
spark中生成RDD时分区规则是怎样的?(只需要看getPartitions方法的逻辑就可以了)
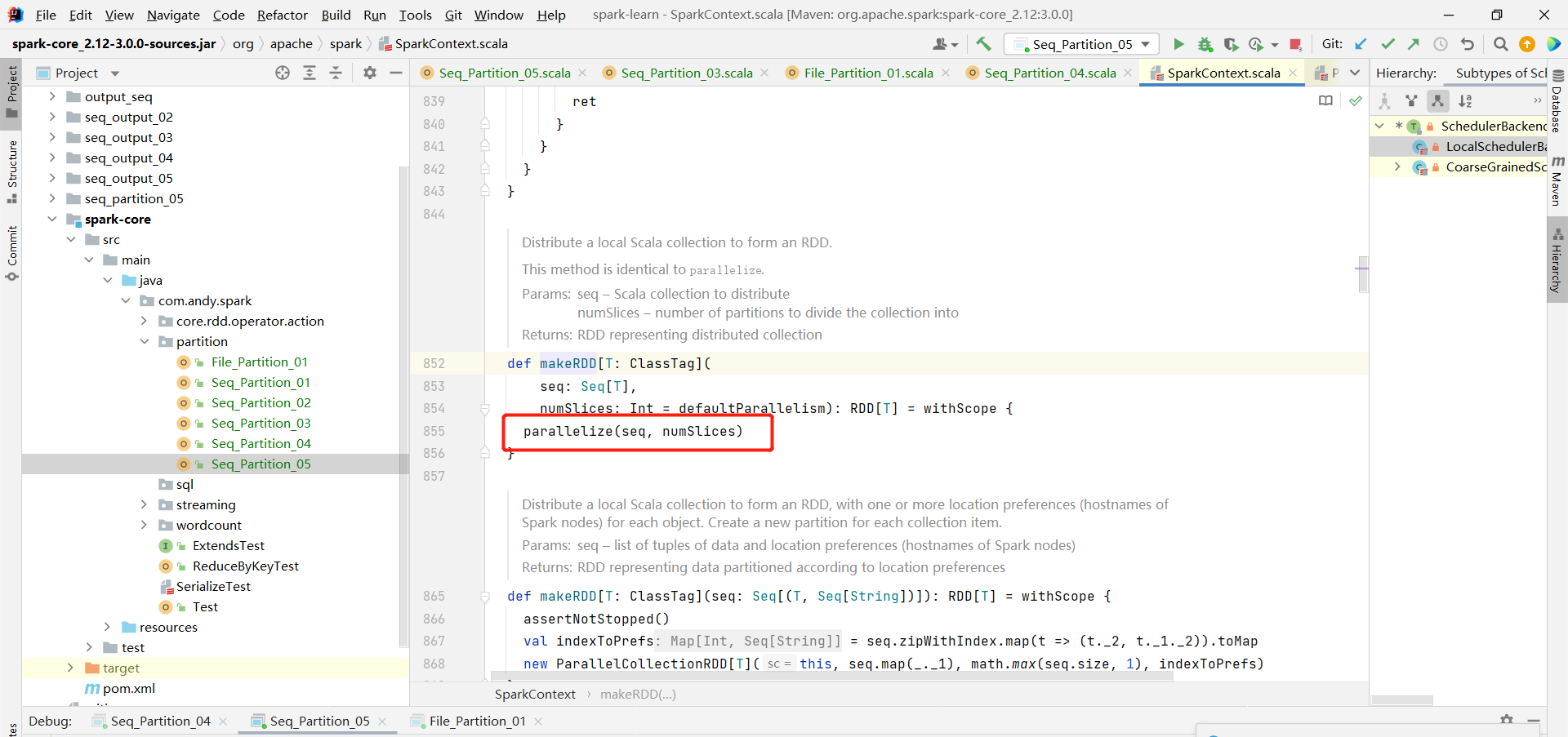
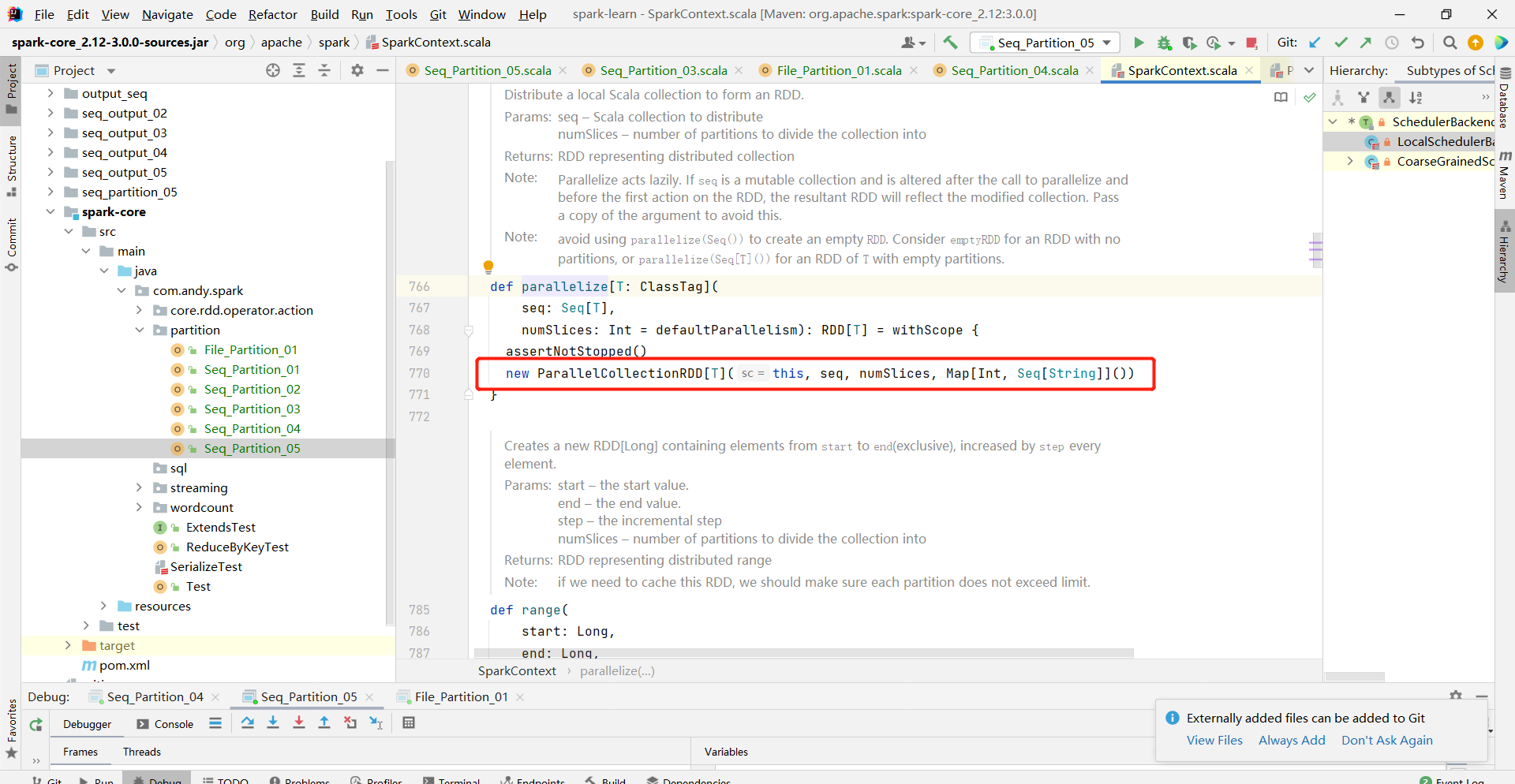
org.apache.spark.rdd.ParallelCollectionRDD#getPartitions
org.apache.spark.rdd.HadoopRDD#getPartitions


需要注意的是getPartitions方法的触发时机是在行动算子执行的时候触发:


org.apache.spark.rdd.ParallelCollectionRDD#getPartitions
org.apache.spark.rdd.HadoopRDD#getPartitions
需要注意的是getPartitions方法的触发时机是在行动算子执行的时候触发:

