【R语言文本挖掘】:分析单词和文档频率——TF-IDF
【R语言文本挖掘】:分析单词和文档频率——TF-IDF
- 🌸个人主页:JoJo的数据分析历险记
- 📝个人介绍:小编大四统计在读,目前保研到统计学top3高校继续攻读统计研究生
- 💌如果文章对你有帮助,欢迎✌
关注、👍点赞、✌收藏、👍订阅专栏- ✨本文收录于【R语言文本挖掘】本系列主要介绍R语言在文本挖掘领域的应用包括:情感分析、TF-IDF、主题模型等。本系列会坚持完成下去,请大家多多关注点赞支持,一起学习~,尽量坚持每周持续更新,欢迎大家订阅交流学习!

引言
文本挖掘和自然语言处理的一个核心问题是如何量化文档的内容。我们可以通过查看构成文档的单词来做到这一点吗?衡量一个词的重要性的一种方法是它的词频(tf),即一个词在文档中出现的频率,然而文档中有些词出现了很多次,但可能不会重要的;在英语中,这些可能是“the”、“is”、“of”等词。我们可能会采取将这些词添加到停用词列表中并在分析之前将其删除的方法,但是这些词中的某些词在某些文档中可能比其他词更重要。停用词列表不是调整常用词的词频的非常复杂的方法。
另一种方法是查看一个单词的逆文档频率 (idf),它会降低常用词的权重,并增加文档集合中不常用词的权重。这可以与单词频率相结合来计算单词的 tf-idf(两个量相乘),即根据使用频率调整单词的频率。
统计 tf-idf 旨在衡量一个词对文档集合(或语料库)中的文档的重要性,例如,对于小说集合中的一部小说或网站集合中的一个网站。
它是一个经验法则或启发式数量;虽然它已被证明在文本挖掘、搜索引擎等方面很有用,但信息论专家认为它的理论基础并不牢固。任何给定单词的逆文档频率定义为:
i d f ( t e r m ) = l n ( n d o c u m e n t s n d o c u m e n t s c o n t a i n i n g t e r m ) idf(term) = ln(\frac{n_{documents}}{n_{documents containing term}}) idf(term)=ln(ndocumentscontainingtermndocuments)
1.简·奥斯汀小说集的频率
让我们从查看简·奥斯汀(Jane Austen)出版的小说开始,首先检查词频,然后是 tf-idf。我们可以从使用 dplyr的函数开始,例如 group_by() 和 join()。简奥斯汀小说中最常用的词是什么? (这里我们也计算一下每部小说的总字数,以备后用。)
这里我们需要使用
janeaustenr的包。该软件包提供对简·奥斯汀 6 部已完成、已出版小说的全文的访问。每个文本都在一个字符向量中,其中包含大约 70 个字符的元素。主要包含了以下六本书:
- sensesensibility: Sense and Sensibility, published in 1811
- prideprejudice: Pride and Prejudice, published in 1813
- mansfieldpark: Mansfield Park, published in 1814
- emma: Emma, published in 1815
- northangerabbey: Northanger Abbey, published posthumously in 1818
- persuasion: Persuasion, also published posthumously in 1818
