

redis cluster故障切换(有故障的master是怎么从GOOD变到PFAIL最后变成FAIL的)
具体的流程图如下:
需要注意的是,无论是主观下线,还是客观下线,参与方包括Master、slave全部的未出现故障的节点。(比如下图的节点A,可以是master也可以是slave)
1:主观下线PFAIL

2:客观下线FAIL,需要多个节点达成共识

Redis集群选举机制
当slave发现自己的master变为FAIL状态时,便尝试发起选举,以期成为新的master。由于挂掉的master可能会有多个slave,从而存在多个slave竞争成为master节点的过程, 其过程如下:
1.slave发现自己的master变为FAIL
2.将自己记录的集群currentEpoch(选举轮次标记)加1,并广播信息给集群中其他节点
3.其他节点收到该信息,只有master响应,判断请求者的合法性,并发送结果
4.尝试选举的slave收集master返回的结果,收到超过半数master的统一后变成新Master
5.广播Pong消息通知其他集群节点。
如果这次选举不成功,比如三个小的主从A,B,C组成的集群,A的master挂了,A的两个小弟发起选举,结果B的master投给A的小弟A1,C的master投给了A的小弟A2,这样就会发起第二次选举,选举轮次标记+1继续上面的流程。事实上从节点并不是在主节点一进入 FAIL 状态就马上尝试发起选举,而是有一定延迟,一定的延迟确保我们等待FAIL状态在集群中传播,slave如果立即尝试选举,其它masters或许尚未意识到FAIL状态,可能会拒绝投票。 同时下面公式里面的随机数,也可以有效避免slave同时发起选举,导致的平票情况。
•延迟计算公式:
DELAY = 500ms + random(0 ~ 500ms) + SLAVE_RANK * 1000ms
•SLAVE_RANK表示此slave已经从master复制数据的总量的rank。Rank越小代表已复制的数据越新。这种方式下,持有最新数据的slave将会首先发起选举(理论上)。
前面说到这种分片的集群模式的集群可以部分提供服务,当redis.conf的配置cluster-require-full-coverage为no时,表示当一个小主从整体挂掉的时候集群也可以用,也是说0-16383个槽位中,落在该主从对应的slots上面的key是用不了的,但是如果key落在其他的范围是仍然可用的。
如果出现故障的master有多个slave,偏移量offset小的slave有可能当选吗?
这个问题我不知道,有知道的朋友可以在下面留言。
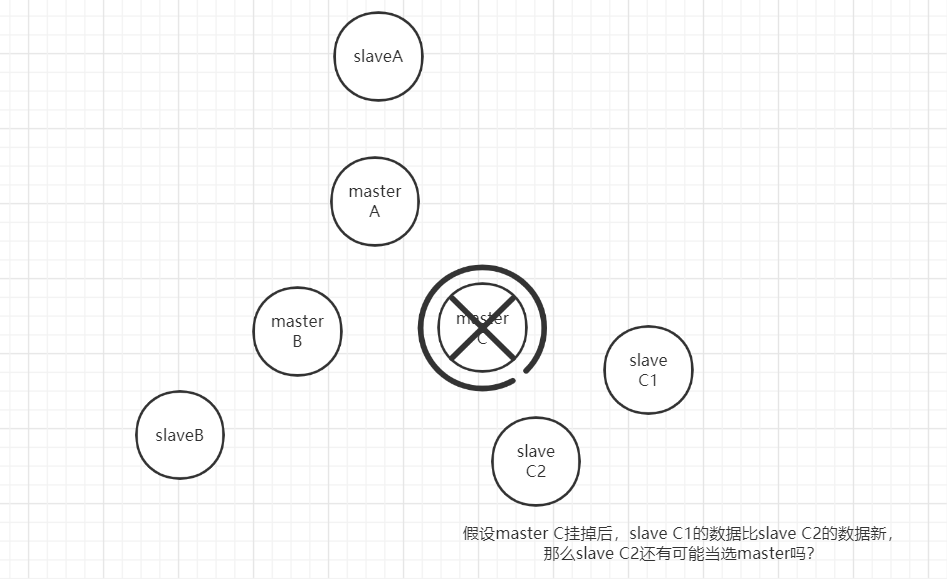
实际上,由于网络是不可靠的,网络波动会导致slave C1到master A,master B的请求,并不一定比slave C2到masterA, master B先到达。(虽然按照上面的延迟公司,slave C1先发起请求)
另外一个需要考虑的是,即使slave C1的数据比较新,也不能保证master C的全部数据都同步到了slave C1。既然数据丢失是一定存在的,选slave C1和选slave C2作为master的影响也就没有那么大了。

