记一次爬取bupt课表的经历
我超,糖丸了,bupt课表可以下载的.
由于打开北邮课表的步骤实在是太繁琐,竟然要整整5步(而且企业微信还一卡一卡的),于是就想写一份爬虫把课表给弄下来。
我这里选择了教务系统里的那个课表进行爬取,网址是:https://jwgl.bupt.edu.cn/jsxsd/
登录很好办,直接找到下图里的请求表单,把UserAccount,userPassword、encoded给POST上去就行了。
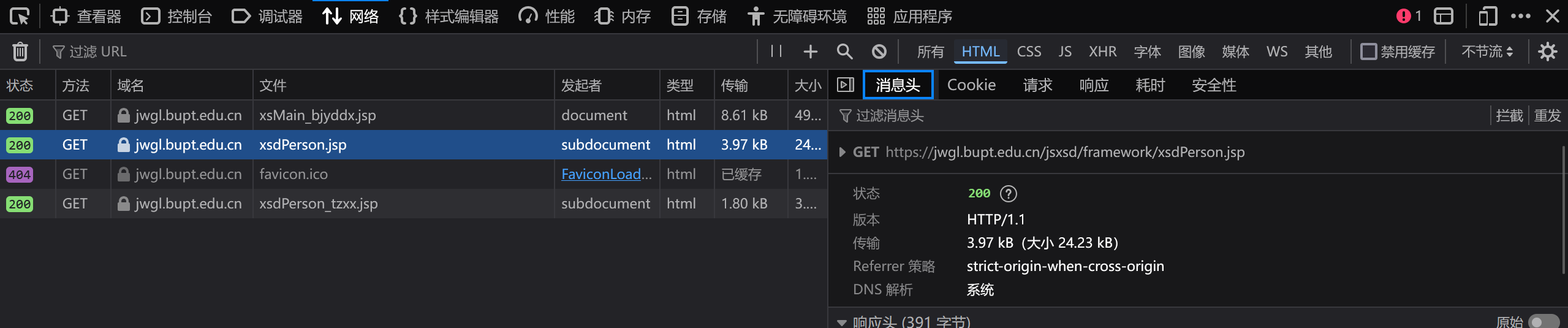
刚研究了一下就发现这玩意怎么是js动态加载的啊,本来想用selenium的,但觉得太麻烦了(实际上是忘得一干二净)。于是就决定手动把源文件给找出来。找了好半天,终于找到了这个。点进去发现这里面加载了课程表的源html。
这下就好办了,分析源码发现课程都在有table-class标签的html中,并且有day?作为时间标识(暂时不想搞了),一个soup.findall直接拿下,以下是源码。
import requests
from bs4 import BeautifulSoup
login_url = "https://jwgl.bupt.edu.cn/jsxsd/xk/LoginToXk"
payload = {
"userAccount": "",
"userPassword": "",
"encoded": ""
}
session = requests.Session()
response = session.post(login_url, data=payload)
if response.status_code == 200:
print("登录成功")
else:
print(f"登录失败,状态码: {response.status_code}")
url = "https://jwgl.bupt.edu.cn/jsxsd/framework/xsdPerson.jsp"
response2 = session.get(url=url)
if response2.status_code == 200:
soup = BeautifulSoup(response2.text, 'html.parser')
items = soup.find_all(class_="table-class")
for item in items:
print(item.text)
else:
print(f"Failed to retrieve page, status code: {response.status_code}")