接下来我们导入相关库
# 导入相关库
library(dplyr)
library(janeaustenr)
library(tidytext)
分词处理
# 将文本分词成word
book_words <- austen_books() %>%
unnest_tokens(word, text) %>% #将文本分词
count(book, word, sort = TrUE)
book_words%>%head()
| book | word | n |
|---|---|---|
| <fct> | <chr> | <int> |
| Mansfield Park | the | 6206 |
| Mansfield Park | to | 5475 |
| Mansfield Park | and | 5438 |
| Emma | to | 5239 |
| Emma | the | 5201 |
| Emma | and | 4896 |
上述我们得到了各本小说的word频率,接下来,我们计算一下各本书的单词总数
total_words <- book_words %>%
group_by(book) %>%
summarize(total = sum(n))
total_words%>%head()
| book | total |
|---|---|
| <fct> | <int> |
| Sense & Sensibility | 119957 |
| Pride & Prejudice | 122204 |
| Mansfield Park | 160460 |
| Emma | 160996 |
| Northanger Abbey | 77780 |
| Persuasion | 83658 |
接下来我们要做的就是将这两个表进行合并,便于我们计算频率
book_words <- left_join(book_words, total_words)#左连接
book_words %>% head()
[1m[22mJoining, by = c("book", "total")
| book | word | n | total |
|---|---|---|---|
| <fct> | <chr> | <int> | <int> |
| Mansfield Park | the | 6206 | 160460 |
| Mansfield Park | to | 5475 | 160460 |
| Mansfield Park | and | 5438 | 160460 |
| Emma | to | 5239 | 160996 |
| Emma | the | 5201 | 160996 |
| Emma | and | 4896 | 160996 |
在这个 book_words 数据框中,每个词-书组合都有一行; n 是该单词在该书中使用的次数,total 是该书中的总单词。通常的停用词在这里最高,例如“the”、“and”、“to”等等。现在让我们看看每本小说的 n/total 分布,即一个词在小说中出现的次数除以该小说中的词条(词)总数。这正是我们所说的频率。
library(ggplot2)
ggplot(book_words, aes(n/total, fill = book)) +
geom_histogram(show.legend = FALSE) +
