出了分布式文件系统(HDFS),将海量的数据存储到不同的计算机,也称为计算节点上进行计算。然而,分布式处理又会带来其他问题。每个计算节点上存的都是部分的数据,运算结果也都是部分的结果,并不是整体的解,这个时候原本单机进行的算法就不能在分布式系统中使用。有人提出可以将运算逻辑的代码分发的持有数据的节点上进行运算,这样子就能保持运算的完整性。这个方法虽然确实有一定道理,但是要将运算逻辑分发,需要考虑许多问题问题:
1.程序代码如果分发到不同的计算节点,怎么知道应该分发到哪个计算节点。
2.程序代码分发后怎么在计算节点的计算机系统配置环境。
3.如果某个计算节点出现错误,例如宕机该怎么处理。
从上可以看出一个简单的统计次数的逻辑在大数据分布式系统的情况下也会变得很复杂。故有人(较早的例如Google公司)就开始着手设计一些大数据处理的框架来封装以上的繁杂细节。这就是MapReduce诞生的由来。
MapReduce 是一个分布式运算程序的编程框架。MapReduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的 分布式运算程序,它的整体结构如下:

一个完整的MapReduce程序在分布式运行时有两类实例进程:
(1) MRAppMaster:负责整个程序的过程调度及状态协调 (该进程在yarn节点上)
(2) Yarnchild:负责 map 阶段的整个数据处理流程
(3) Yarnchild:负责 reduce 阶段的整个数据处理流程
MapReduce程序运行过程比较直观。首先由MRAppMaster读取配置文件,计算切片运算的不同节点数量(也就是MapTask实例进程的数量),然后由各个MapTask进程处理不同节点上的数据,生成<K,V>对,由MRAppMaster监控各个MapTask处理的情况。当所有的MapTask完成计算任务之后,把结果传给一定数量的ReduceTask进程,并告知ReduceTask进程要处理的数据范围。之后ReduceTask进程根据信息 ,从MapTask进程中获取计算结果数据,进行归并排序,然后再调用客户定义的reduce方法进行逻辑运算,并收集运算结果,然后把汇总后的结果输出到外部存储。
从以上的过程中可以看出,MapReduce的出现减轻了程序员编写业务逻辑的工作量。程序员不需要考虑复杂的分布式处理技术,只需要按照业务逻辑,完成对MRAppMaster的配置以及map方法和reduce方法的编写即可。
Samza以及kafka(流处理系统)
Samza作为一个分布式的消息队列系统,kafka已经实现了流式处理框架底层的许多核心基础架构,把消息串联流动起来就是Streaming了。这里展开说明下消息队列系统以及kafka。
消息队列系统介绍
消息队列系统就是处理消息的接收以及分发过程的系统。最经典的例子就是报纸订阅,在报纸订阅这个消息队列系统中,报社作为内容生产者(Producer)将内容做好放到邮箱或者是报刊亭(专业术语可以用服务器Broker表示),然后订阅了这个报纸的消费者(Consumer)从Broker中根据每天的日期不同获取一定顺序的报纸(总不能一个消费者能在2020年10月21日获取到2021年10月21日的报纸吧)。
在消息队列系统中由许多不同的模型,比较经典的有点对点消息队列模型和发布订阅模型。这里讲下发布订阅模型。发布订阅消息模型中,支持向一个特定的主题Topic发布消息,0个或多个订阅者接收来自这个消息主题的消息。在这种模型下,发布者和订阅者彼此不知道对方。实际操作过程中,必须先订阅,再发送消息,而后接收订阅消息。好比你必须先关注罗翔老师的B站账号(Topic),才能在罗翔老师发布新视频的时候,获取到最新的入狱小技巧,并且你可以随时回看罗翔老师的旧的视频,只需要记得这个视频的在罗翔老师空间中的编号(offset)。
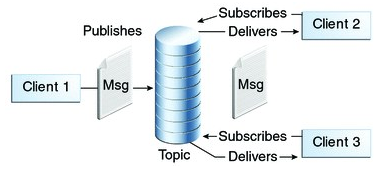
