【R语言数据科学】(十四):随机变量和基本统计量
【R语言数据科学】(十四):随机变量和基本统计量
- 🌸个人主页:JoJo的数据分析历险记
- 📝个人介绍:小编大四统计在读,目前保研到统计学top3高校继续攻读统计研究生
- 💌如果文章对你有帮助,欢迎✌
关注、👍点赞、✌收藏、👍订阅专栏- ✨本文收录于【R语言数据科学】本系列主要介绍R语言在数据科学领域的应用包括:
R语言编程基础、R语言可视化、R语言进行数据操作、R语言建模、R语言机器学习算法实现、R语言统计理论方法实现。本系列会坚持完成下去,请大家多多关注点赞支持,一起学习~,尽量坚持每周持续更新,欢迎大家订阅交流学习!

前言
在数据科学中,我们经常以某种方式处理受偶然性影响的数据:数据来自随机样本,数据受测量误差的影响,或者数据测量了一些本质上随机的结果。能够量化随机性带来的不确定性是数据分析师最重要的工作之一。统计推断为此提供了一个框架以及几个实用工具。第一步是学习如何用数学方法描述随机变量。
在本章中,我们首先介绍随机变量及其基本统计量,下一章进一步介绍概率论中两个重要知识点:大数定理和中心极限定理。
1.随机变量
随机变量是随机过程产生的数值结果。我们可以使用我们展示的一些简单示例生成随机变量。例如,如果珠子是蓝色的,则定义
X为 1,否则为0:
beads <- rep( c("red", "blue"), times = c(2,3))
X <- ifelse(sample(beads, 1) == "blue", 1, 0)
这里的X就是一个随机变量:每次我们选择一个新珠子时,结果都会随机变化。
ifelse(sample(beads, 1) == "blue", 1, 0)
ifelse(sample(beads, 1) == "blue", 1, 0)
ifelse(sample(beads, 1) == "blue", 1, 0)
0
1
1
2.抽样模型
许多数据生成为我们研究的数据,可以很好地通过抽样来获取,就像抓阄一样。例如,我们可以将选民投票可能的结果建模为从包含所有选民的 0 和 1 代码的瓮中抽取
0(共和党)和1(民主党);在流行病学研究中,我们经常假设我们研究中的受试者是来自感兴趣人群的随机样本。与特定结果相关的数据可以抽样为来自包含整个感兴趣人群结果的瓮中的随机样本。同样,在实验研究中,我们经常假设我们正在研究的个体生物,例如蠕虫、苍蝇或老鼠,是来自更大种群的随机样本。考虑到个人被分配到组中的方式,随机实验也可以通过抽样来进行:当被分配时,随机抽取该组。因此,收益模型在数据科学中无处不在。赌场游戏提供了大量真实情况的示例,其中使用抽样模型来回答特定问题。因此,我们将从这些例子开始。
假设一家很小的赌场聘请您咨询他们是否应该设置轮盘赌。为简单起见,我们假设有1,000 人参加,并且您可以在轮盘上玩的唯一游戏是下注红色或黑色。赌场希望您预测他们将赚多少钱或亏多少钱。他们想要一系列的结果,特别是,他们想知道赔钱的可能性有多大。如果这个概率太高,他们会继续安装轮盘赌。
我们将定义一个随机变量 (S) 来表示赌场的总奖金。让我们从构建抽样框开始。一个轮盘有 18 个红色口袋、18 个黑色口袋和 2 个绿色口袋。 在一场轮盘赌中玩一种颜色就相当于从这个抽样框中抽奖:
color <- rep(c("Black", "red", "Green"), c(18, 18, 2))
来自 1,000 名玩家的 1,000 个结果是从这个抽样中独立抽取的。如果出现红色,赌徒赢,赌场输一美元,所以我们抽到结果为 -1$,否则,赌场赢一美元,我们结果为1美元。要构造我们的随机变量 (S),我们可以使用以下代码:
n <- 1000
X <- sample(ifelse(color == "red", -1, 1), n, replace = TrUE)
X[1:10]
- 1
- -1
- -1
- -1
- -1
- 1
- 1
- -1
- -1
- -1
因为我们知道 1 和 − 1 和 -1 和−1 的比例,我们可以用一行代码生成数据,而无需定义相应的类别数量
X <- sample(c(-1,1), n, replace = TrUE, prob=c(9/19, 10/19))
我们称其为抽样模型,因为我们使用从抽样框中抽奖的随机抽样来模拟轮盘赌的随机行为。总奖金 (S) 只是这 1,000 次独立抽奖的总和:
X <- sample(c(-1,1), n, replace = TrUE, prob=c(9/19, 10/19))
S <- sum(X)
S
3 随机变量的概率分布