xlim(NA, 0.0009) +
facet_wrap(~book, ncol = 2, scales = "free_y")#分面绘图
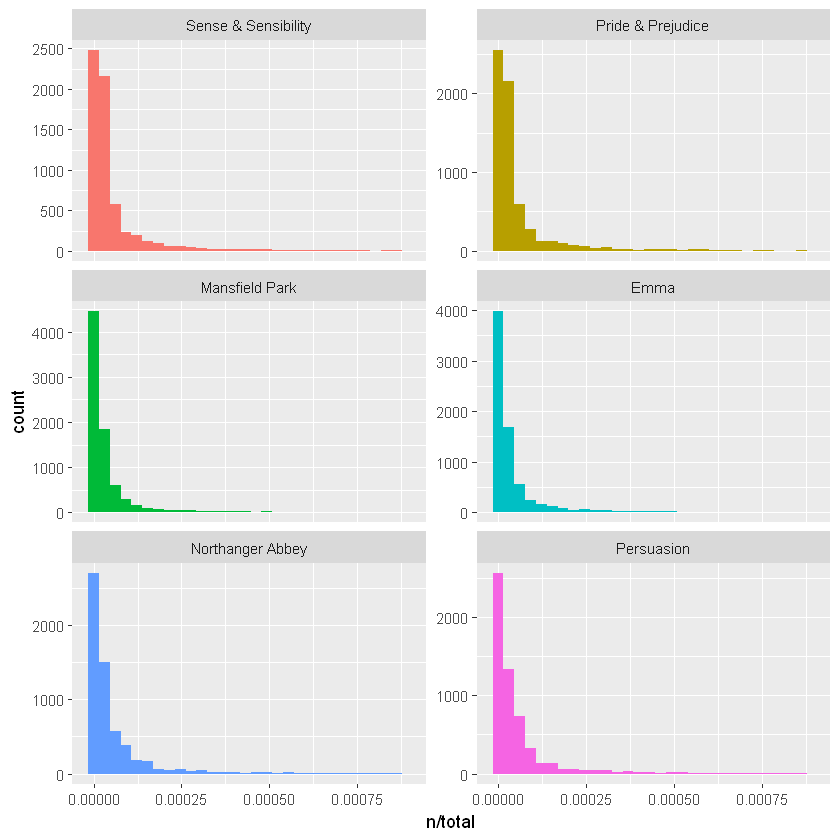
这些小说都是长尾分布,这说明,大部分的词出现的频率都比较少,少部分词出现的比较多。我们没有在这些情节中显示。这些图对所有小说都表现出相似的分布,其中许多单词很少出现,而频繁出现的单词较少。
2.齐夫定律
上图所示的分布在语言中是典型的。事实上,这些类型的长尾分布在任何给定的自然语言语料库(如一本书,或来自网站的大量文本,或口语)中都很常见,以至于一个词的使用频率和它的rank一直是研究的主题;这种关系的经典版本被称为齐夫定律。发现某一单词出现的频率与其在频率表里名次的常数次幂成反比,也就是说极少数的单词会被经常使用,而绝大多数单词很少被提及。这种20/80法则在很多领域都被逐步发现,这种幂律分布被称为“齐夫定律”(Zipf’s law)。
由于我们有用于绘制词频的数据框,我们可以只用几行 dplyr 函数来检查简奥斯汀小说的齐夫定律。
freq_by_rank <- book_words %>%
group_by(book) %>%
mutate(rank = row_number(),
`term frequency` = n/total)#计算rank和频率
freq_by_rank%>%head()
| book | word | n | total | rank | term frequency |
|---|---|---|---|---|---|
| <fct> | <chr> | <int> | <int> | <int> | <dbl> |
| Mansfield Park | the | 6206 | 160460 | 1 | 0.03867631 |
| Mansfield Park | to | 5475 | 160460 | 2 | 0.03412065 |
| Mansfield Park | and | 5438 | 160460 | 3 | 0.03389007 |
| Emma | to | 5239 | 160996 | 1 | 0.03254118 |
| Emma | the | 5201 | 160996 | 2 | 0.03230515 |
| Emma | and | 4896 | 160996 | 3 | 0.03041069 |
这里的rank列告诉我们每个词在频率表中的排名:因为该表已按 n 排序,因此我们可以使用 row_number() 来查找排名。然后,我们可以像以前一样计算词频。 齐夫定律通常通过在对数刻度上绘制 x 轴上的等级和 y 轴上的词频来可视化。以这种方式绘制**,反比例关系将具有恒定的负斜率。**
freq_by_rank %>%
ggplot(aes(rank, `term frequency`, color = book)) +
geom_line(size = 1.1, alpha = 0.8, show.legend = FALSE) +
scale_x_log10() +
scale_y_log10()
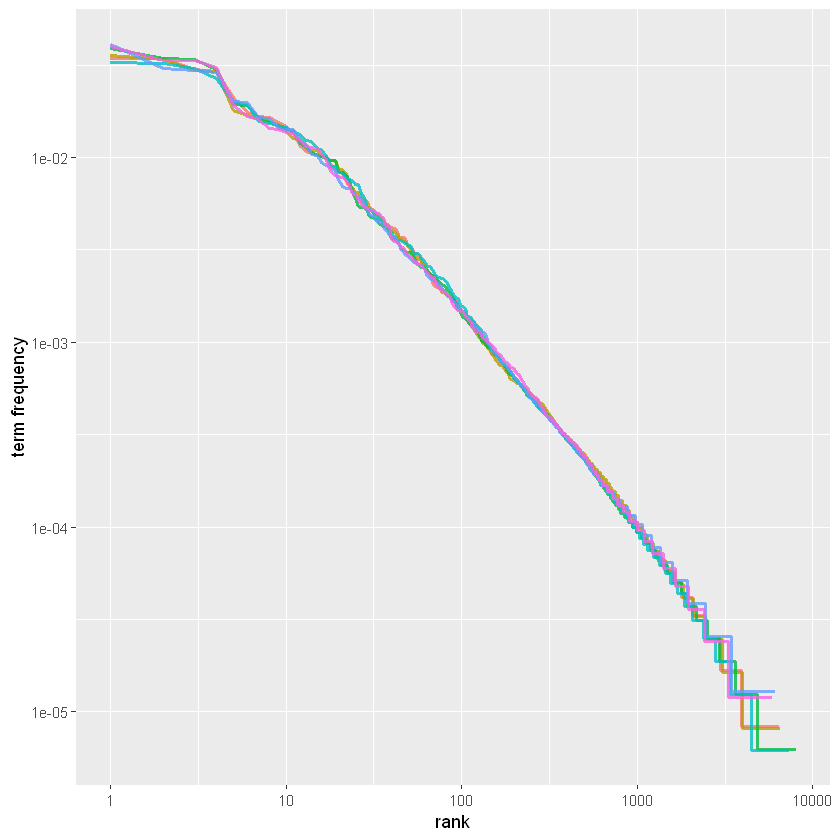
请注意,上图位于对数坐标中。我们看到简·奥斯汀的六部小说都彼此相似,并且排名和频率之间的关系确实具有负斜率。但是,它并不完全恒定。让我们看看
