


ShardingSphere-Proxy 安装和同库分表
安装与配置:
- 版本说明:
- mysql:8.0.21
- ShardingSphere-Proxy:5.1.1
- 官网下载 ShardingSphere-Proxy,地址:https://shardingsphere.apache.org/document/current/cn/downloads/
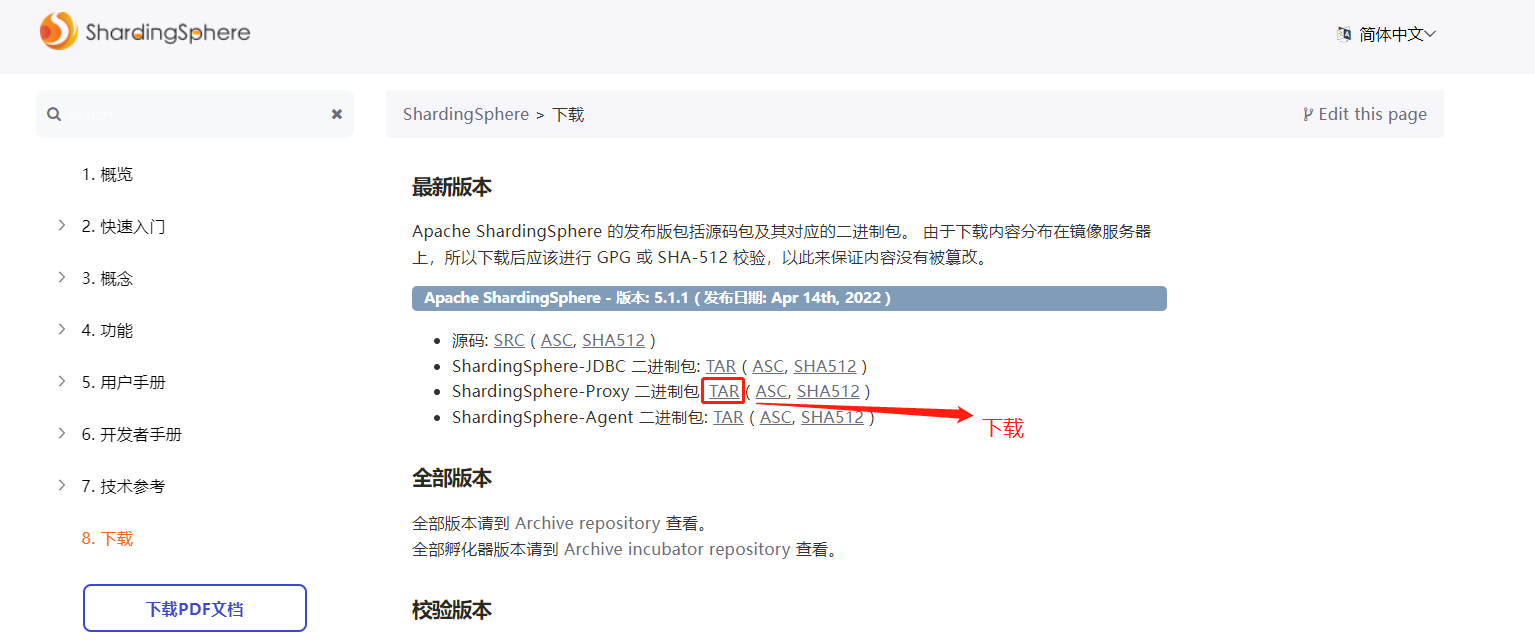
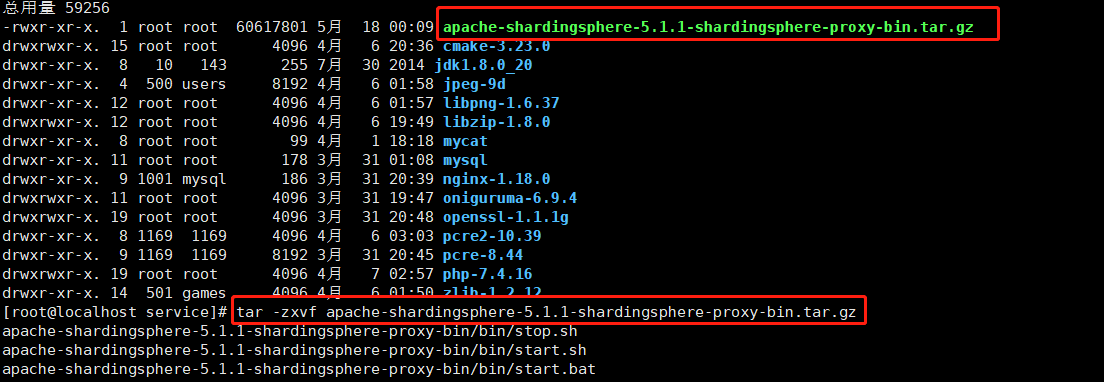
- 解压安装,安装目录自定义。本文路径:/wwwroot/service
- 由于解压后的目录名称太长了,我把他改成了“apache-shardingsphere-5.1.1”,所以完整路径为“/wwwroot/service/apache-shardingsphere-5.1.1”
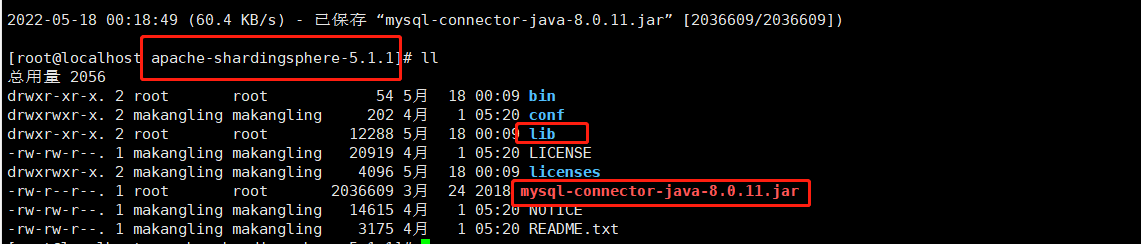
- 因为我用的是MySql,所以要引入jar包
- jar包下载地址:https://shardingsphere.apache.org/document/current/cn/quick-start/shardingsphere-proxy-quick-start/
- 或者使用wget下载:wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.11/mysql-connector-java-8.0.11.jar
- 我是在apache-shardingsphere-5.1.1目录下用wget下载的
- 只要把mysql-connector-java-8.0.11.jar放入lib目录中即可
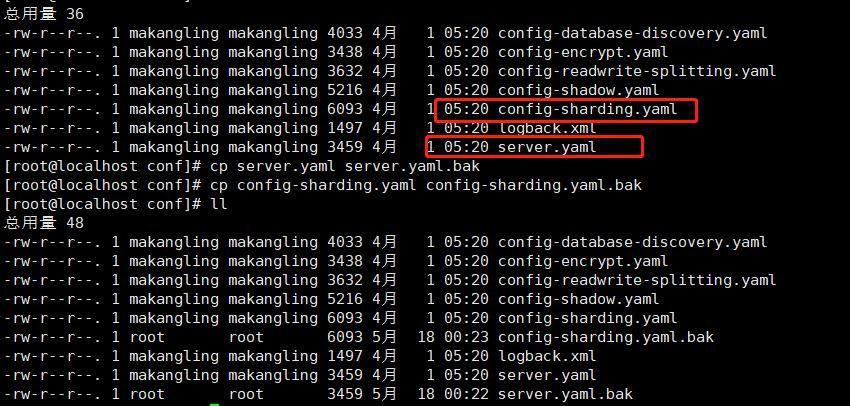
- 进入conf目录修改配置
