函数式编程(模块基础、模块跨域调用、常用模块)
、模块简介
在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护。
为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式。在Python中,一个.py文件就称之为一个模块(Module)。
使用模块有什么好处?
- 最大的好处是大大提高了代码的可维护性。其次,编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。我们在编写程序的时候,也经常引用其他模块,包括Python内置的模块和来自第三方的模块。
- 使用模块还可以避免函数名和变量名冲突。每个模块有独立的命名空间,因此相同名字的函数和变量完全可以分别存在不同的模块中,所以,我们自己在编写模块时,不必考虑名字会与其他模块冲突
模块分类
模块分为三种:
- 内置标准模块(又称标准库)执行help('modules')查看所有python自带模块列表
- 第三方开源模块,可通过pip install 模块名 联网安装
- 自定义模块
模块调用
import module
from module import xx
from module.xx.xx import xx as rename
from module.xx.xx import *
注意:模块一旦被调用,即相当于执行了另外一个py文件里的代码
自定义模块
这个最简单, 创建一个.py文件,就可以称之为模块,就可以在另外一个程序里导入
模块查找路径
发现,自己写的模块只能在当前路径下的程序里才能导入,换一个目录再导入自己的模块就报错说找不到了, 这是为什么?
这与导入路径有关
import sys
print(sys.path)
输出
['', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python36.zip',
'/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6',
'/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/lib-dynload',
'/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages']
python解释器会按照列表顺序去依次到每个目录下去匹配你要导入的模块名,只要在一个目录下匹配到了该模块名,就立刻导入,不再继续往后找。
注意列表第一个元素为空,即代表当前目录,所以你自己定义的模块在当前目录会被优先导入。
开源模块安装、使用
https://pypi.python.org/pypi 是python的开源模块库,截止2017年9.30日 ,已经收录了118170个来自全世界python开发者贡献的模块,几乎涵盖了你想用python做的任何事情。 事实上每个python开发者,只要注册一个账号就可以往这个平台上传你自己的模块,这样全世界的开发者都可以容易的下载并使用你的模块。那如何从这个平台上下载代码呢?
1.直接在上面这个页面上点download,下载后,解压并进入目录,执行以下命令完成安装
编译源码 python setup.py build
安装源码 python setup.py install
- 直接通过pip安装
pip3 install paramiko #paramiko 是模块名
pip命令会自动下载模块包并完成安装。
软件一般会被自动安装你python安装目录的这个子目录里
/your_python_install_path/3.6/lib/python3.6/site-packages
pip命令默认会连接在国外的python官方服务器下载,速度比较慢,你还可以使用国内的豆瓣源,数据会定期同步国外官网,速度快好多
sudo pip install -i http://pypi.douban.com/simple/ alex_sayhi --trusted-host pypi.douban.com #alex_sayhi是模块名
使用
下载后,直接导入使用就可以,跟自带的模块调用方法无差,演示一个连接linux执行命令的模块#coding:utf-8
import paramiko
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect('192.168.1.108', 22, 'alex', '123')
stdin, stdout, stderr = ssh.exec_command('df')
print(stdout.read())
ssh.close();
执行命令 - 通过用户名和密码连接服务器
包(Package)
当你的模块文件越来越多,就需要对模块文件进行划分,比如把负责跟数据库交互的都放一个文件夹,把与页面交互相关的放一个文件夹,
.
└── my_proj
├── crm #代码目录
│ ├── admin.py
│ ├── apps.py
│ ├── models.py
│ ├── tests.py
│ └── views.py
├── manage.py
└── my_proj #配置文件目录
├── settings.py
├── urls.py
└── wsgi.py
像上面这样,一个文件夹管理多个模块文件,这个文件夹就被称为包
那不同包之间的模块互相导入呢?
crm/views.py内容
def sayhi():
print('hello world!')
通过manage.py调用
from crm import views
views.sayhi()
执行manage.py (注意这里用python2)
Alexs-MacBook-Pro:my_proj alex$ ls
crm manage.py my_proj
Alexs-MacBook-Pro:my_proj alex$ python manage.py
Traceback (most recent call last):
File "manage.py", line 6, in <module>
from crm import views
ImportError: No module named crm
竟然说找不到模块,为什么呢?
包就是文件夹,但该文件夹下必须存在 __init__.py 文件, 该文件的内容可以为空。__int__.py用于标识当前文件夹是一个包。
在crm目录下创建一个空文件__int__.py ,再执行一次就可以了
Alexs-MacBook-Pro:my_proj alex$ touch crm/__init__.py #创建一个空文件
Alexs-MacBook-Pro:my_proj alex$
Alexs-MacBook-Pro:my_proj alex$ ls crm/
__init__.py admin.py models.py views.py
__pycache__ apps.py tests.py views.pyc
Alexs-MacBook-Pro:my_proj alex$ python manage.py
hello world!
注意,在python3里,即使目录下没__int__.py文件也能创建成功,猜应该是解释器优化所致,但创建包还是要记得加上这个文件 吧。
二、模块跨域调用
跨模块导入
目录结构如下
.
├── __init__.py
├── crm
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── models.py
│ ├── tests.py
│ ├── views.py
├── manage.py
└── proj
├── __init__.py
├── settings.py
├── urls.py
└── wsgi.py
根据上面的结构,如何实现在crm/views.py里导入proj/settings.py模块?
直接导入的话,会报错,说找到不模块
$ python3 views.py
Traceback (most recent call last):
File "views.py", line 2, in <module>
from proj import settings
ModuleNotFoundError: No module named 'proj'
是因为路径找不到,proj/settings.py 相当于是crm/views.py的父亲(crm)的兄弟(proj)的儿子(settings.py),settings.py算是views.py的表弟啦,在views.py里只能导入同级别兄弟模块代码,或者子级别包里的模块,根本不知道表弟表哥的存在。这可怎么办呢?
答案是添加环境变量,把父亲级的路径添加到sys.path中,就可以了,这样导入 就相当于从父亲级开始找模块了。
crm/views.py中添加环境变量
import sys ,os
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) #__file__的是打印当前被执行的模块.py文件相对路径,注意是相对路径
print(BASE_DIR)
sys.path.append(BASE_DIR)
from proj import settings
def sayhi():
print('hello world!')
print(settings.DATABASES)
输出
$ python3 views.py
/Users/alex/Documents/work/PyProjects/luffy_课件/21天入门/chapter4-常用模块/packages/my_proj
---my proj init--- #proj/__init__.py输出
in proj/settings.py #proj/settings.py输出
{'host': 'localhost'}
*注意;此时在proj/settings.py写上import urls会有问题么?
DATABASES= {
'host':'localhost'
}
import urls #这行刚加的
print('in proj/settings.py')
结果报错了
ModuleNotFoundError: No module named 'urls'
为什么呢? 因为现在的程序入口是views.py , 你在settings.py导入import urls,其实相当于在crm目录找urls.py,而不是proj目录,若想正常导入,要改成如下
DATABASES= {
'host':'localhost'
}
from proj import urls #proj这一层目录已经添加到sys.path里,可以直接找到
print('in proj/settings.py')
绝对导入&相对导入
在linux里可以通过cd ..回到上一层目录 ,cd ../.. 往上回2层,这个..就是指相对路径,在python里,导入也可以通过..
例如:
.
├── __init__.py
├── crm
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── models.py
│ ├── tests.py
│ ├── views.py #from ..proj import settings
├── manage.py
└── proj
├── __init__.py
├── settings.py #from .import urls
├── urls.py
└── wsgi.py
views.py里代码
from ..proj import settings
def sayhi():
print('hello world!')
print(settings.DATABASES)
执行结果报错了
Traceback (most recent call last):
File "my_proj/crm/views.py", line 4, in <module>
from ..proj import settings
SystemError: Parent module '' not loaded, cannot perform relative import
或者有人会看到这个错
ValueError: attempted relative import beyond top-level package
其实这两个错误的原因归根结底是一样的:在涉及到相对导入时,package所对应的文件夹必须正确的被python解释器视作package,而不是普通文件夹。否则由于不被视作package,无法利用package之间的嵌套关系实现python中包的相对导入。
文件夹被python解释器视作package需要满足两个条件:
- 文件夹中必须有__init__.py文件,该文件可以为空,但必须存在该文件。
- 不能作为顶层模块来执行该文件夹中的py文件(即不能作为主函数的入口)。
所以这个问题的解决办法就是,既然你在views.py里执行了相对导入,那就不要把views.py当作入口程序,可以通过上一级的manage.py调用views.py
.
├── __init__.py
├── crm
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── models.py
│ ├── tests.py
│ ├── views.py #from ..proj import settings
├── manage.py #from crm import views
└── proj
├── __init__.py
├── settings.py #from .import urls
├── urls.py
└── wsgi.py
事实证明还是不行,报错
ValueError: attempted relative import beyond top-level package
但把from ..proj import settings 改成from . import models 后却执行成功了,为什么呢?
from .. import models会报错的原因是,这句代码会把manage.py所在的这一层视作package,但实际上它不是,因为package不能是顶层入口代码,若想不出错,只能把manage.py往上再移一层。
import sys,os #sys.path.append('E:\python学习\函数式编程\module\my_proj') #方法一 增加程序的绝对路径,但是不能移植 PATH_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) #方法二,获取需要执行模块的绝对路径,添加到啥意思sys.path中 #__file__ 获取当前文件的名称 # os.path.abspath 获取文件绝对路径 # os.path.dirname 返回上一层目录名称 注:这里用了两次的目的就是因为 setings模块在 proj目录中,我们先进入 proj 目录中,再去导入的 setings模块, #相当于 linux 中的 cd ../../ #必须使用第二种方法,可移植 sys.path.append(PATH_DIR) from proj import setings print('hello views') #输出 C:\Python\python.exe E:/python学习/函数式编程/module/my_proj/crm/views.py hello setings hello views
正确的代码目录结构如下
packages/
├── __init__.py
├── manage.py #from my_proj.crm import views
└── my_proj
├── crm
│ ├── admin.py
│ ├── apps.py
│ ├── models.py
│ ├── tests.py
│ ├── views.py #from . import models; from ..proj import settings
└── proj
├── __init__.py
├── settings.py
├── urls.py
└── wsgi.py
再执行manage.py就不会报错了。
注:虽然python支持相对导入,但对模块间的路径关系要求比较严格,处理不当就容易出错,so并不建议在项目里经常使用。
三、常用模块
time
时间模块