rank范围中间部分的幂律指数是多少。
rank_subset <- freq_by_rank %>%
filter(rank < 500,
rank > 10)
lm(log10(`term frequency`) ~ log10(rank), data = rank_subset)
Call:
lm(formula = log10(`term frequency`) ~ log10(rank), data = rank_subset)
Coefficients:
(Intercept) log10(rank)
-0.6226 -1.1125
事实上,我们在这里得到了一个接近 -1 的斜率。让我们看看下图中的数据绘制这个拟合的幂律,看看它的样子。
freq_by_rank %>%
ggplot(aes(rank, `term frequency`, color = book)) +
geom_abline(intercept = -0.62, slope = -1.1,
color = "gray50", linetype = 2) +
geom_line(size = 1.1, alpha = 0.8, show.legend = FALSE) +
scale_x_log10() +
scale_y_log10()
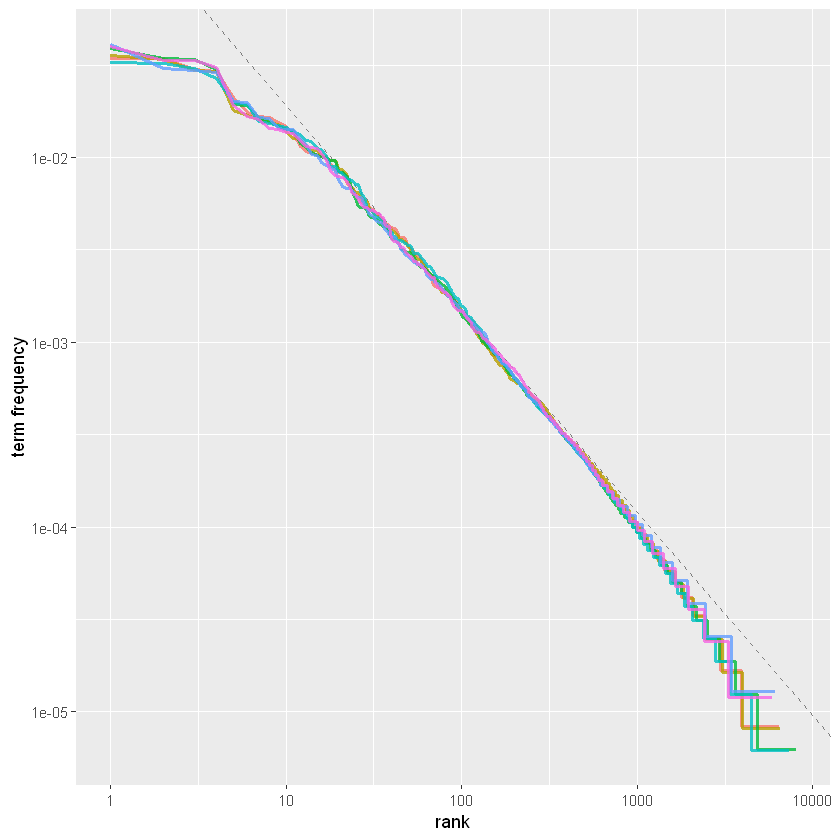
对于简·奥斯汀的小说语料库,我们发现了一个接近经典版本的 Zipf 定律的结果。我们在这里看到的高级偏差对于多种语言来说并不少见。一个语料库包含的稀有词通常比单一幂律预测的要少。低等级的偏差更不寻常。与许多语言集合相比,简奥斯汀使用的最常用词的百分比较低。这种分析可以扩展到比较作者,或比较任何其他文本集合;它可以简单地使用整洁的数据原则来实现。
3.bind_tf_idf() 函数
tf-idf 的思想是通过减少常用词的权重和增加文档集合或语料库中不常用词的权重来找到每个文档内容的重要词,在这种情况下,简奥斯汀的小说群作为一个整体。计算 tf-idf 试图找到文本中重要但不太常见的单词。现在让我们这样做。
tidytext 包中的 bind_tf_idf() 函数将一个整洁的文本数据集作为输入,每个文档每个标记(单词)一行。一列(此处为单词)包含单词/标记,一列包含文档(在本例中为书),最后必要的列包含计数,每个文档包含每个单词的次数(本例中为 n)。我们在前面的章节中为我们的探索计算了每本书的总数,但对于bind_tf_idf() 函数不是必需的;该表只需要包含每个文档中的所有单词。
book_tf_idf <- book_words %>%
bind_tf_idf(word, book, n)
book_tf_idf %>% head()
| book | word | n | total | tf | idf | tf_idf |
|---|---|---|---|---|---|---|
| <fct> | <chr> | <int> | <int> | <dbl> | <dbl> | <dbl> |
| Mansfield Park | the | 6206 | 160460 | 0.03867631 | 0 | 0 |
| Mansfield Park | to | 5475 | 160460 | 0.03412065 | 0 | 0 |
| Mansfield Park | and | 5438 | 160460 | 0.03389007 | 0 | 0 |