- 主要的配置文件是“config-sharding.yaml”和“server.yaml”。为了防止改错,我备份了这个两个文件。
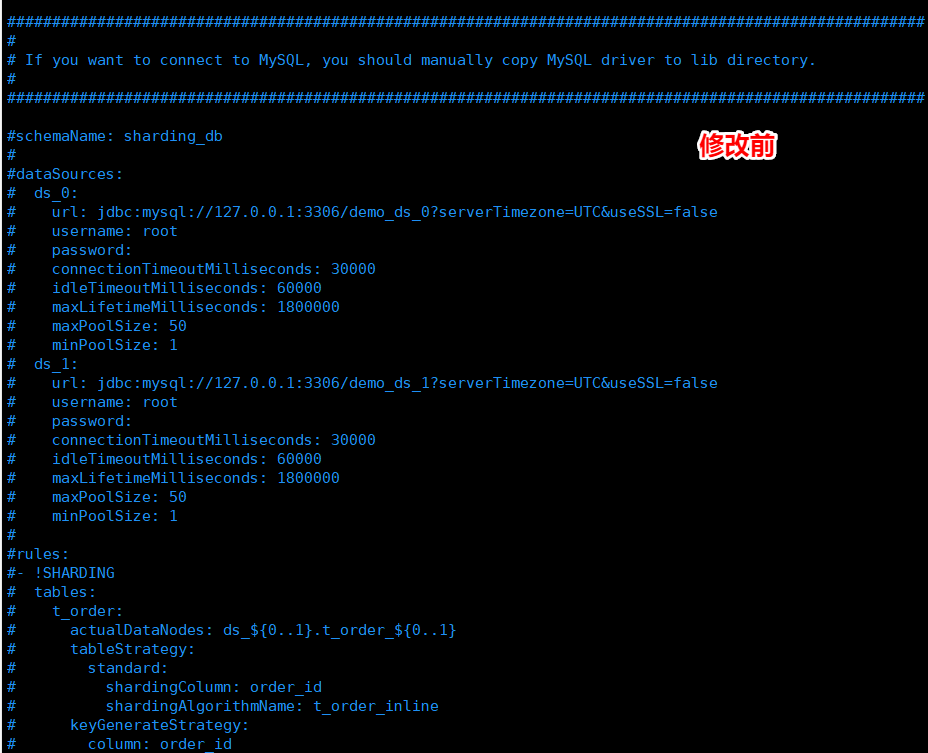
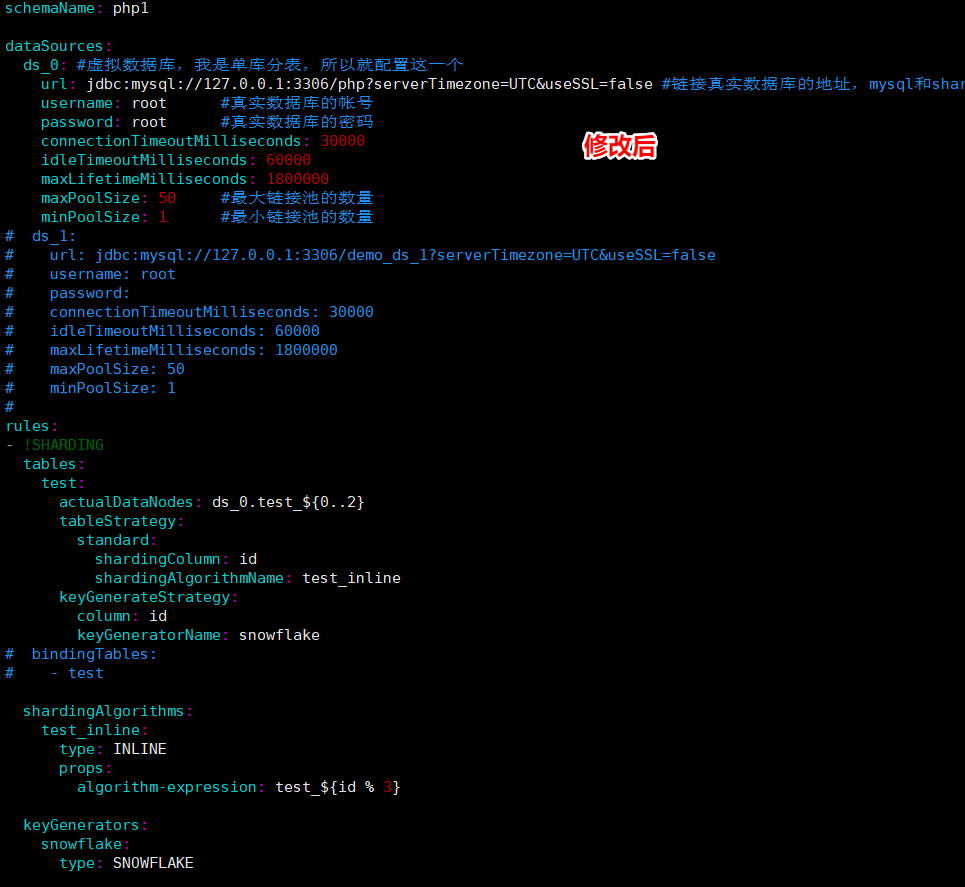
- vim config-sharding.yaml 打开配置文件,找到图中的内容进行修改。
- 修改内容如下:
schemaName: php1 #虚拟数据库名称,在链接shardingsphere-proxy后出现的数据库名称 dataSources: ds_0: #虚拟数据库,我是单库分表,所以就配置这一个 url: jdbc:mysql://127.0.0.1:3306/php?serverTimezone=UTC&useSSL=false #链接真实数据库的地址,mysql和shardingsphere-proxy都是安装在一个服务器,所以地址是127.0.0.1。“demo_ds_0”改成“php”,“php”是我真实数据库的名称 username: root #真实数据库的帐号 password: root #真实数据库的密码 connectionTimeoutMilliseconds: 30000 #连接超时控制,毫秒 idleTimeoutMilliseconds: 60000 #连接空闲时间设置,毫秒 maxLifetimeMilliseconds: 1800000 #连接的最大持有时间,0 为无限制 maxPoolSize: 50 #最大链接池的数量 minPoolSize: 1 #最小链接池的数量 # ds_1: # url: jdbc:mysql://127.0.0.1:3306/demo_ds_1?serverTimezone=UTC&useSSL=false # username: root # password: # connectionTimeoutMilliseconds: 