import sys,os #sys.path.append('E:\python学习\函数式编程\module\my_proj') #方法一 增加程序的绝对路径,但是不能移植 PATH_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) #方法二,获取需要执行模块的绝对路径,添加到啥意思sys.path中 #__file__ 获取当前文件的名称 # os.path.abspath 获取文件绝对路径 # os.path.dirname 返回上一层目录名称 注:这里用了两次的目的就是因为 setings模块在 proj目录中,我们先进入 proj 目录中,再去导入的 setings模块, #相当于 linux 中的 cd ../../ #必须使用第二种方法,可移植 sys.path.append(PATH_DIR) from proj import setings print('hello views') #输出 C:\Python\python.exe E:/python学习/函数式编程/module/my_proj/crm/views.py hello setings hello views
基本方法
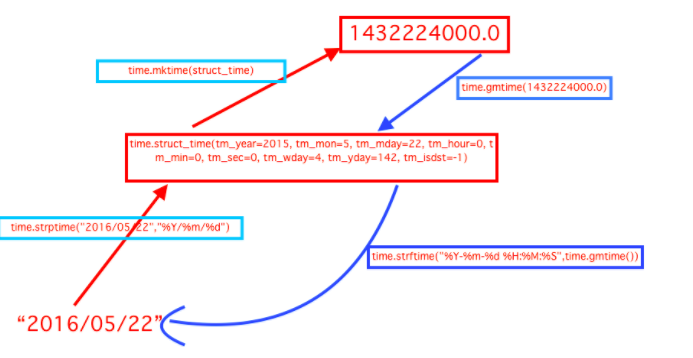
- time.localtime([secs]):将一个时间戳转换为当前时区的struct_time。secs参数未提供,则以当前时间为准。
- time.gmtime([secs]):和localtime()方法类似,gmtime()方法是将一个时间戳转换为UTC时区(0时区)的struct_time。
- time.time():返回当前时间的时间戳。
- time.mktime(t):将一个struct_time转化为时间戳。
- time.sleep(secs):线程推迟指定的时间运行。单位为秒。
- time.asctime([t]):把一个表示时间的元组或者struct_time表示为这种形式:'Sun Oct 1 12:04:38 2017'。如果没有参数,将会将time.localtime()作为参数传入。
- time.ctime([secs]):把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式。如果参数未给或者为None的时候,将会默认time.time()为参数。它的作用相当于time.asctime(time.localtime(secs))。
-
time.strftime(format[, t]):把一个代表时间的元组或者struct_time(如由time.localtime()和time.gmtime()返回)转化为格式化的时间字符串。如果t未指定,将传入time.localtime()。
- 举例:time.strftime("%Y-%m-%d %X", time.localtime()) #输出'2017-10-01 12:14:23'
-
time.strptime(string[, format]):把一个格式化时间字符串转化为struct_time。实际上它和strftime()是逆操作。
- 举例:time.strptime('2017-10-3 17:54',"%Y-%m-%d %H:%M") #输出 time.struct_time(tm_year=2017, tm_mon=10, tm_mday=3, tm_hour=17, tm_min=54, tm_sec=0, tm_wday=1, tm_yday=276, tm_isdst=-1)
关系转换图
datetime
相比于time模块,datetime模块的接口则更直观、更容易调用
datetime模块定义了下面这几个类:
- datetime.date:表示日期的类。常用的属性有year, month, day;
- datetime.time:表示时间的类。常用的属性有hour, minute, second, microsecond;
- datetime.datetime:表示日期时间。
- datetime.timedelta:表示时间间隔,即两个时间点之间的长度。
- datetime.tzinfo:与时区有关的相关信息。(这里不详细充分讨论该类,感兴趣的童鞋可以参考python
我们需要记住的方法仅以下几个:
- d=datetime.datetime.now() 返回当前的datetime日期类型
d.timestamp(),d.today(), d.year,d.timetuple()等方法可以调用
2.datetime.date.fromtimestamp(322222) 把一个时间戳转为datetime日期类型
3.时间运算
>>> datetime.datetime.now()
datetime.datetime(2017, 10, 1, 12, 53, 11, 821218)
>>> datetime.datetime.now() + datetime.timedelta(4) #当前时间 +4天
datetime.datetime(2017, 10, 5, 12, 53, 35, 276589)
>>> datetime.datetime.now() + datetime.timedelta(hours=4) #当前时间+4小时
datetime.datetime(2017, 10, 1, 16, 53, 42, 876275)
4.时间替换
>>> d.replace(year=2999,month=11,day=30) datetime.date(2999, 11, 30)
import datetime
d = datetime.datetime.now() #返回当前datetime 日期类型