| Emma | to | 5239 | 160996 | 0.03254118 | 0 | 0 |
| Emma | the | 5201 | 160996 | 0.03230515 | 0 | 0 |
| Emma | and | 4896 | 160996 | 0.03041069 | 0 | 0 |
请注意,对于这些极其常见的单词, idf 和tf-idf 为零。这些都是简·奥斯汀六部小说中出现的所有词,因此 idf 项(它将是 1 的自然对数)为零。对于出现在集合中的许多文档中的单词,逆文档频率( tf-idf)非常低(接近于零);这就是这种方法如何降低常用词的权重。对于出现在集合中较少文档中的单词,逆文档频率将是较高的数字。
让我们看看简奥斯汀作品中的高 tf-idf 单词。
book_tf_idf %>%
select(-total) %>%
arrange(desc(tf_idf)) %>%head()
| book | word | n | tf | idf | tf_idf |
|---|---|---|---|---|---|
| <fct> | <chr> | <int> | <dbl> | <dbl> | <dbl> |
| Sense & Sensibility | elinor | 623 | 0.005193528 | 1.791759 | 0.009305552 |
| Sense & Sensibility | marianne | 492 | 0.004101470 | 1.791759 | 0.007348847 |
| Mansfield Park | crawford | 493 | 0.003072417 | 1.791759 | 0.005505032 |
| Pride & Prejudice | darcy | 373 | 0.003052273 | 1.791759 | 0.005468939 |
| Persuasion | elliot | 254 | 0.003036171 | 1.791759 | 0.005440088 |
| Emma | emma | 786 | 0.004882109 | 1.098612 | 0.005363545 |
在这里,我们看到了所有专有名词,在这些小说中实际上很重要的名字。 它们都没有出现在所有小说中,它们是简·奥斯汀小说语料库中每个文本的重要特征词。
idf 的一些值对于不同的单词是相同的,因为这个语料库中有 6 个文档,我们看到的数值是ln(6/1),…ln(6/2)
library(forcats)
book_tf_idf %>%
group_by(book) %>%
slice_max(tf_idf, n = 15) %>%
ungroup() %>%
ggplot(aes(tf_idf, fct_reorder(word, tf_idf), fill = book)) +
geom_col(show.legend = FALSE) +
facet_wrap(~book, ncol = 2, scales = "free") +
labs(x = "tf-idf", y = NULL)
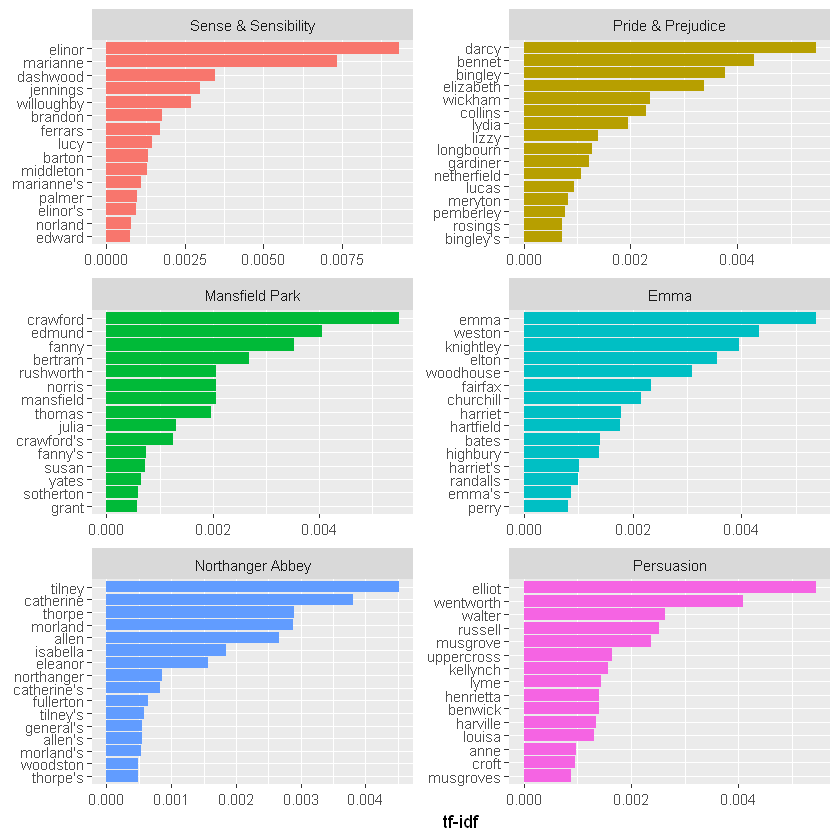