30000 # idleTimeoutMilliseconds: 60000 # maxLifetimeMilliseconds: 1800000 # maxPoolSize: 50 # minPoolSize: 1 # rules: - !SHARDING tables: test: #对应真实数据库中要分表的表名(包括表前缀) actualDataNodes: ds_0.test_${0..2} #ds_0是dataSources下配置的虚拟数据库名称,test_${1..3}表示真实表(包含表前缀),分表分成了三个test_0,test_1,test_2 tableStrategy: #分表策略 standard: #用于单分片键的标准分片场景 shardingColumn: id #分片列名称,真实test表中用于分表的字段 shardingAlgorithmName: test_inline #分片算法名称,与shardingAlgorithms下的test_inline对应 keyGenerateStrategy: # 分布式序列策略 column: id # 自增列名称,缺省表示不使用自增主键生成器 keyGeneratorName: snowflake # 分布式序列算法名称 shardingAlgorithms: #分片算法配置 test_inline: #分片算法名称 type: INLINE #分片算法类型 props: #分片算法属性配置 algorithm-expression: test_${id % 3} keyGenerators: # 分布式序列算法配置 snowflake: # 分布式序列算法名称,与keyGeneratorName对应 type: SNOWFLAKE # 分布式序列算法类型,当前是雪花算法
- vim server.yaml 打开配置文件,找到图中的内容进行修改。
- 修改内容如下:
rules: - !AUTHORITY users: - root@%:root #真是数据库的帐号:密码 provider: type: ALL_PRIVILEGES_PERMITTED


- 修改完配置后到安装目录(本文:/wwwroot/service/apache-shardingsphere-5.1.1)下的bin目录去启动服务
- bin目录中有三个文件,内容如下:
start.bat #window下启动文件 start.sh #linux下启动文件 stop.sh #linux下停止文件
- 在bin目录中执行“./start.sh 3307”就可以启动文件(3307表示使用的端口号),执行结果如下:
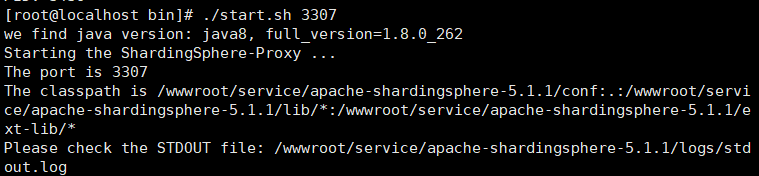
- 想知道是否启动成功,可以看启动日志,上图已经告诉了日志的路径。
- “vim /wwwroot/service/apache-shardingsphere-5.1.1/logs/stdout.log”就可以查看日志内容,看到图中内容表示启动成功:
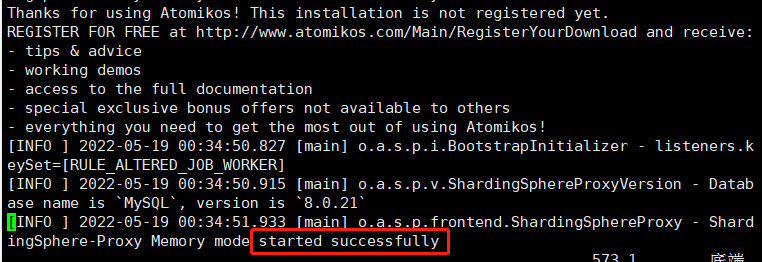
测试:
- 连接ShardingSphere-Proxy,执行命令:
mysql -uroot -p -P3307 -h192.168.25.150 #-u server.yaml配置中的帐号 #-p server.yaml配置中的密码 #-P 启动服务时的端口号 #-h ShardingSphere-Proxy服务所在的服务器地址
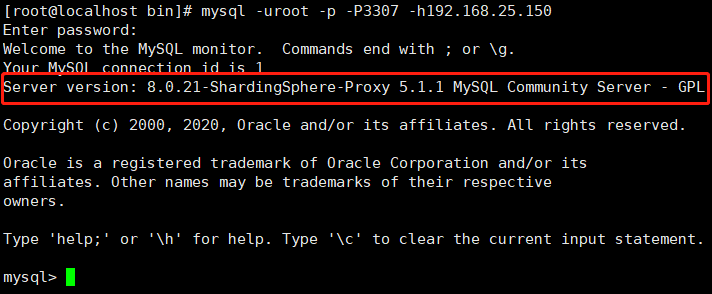
- 结果如下,表示连接成功:
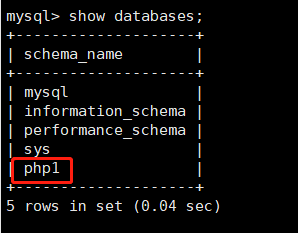
- “show databases;” 可以查看所有的数据库,结果如下图。“php1”就是我们配置中的虚拟数据库名称。
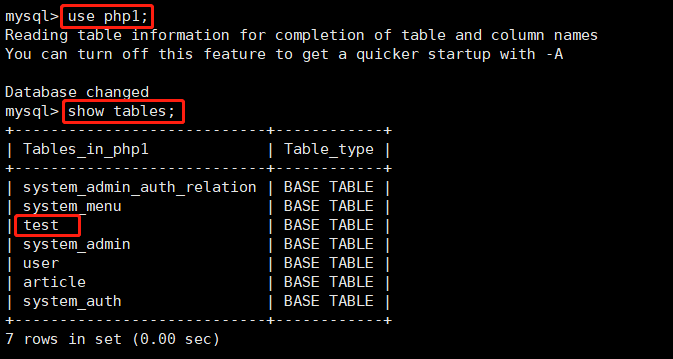