如果我们重复运行上面的代码,可以看到 (S) 每次都在变化。当然,这是因为 (S) 是一个随机变量。随机变量的概率分布告诉我们观察值在任何给定间隔下降的概率。因此,例如,如果我们想知道我们赔钱的概率,我们要问的是 (S) 在区间 (S<0) 内的概率。
请注意,如果我们可以定义一个累积分布函数 F ( a ) = P r ( S ≤ a ) F(a) = {Pr}(S\leq a) F(a)=Pr(S≤a) ,那么我们将能够回答任何与我们随机定义的事件概率相关的问题变量(S),包括事件(S<0)。我们称此 (F) 为随机变量的分布函数。
我们可以通过使用蒙特卡罗模拟来估计随机变量 (S) 的分布函数,以生成随机变量的许多实现。使用此代码,我们运行让 1,000 人一遍又一遍地玩轮盘赌的实验,并且进行 (B = 10,000) 次:
n <- 1000
B <- 10000
roulette_winnings <- function(n){
X <- sample(c(-1,1), n, replace = TrUE, prob=c(9/19, 10/19))
sum(X)
}
S <- replicate(B, roulette_winnings(n))
现在我们可以问以下问题:在我们的模拟中,我们得到小于或等于 a 的总和的频率是多少?这将是 (F(a)) 的一个非常好的近似值,我们可以很容易地回答赌场的问题:我们赔钱的可能性有多大?我们可以看到它非常低:
mean(S<0)
0.0427
我们可以通过创建一个直方图来可视化 (S) 的分布,该直方图显示几个区间 ((a,b]) 的概率 (F(b)-F(a)):
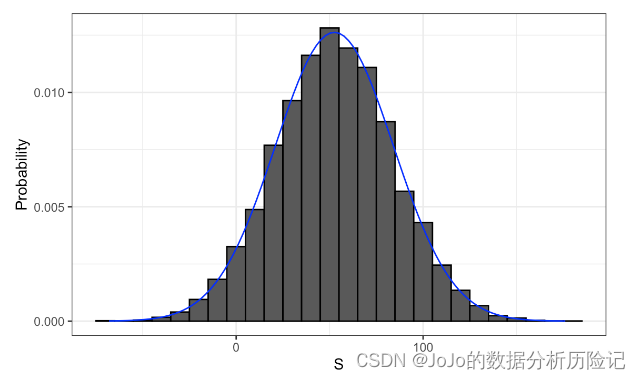
我们看到分布似乎是近似正态的。 qq 图将确认正态近似接近此分布的完美近似。事实上,如果分布是正态的,那么我们只需要定义分布的平均值和标准差即可。因为我们有创建分布的原始值,所以我们可以很容易地用 mean(S) 和 sd(S) 计算这些值。可以看到添加到上面直方图中的蓝色曲线是具有此平均值和标准偏差的正常密度。
这个平均值和这个标准偏差有特殊的名称。它们被称为随机变量 (S) 的期望值和标准误差。我们将在下一节中详细介绍这些内容。
统计理论提供了一种方法来导出随机变量的分布,这些随机变量定义为从抽样框中随机抽取的随机变量。具体来说,在我们上面的例子中,我们可以证明 ((S+n)/2) 遵循二项分布。因此,我们不需要运行蒙特卡罗模拟来了解 (S) 的概率分布。
我们可以使用函数dbinom和pbinom来精确计算概率。例如,为了计算 P r ( S < 0 ) {Pr}(S < 0) Pr(S<0),我们注意到:
P r ( S < 0 ) = P r ( ( S + n ) / 2 < ( 0 + n ) / 2 ) {Pr}(S < 0) = {Pr}((S+n)/2 < (0+n)/2) Pr(S<0)=Pr((S+n)/2<(0+n)/2)
我们可以使用 pbinom 来计算 P r ( S ≤ 0 ) {Pr}(S \leq 0) Pr(S≤0)
n <- 1000
pbinom(n/2, size = n, prob = 10/19)
0.0510979434690998
因为这是一个离散概率函数,为了得到 P r ( S < 0 ) {Pr}(S < 0) Pr(S<0) 而不是 P r ( S ≤ 0 ) {Pr}(S \leq 0) Pr(S≤0),我们写:
pbinom(n/2-1, size = n, prob = 10/19)
0.0447959069035901
4.基本统计量
我们已经描述了抽奖的抽样模型。现在,我们将回顾一下数学理论,它可以让我们近似得出平局总和的概率分布。一旦我们这样做,我们将能够帮助赌场预测他们将赚多少钱。我们用于平局总和的相同方法将有助于描述平均值和比例的分布,我们需要了解民意调查的工作原理。要学习的第一个重要概念是期望值。在统计书籍中,通常像这样使用字母 E {E} E:
E [ X ] {E}[X] E[X]
表示随机变量 X X X 的期望值。
随机变量将围绕其预期值变化,如果我们去许多次抽签的平均值,抽签的平均值将接近预期值,抽签越多,越接近真实值。
理论统计提供了有助于在不同情况下计算预期值的技术。例如,一个有用的公式告诉我们,一次抽奖定义的随机变量的期望值是瓮中数字的平均值。在用于模拟轮盘赌红色赌注的瓮中,我们有 20 个 1 美元和 18 个负 1 美元。因此,期望值为:
E [ X ] = ( 20 + ( − 18 ) ) / 38 E[X] = (20 + (-18))/38 E[X]=(20+(−18))/38