仍然是之前的所有专有名词!根据 tf-idf 衡量,这些词对每部小说来说都是最重要的,并且大多数读者可能会同意。在这里测量 tf-idf 所做的是向我们展示简·奥斯汀在她的六部小说中使用了相似的语言,而在她的作品集中,一部小说与其他小说的区别在于专有名词、人名和地名。这就是 tf-idf 的重点;它在一组文档中识别对一个文档很重要的单词。
4.物理文档语料库
让我们使用另一个文档语料库,看看哪些单词在不同的作品集中很重要。事实上,让我们完全离开虚构和叙事的世界。让我们从 Project Gutenberg 下载一些经典的物理文本,看看这些作品中哪些单词是重要的,由 tf-idf 衡量。让我们下载伽利略·伽利莱的《论浮体》、克里斯蒂安·惠更斯的光论、尼古拉·特斯拉的高电位和高频交变电流实验以及阿尔伯特·爱因斯坦的相对论:狭义和广义理论。
这是一个非常多样化的群体。它们可能都是物理学经典,但它们是在 300 年的时间跨度内写成的,其中一些是先用其他语言写成的,然后翻译成英文。这些不是完全同质的,但这并不能阻止这是一个有趣的练习!
library(gutenbergr)
physics <- gutenberg_download(c(37729, 14725, 13476, 30155),
meta_fields = "author")
现在我们有了这四本书的文本,接下来我们使用unnest_tokens()和count()函数来计算每个单词在每个文本中出现的次数、
physics_words <- physics %>%
unnest_tokens(word,text)%>%
count(author,word, sort = TrUE)
physics_words %>% head()
| author | word | n |
|---|---|---|
| <chr> | <chr> | <int> |
| Galilei, Galileo | the | 3760 |
| Tesla, Nikola | the | 3604 |
| Huygens, Christiaan | the | 3553 |
| Einstein, Albert | the | 2993 |
| Galilei, Galileo | of | 2049 |
| Einstein, Albert | of | 2028 |
在这里,我们只看到原始计数;我们需要记住,这些文件都是不同的长度。让我们继续计算 tf-idf。
plot_physics <- physics_words %>%
bind_tf_idf(word, author, n) %>%
mutate(author = factor(author, levels = c("Galilei, Galileo",
"Huygens, Christiaan",
"Tesla, Nikola",
"Einstein, Albert")))
plot_physics %>%
group_by(author) %>%
slice_max(tf_idf, n = 15) %>%
ungroup() %>%
mutate(word = reorder(word, tf_idf)) %>%
ggplot(aes(tf_idf, word, fill = author)) +
geom_col(show.legend = FALSE) +
labs(x = "tf-idf", y = NULL) +
facet_wrap(~author, ncol = 2, scales = "free")
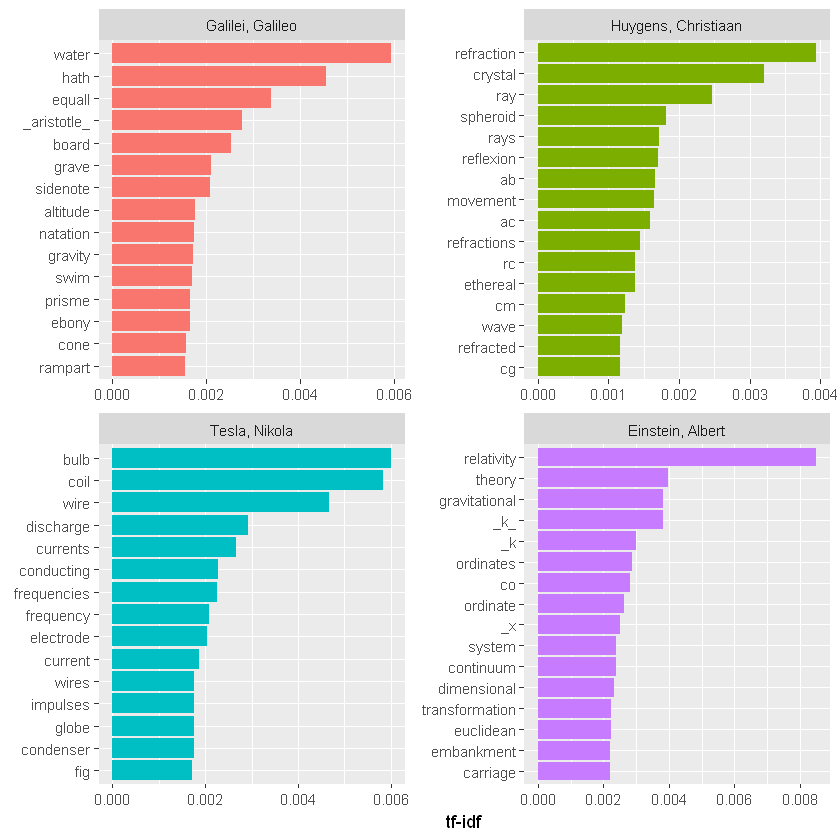
