

Zookeeper并不保证读取的是最新数据
Zookeeper并不保证读取的是最新数据
如果是对zk进行读取操作,读取到的数据可能是过期的旧数据,不是最新的数据。
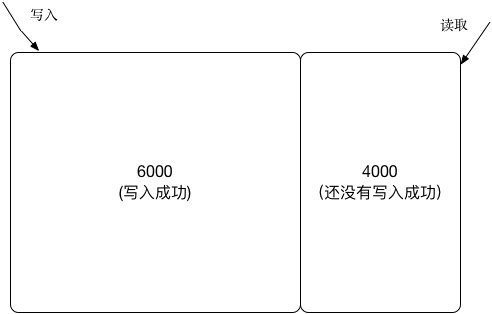
已上图为例,如果一个zk集群有10000台节点,当进行写入的时候,如果已经有6K个节点写入成功,zk就认为本次写请求成功。但是这时候如果一个客户端读取的刚好是另外4K个节点的数据,那么读取到的就是旧的过期数据。
在zk的官方文档中对此有解释,地址在:https://zookeeper.apache.org/doc/r3.1.2/zookeeperProgrammers.html
zookeeper一致性的保证:
ZooKeeper是一种高性能,可扩展的服务,虽然读取速度比写入快,但是读取和写入操作都设计的极为快速,这样做的原因是在读取的情况下,ZooKeeper可能会提供较旧的数据,但这是为了ZooKeeper的一致性保证:
- 顺序一致性:来自客户端的更新将按照发送的顺序被写入到zk
- 原子性:更新操作要么成功要么失败,没有中间状态
- 单系统快照:客户端将看到服务的相同视图,而不管它连接到的服务器。
- 可靠性:一旦应用更新,数据将被持久化,直到数据被再次更新,对于该保证有两个推论:1、如果客户端得到了成功的返回码,说明写入成功,数据被持久化,如果出现了通信错误,超时等一些故障,客户端将不知道更新是否已应用。我们采取措施尽量减少失败,但唯一的保证是只有成功的返回码。 (这在Paxos中称为单调性条件。)2、如果客户端已经读取到了数据或者写入成功了数据,都不会因为zk的失败而导致回滚;
- 及时性:在一段时间后,客户端将看到最新的系统更新,在此期间客户端将看到这种变更。
有时开发人员错误地假定ZooKeeper实际上没有做出另一个保证:跨客户端的强一致性
ZooKeeper并不保证在每个实例中,两个不同的客户端将具有相同的ZooKeeper数据的视图。由于诸如网络延迟的因素,一个客户端可以在另一客户端被通知该改变之前执行更新,考虑两个客户端A和B的场景。如果客户端A将znode / a的值从0设置为1,则告诉客户端B读取/ a,则客户端B可以读取旧值0,这取决于它连接到的服务器。如果客户端A和客户端B读取相同的值很重要,则客户端B应该在执行读取之前从ZooKeeper API方法调用sync()方法。
zk的sync方法的解释:异步的实现当前进程与leader之间的指定path的数据同步;
CAP理论
在理论计算机科学中,CAP定理(CAP theorem),又被称作布鲁尔定理(Brewer’s theorem),它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性(Consistence) (等同于所有节点访问同一份最新的数据副本)
- 可用性(Availability)(每次请求都能获取到非错的响应——但是不保证获取的数据为最新数据)
- 分区容错性(Network partitioning)(以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。)
根据定理,分布式系统只能满足三项中的两项而不可能满足全部三项。理解CAP理论的最简单方式是想象两个节点分处分区两侧。允许至少一个节点更新状态会导致数据不一致,即丧失了C性质。如果为了保证数据一致性,将分区一侧的节点设置为不可用,那么又丧失了A性质。除非两个节点可以互相通信,才能既保证C又保证A,这又会导致丧失P性质
对于zookeeper来说,它实现了A可用性、P分区容错性、C中的写入强一致性,丧失的是C中的读取一致性。
有所丧失,才有所获得,没有十全十美。