大约是 5 美分。说 X X X 在 0.05 左右变化有点违反直觉,而它所取的唯一值是 1 和 -1。在这种情况下,理解预期价值的一种方法是意识到如果我们一遍又一遍地玩游戏,赌场平均每场游戏会赢 5 美分。蒙特卡罗模拟证实了这一点:
B <- 10^6
x <- sample(c(-1,1), B, replace = TrUE, prob=c(9/19, 10/19))
mean(x)
0.05279
- 一般来说,如果瓮有两种可能的结果,比如 a a a 和 b b b,比例分别为 p p p 和 1 − p 1-p 1−p,则平均值为:
E [ X ] = a p + b ( 1 − p ) {E}[X] = ap+b(1-p) E[X]=ap+b(1−p)
- 假设现在有n个珠子,np个是a,n(1-p)是b,那么他们的总和是
n p a + n b ( 1 − p ) npa+nb(1-p) npa+nb(1−p)
- 再除以n得到平均值:
a p + b ( 1 − p ) ap+b(1-p) ap+b(1−p)
- 我们定义期望值的原因是因为这个数学定义对于近似 sum 的概率分布很有用,这对于描述平均值和比例的分布很有用。第一个有用的事实是总和的预期值为:
n × E ( X ) n \times E(X) n×E(X)
- 因此,如果 1000 人玩轮盘赌,赌场预计平均会赢大约 1000× 0.05 美元 = 50 美元。但这是一个预期值。一个观察值与预期值有多大不同?赌场真的需要知道这一点。可能性范围是多少?如果是负数的话,赌场不会安装轮盘赌。
我们可以使用标准差回答这个问题。标准误差 (SE) 让我们了解期望周围的变化大小。在统计书籍中,通常使用: S E ( X ) SE(X) SE(X)表示。
现在假设每次赌局都是独立的,那么标准差为:
∣ b − a ∣ p ( 1 − P |b-a|\sqrt{p(1-P} ∣b−a∣p(1−P
- 标准误差告诉我们随机变量与其期望之间的典型差异。我们可以使用上面的公式计算出一次平局定义的随机变量的期望值为 0.05,标准误差约为 1。这是有道理的,因为我们要么得到 1或 -1,1 略比 -1多。
使用上面的公式,1000 人的总和有大约 32 美元的标准误差:
n <- 1000
sqrt(n) * 2 * sqrt(90)/19
31.5789473684211
5.总体方差和样本方差
X的标准差(下面我们以高度为例)定义为方差的平方根:
library(dslabs)
x <- heights$height
m <- mean(x)
s <- sqrt(mean((x-m)^2))
数学表达式如下:
μ = 1 n ∑ i = 1 n x i σ = 1 n ∑ i = 1 n ( x i − μ ) 2 \mu = \frac{1}{n}\sum_{i=1}^{n}x_i\\ \sigma = \sqrt{\frac{1}{n}\sum_{i=1}^{n}(x_i-\mu)^2} μ=n1i=1∑nxiσ=n1i=1∑n(xi−μ)2
然而,在r中,如果使用sd函数,返回的结果有点不同
s == sd(x)
s - sd(x)
FALSE
-0.00194266120553532
这是因为在r中,sd函数不是对整体求标准差,而是通过一个公式从随机样本中估计总体的标准差。具体如下:
X ˉ = 1 N ∑ i = 1 N x i s = 1 N − 1 ∑ i = 1 N ( X i − X ˉ ) 2 \bar X = \frac{1}{N}\sum_{i=1}^N x_i\\s = \sqrt{\frac{1}{N-1}\sum_{i=1}^{N}(X_i-\bar X)^2} Xˉ=N1i=1∑Nxis=N−11i=1∑N(Xi−Xˉ)2
我们下面来就检测一下
n <- length(x)
s-sd(x)*sqrt((n-1) / n)
0
因此,对于此处讨论的所有理论,我们需要按照定义计算实际标准标准差如下:
sqrt(mean((x-m)^2))
4.07667430843691
因此,在 r 中使用 sd 函数时要小心。但是当数据大小很大时,这两个实际上是等价的,因为
( N − 1 ) / N ≈ 1 \sqrt{(N-1)/N\approx1} (N−1)/N≈1
本章的介绍到此介绍,如果文章对你有帮助,请多多点赞、收藏、评论、关注支持!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号