确实非常有趣。我们在这里看到的一件事是爱因斯坦相对论中文本中的k的tf-idf很高,我们接下来来分析一下
library(stringr)
physics %>%
filter(str_detect(text, "_k_")) #%>%
#select(text)
| gutenberg_id | text | author |
|---|---|---|
| <int> | <chr> | <chr> |
| 14725 | surface AB at the points AK_k_B. Then instead of the hemispherical | Huygens, Christiaan |
| 14725 | would needs be that from all the other points K_k_B there should | Huygens, Christiaan |
| 14725 | necessarily be equal to CD, because C_k_ is equal to CK, and C_g_ to | Huygens, Christiaan |
| 14725 | the crystal at K_k_, all the points of the wave CO_oc_ will have | Huygens, Christiaan |
| 14725 | O_o_ has reached K_k_. Which is easy to comprehend, since, of these | Huygens, Christiaan |
| 14725 | CO_oc_ in the crystal, when O_o_ has arrived at K_k_, because it forms | Huygens, Christiaan |
| 30155 | ρ is the average density of the matter and _k_ is a constant connected | Einstein, Albert |
可能需要对文本进行一些清理。另请注意,爱因斯坦文本的高 tf-idf 词中有单独的“co”和“ordinate”项目; unnest_tokens() 函数默认分隔标点符号,如连字符。请注意,“co”和“ordinate”的 tf-idf 分数接近相同!“AB”、“rC”等是惠更斯的射线、圆、角等名称。
physics %>%
filter(str_detect(text, "rC")) %>%
select(text) %>%
head()
| text |
|---|
| <chr> |
| line rC, parallel and equal to AB, to be a portion of a wave of light, |
| represents the partial wave coming from the point A, after the wave rC |
| be the propagation of the wave rC which fell on AB, and would be the |
| transparent body; seeing that the wave rC, having come to the aperture |