在了解了消息队列系统的基本情况后,就能去理解kafka的设计思想。
kafka介绍
Kafka是一个分布式的、可分区的、可复制的消息系统。kafka将消息以topic为单位进行归纳。将向kafka topic发布消息的程序称为Producer,将预定kafka topic并获取消息的程序称为Consumer。kafka以集群的方式运行,可以由一个或者多个服务器组成集群,每个服务器称为一个Broker。Producer通过网络将消息发送到kafka服务器集群,集群向消费者提供消息。
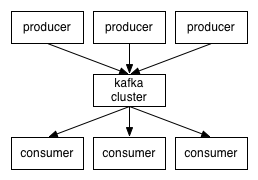
在kafka中的topic是对一组消息的归纳,对于每个topic中的日志消息,kafka进行了分区处理,消息按照先进先出的顺序进入分区队列,每个分区中的消息用一个offset标记,每个分区在kafka集群若干服务器中都有副本,这些持有分区副本的服务器可以并发处理数据和请求。每个分区都有一个服务器作为Leader,若干个服务器作为Followers,Leader负责处理分区消息的读写,Followers负责从Leader那获取数据,这样子的处理增加了kafka集群的容错性。
kafka相比于其他的消息队列有着良好的有序性保证。传统的队列可以在服务器上有序的保存消息,一旦由多个Consumer发送异步请求消息,服务器虽然能按照顺序给Consumer发布消息,但是因为异步的原因,Consumer受到消息是无序的。kafka的分区解决了这一问题。kafka的每个分区只发送给一个Consumer Group,但是不同的Consumer Group对于同一个分区的消息可以从不同的服务器上获取,再加上一定的负载均衡算法,就能实现有序的并发获取消息。
Samza介绍
考虑到当你为什么想要使用消息队列?比如当用户浏览一个网页的时候,你会发送一个“用户浏览页面”的事件给系统,然后执行其他操作,例如将事件消息存储在Hadoop中将来分析,页面访问计数并更新计数板,向其他用户发送电子邮件。消息队列系统将上面繁琐的功能于实际业务逻辑分离开。
但是消息队列也存在许多缺点,例如页面访问技术功能,如果执行计数服务代码的服务器出现故障,计数值丢失怎么办?如果异步发送邮件的时候同时发送了多封邮件怎么办?如果数据量庞大,单机无法处理怎么办?Samza基于流处理框架能处理上面的这些问题。
Samza 处理流(Streams)。流由相似类型不可变消息组成。例如,流可以是网站上的所有点击记录,或特定数据库表的所有更新记录,或服务生成的所有日志,或任何其他类型的事件数据。消息可以附加到流或从流中读取。流可以具有任何数量的消费者,并且从流读取不会删除消息(因此每个消息被有效地广播给所有消费者)。在之前提到的kafka中,流是以topic的形式表现。
Samza的工作(Job)是对一组输入流进行操作然后将结果数据附加到输出流的代码。
在Samza中,流和工作被分解为更小的并行单元:分区。这里的分区和kafka中的分区队列一致,都是完全有序的消息队列。工作和流由资源管理器YARN 进行调度,例如上面存在的执行计数服务代码的服务器出现故障,计数值丢失,则YARN就会将这个任务交给其他节点进行处理,并且由于分区的存在,数据在不同节点服务器有备份,这样就解决了这个问题。
Samza由三层架构组成,并且由于Samza具有可插拔的特性,底层架构是可以根据需求替换的,架构图如下:
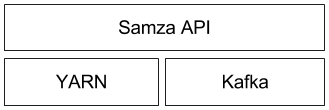
最顶层的是给程序员提供的Samza API,程序员只需要处理好相关配置,并通过提供的接口就可以使用Samza提供的流处理服务。底层架构采用的是YARN作为资源调度器,kafka提供流消息队列和分区。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号