- 执行“use php1;”选择数据库
- 执行“show tables;”查看数据库中的所有表,结果如下图:
- 查看三张表中的现有数据,如下图,三张表都是空数据:



- 执行“insert into test (title) values ('zhangsan');”插入一条数据,在查看结果:


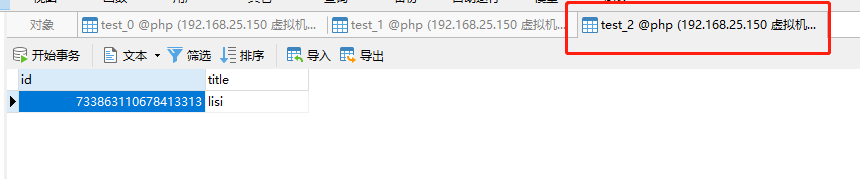
- 执行“insert into test (title) values ('lisi');”插入一条数据,在查看结果:

- 执行“insert into test (title) values ('wangwu');”插入一条数据,在查看结果:


- 执行“insert into test (title) values ('zhaoliu');”插入一条数据,在查看结果:


- 到此测试完成,都能存入各个表中。
问题:
- 途中遇到的问题,在插入数据的时候出现下图的错误:

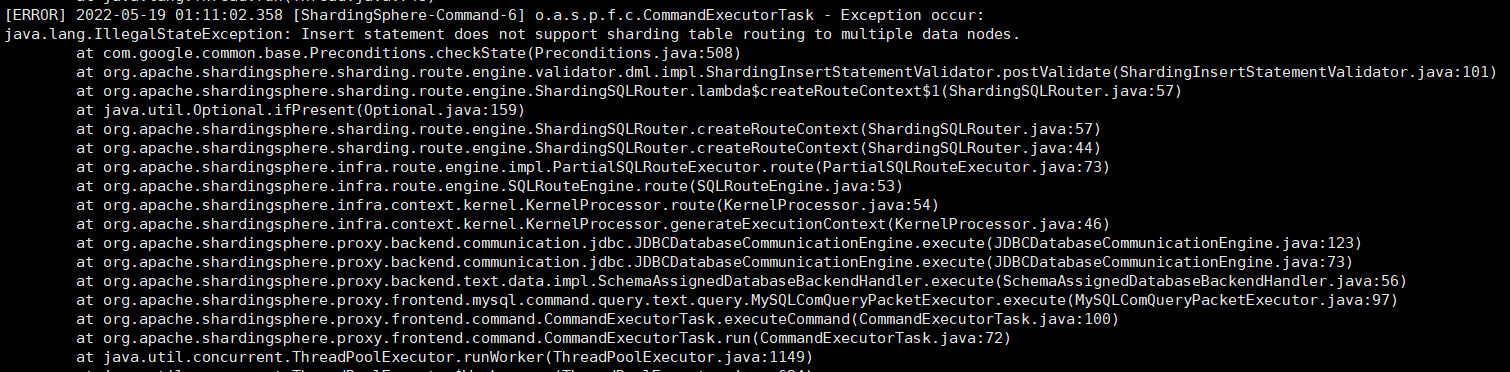
- 解决问题:
- 在配置“config-sharding.yaml”时少写了些配置项,补上后重新启动ShardingSphere-Proxy后即可
#出现问题的配置: rules: - !SHARDING tables: test: #对应真实数据库中要分表的表名(包括表前缀) actualDataNodes: ds_0.test_${0..2} #ds_0是dataSources下配置的虚拟数据库名称,test_${1..3}表示真实表(包含表前缀),分表分成了三个test_0,test_1,test_2 tableStrategy: #分表策略 standard: #用于单分片键的标准分片场景 shardingColumn: id #分片列名称,真实test表中用于分表的字段 shardingAlgorithmName: test_inline #分片算法名称,与shardingAlgorithms下的test_inline对应 shardingAlgorithms: #分片算法配置 test_inline: #分片算法名称 type: INLINE #分片算法类型 props: #分片算法属性配置 algorithm-expression: test_${id % 3} #修改后的配置: rules: - !SHARDING tables: test: #对应真实数据库中要分表的表名(包括表前缀) actualDataNodes: ds_0.test_${0..2} #ds_0是dataSources下配置的虚拟数据库名称,test_${1..3}表示真实表(包含表前缀),分表分成了三个test_0,test_1,test_2 tableStrategy: #分表策略 standard: #用于单分片键的标准分片场景 shardingColumn: id #分片列名称,真实test表中用于分表的字段 shardingAlgorithmName: test_inline #分片算法名称,与shardingAlgorithms下的test_inline对应 keyGenerateStrategy: column: id keyGeneratorName: snowflake shardingAlgorithms: #分片算法配置 test_inline: #分片算法名称 type: INLINE #分片算法类型 props: #分片算法属性配置 algorithm-expression: test_${id % 3} keyGenerators: snowflake: type: SNOWFLAKE #雪花算法
本文来自博客园,作者:疯子丶pony,转载请注明原文链接:https://www.cnblogs.com/mklblog/articles/16289415.html