| incident rays. Let there be such a ray rC falling upon the surface |
| CK. Make CO perpendicular to rC, and across the angle KCO adjust OK, |
让我们删除其中一些意义不大的词,以制作更好、更有意义的信息。请注意,我们制作了一个自定义停用词列表并使用 anti_join() 删除它们;这是一种灵活的方法,可以在许多情况下使用。由于我们正在从整洁的数据框中删除单词,因此我们需要返回几步。
mystopwords <- tibble(word = c("eq", "co", "rc", "ac", "ak", "bn",
"fig", "file", "cg", "cb", "cm",
"ab", "_k", "_k_", "_x"))
physics_words <- anti_join(physics_words, mystopwords,
by = "word")
plot_physics <- physics_words %>%
bind_tf_idf(word, author, n) %>%
mutate(word = str_remove_all(word, "_")) %>%
group_by(author) %>%
slice_max(tf_idf, n = 15) %>%
ungroup() %>%
mutate(word = fct_reorder(word, tf_idf)) %>%
mutate(author = factor(author, levels = c("Galilei, Galileo",
"Huygens, Christiaan",
"Tesla, Nikola",
"Einstein, Albert")))
ggplot(plot_physics, aes(tf_idf, word, fill = author)) +
geom_col(show.legend = FALSE) +
facet_wrap(~author, ncol = 2, scales = "free") +
labs(x = "tf-idf", y = NULL)
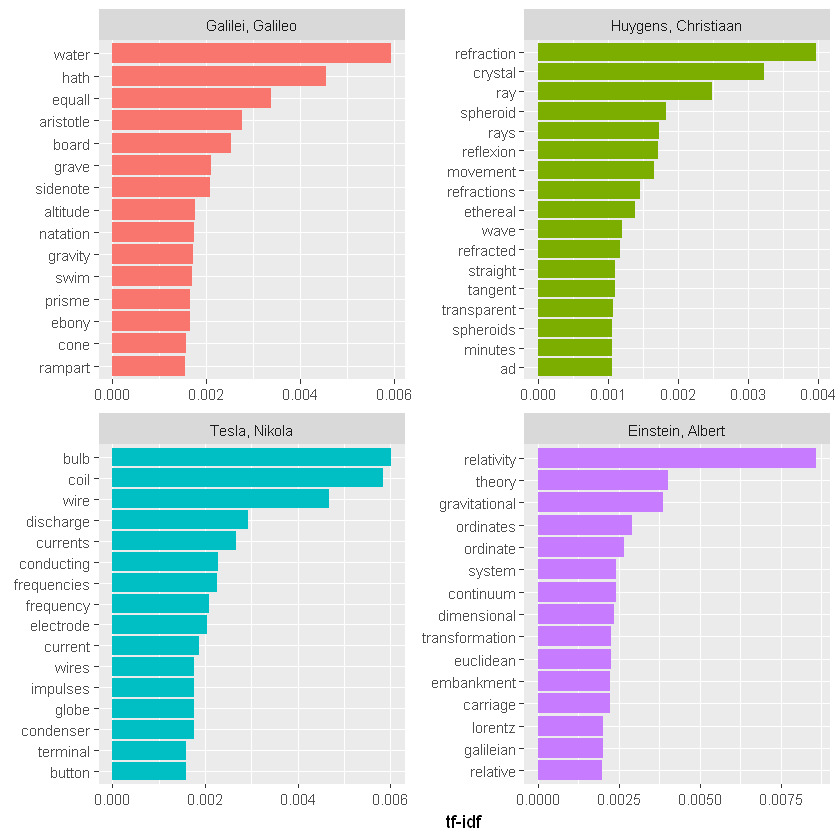
我们可以从上图得出的一件事是,本章中的简奥斯汀和物理示例在跨类别(书籍、作者)的高 tf-idf 单词中没有太多重叠。如果你发现你确实跨类别共享具有高 tf-idf 的单词,你可能想要使用
reorder_within()和scale_*_reordered()来创建可视化,这在后面的主题模型中会进行相关介绍
5.总结
使用词频和逆文档频率可以让我们在文档集合中找到一个文档的特征词,无论该文档是小说还是物理文本或网页。单独探索词频可以让我们深入了解语言在自然语言集合中的使用方式,而像 count() 和 rank() 这样的 dplyr 动词为我们提供了推理词频的工具。 tidytext 包使用符合 tidy data 原则的 tf-idf 实现,这使我们能够了解不同单词在文档集合或语料库中的文档中的重要性。
这篇文章主要是基于现有的英文文档库进行分析,后续会继续更新关于一些大家比较关注的中文文档的分析,例如《红楼梦》、《遮天》、《斗罗大陆》等一些文档的分析,✨✨✨大家的支持是我创作最大的动力!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号