print(d)
print(datetime.date.fromtimestamp(3222222))#将时间戳转换为 datetime日期类型
a = datetime.datetime(2018,4,5,11,3,10,821218)
#时间运算
b = a + datetime.timedelta(1)#当前时间加1天,这里默认是天当然也可以改为别的 days=None, seconds=None, microseconds=None, milliseconds=None, minutes=None, hours=None, weeks=None
print(b)
#时间替换
print(d.replace(year=1996,month=5,day=29))
#输出
2018-04-05 11:13:44.747020
1970-02-07
2018-04-06 11:03:10.821218
1996-05-29 11:13:44.747020
random
程序中有很多地方需要用到随机字符,比如登录网站的随机验证码,通过random模块可以很容易生成随机字符串
>>> random.randomrange(1,10) #返回1-10之间的一个随机数,不包括10 >>> random.randint(1,10) #返回1-10之间的一个随机数,包括10 >>> random.randrange(0, 100, 2) #随机选取0到100间的偶数 >>> random.random() #返回一个随机浮点数 >>> random.choice('abce3#$@1') #返回一个给定数据集合中的随机字符 '#' >>> random.sample('abcdefghij',3) #从多个字符中选取特定数量的字符 ['a', 'd', 'b'] #生成随机字符串 >>> import string >>> ''.join(random.sample(string.ascii_lowercase + string.digits, 6)) '4fvda1' #洗牌 >>> a [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> random.shuffle(a) >>> a
[3, 0, 7, 2, 1, 6, 5, 8, 9, 4]
os
提供了很多允许你的程序与操作系统直接交互的功能
OS模块得到当前工作目录,即当前Python脚本工作的目录路径: os.getcwd()
返回指定目录下的所有文件和目录名:os.listdir()
函数用来删除一个文件:os.remove()
删除多个目录:os.removedirs(r“c:\python”)
检验给出的路径是否是一个文件:os.path.isfile()
检验给出的路径是否是一个目录:os.path.isdir()
判断是否是绝对路径:os.path.isabs()
检验给出的路径是否真地存:os.path.exists()
返回一个路径的目录名和文件名:os.path.split() e.g os.path.split('/home/swaroop/byte/code/poem.txt') 结果:('/home/swaroop/byte/code', 'poem.txt')
分离扩展名:os.path.splitext() e.g os.path.splitext('/usr/local/test.py') 结果:('/usr/local/test', '.py')
获取路径名:os.path.dirname()
获得绝对路径: os.path.abspath()
获取文件名:os.path.basename()
运行shell命令: os.system()
读取操作系统环境变量HOME的值:os.getenv("HOME")
返回操作系统所有的环境变量: os.environ
设置系统环境变量,仅程序运行时有效:os.environ.setdefault('HOME','/home/alex')
给出当前平台使用的行终止符:os.linesep Windows使用'\r\n',Linux and MAC使用'\n'
指示你正在使用的平台:os.name 对于Windows,它是'nt',而对于Linux/Unix用户,它是'posix'
重命名:os.rename(old, new)
创建多级目录:os.makedirs(r“c:\python\test”)
创建单个目录:os.mkdir(“test”)
获取文件属性:os.stat(file)
修改文件权限与时间戳:os.chmod(file)
获取文件大小:os.path.getsize(filename)
结合目录名与文件名:os.path.join(dir,filename)
改变工作目录到dirname: os.chdir(dirname)
获取当前终端的大小: os.get_terminal_size()
杀死进程: os.kill(10884,signal.SIGKILL)

| 序号 | 方法及描述 |
|---|---|
| 1 |
检验权限模式 |
| 2 |
改变当前工作目录 |
| 3 |
设置路径的标记为数字标记。 |
| 4 |
更改权限 |
| 5 |
更改文件所有者 |
| 6 |
改变当前进程的根目录 |
| 7 |
关闭文件描述符 fd |
| 8 |
os.closerange(fd_low, fd_high) 关闭所有文件描述符,从 fd_low (包含) 到 fd_high (不包含), 错误会忽略 |
| 9 |
复制文件描述符 fd |
| 10 |
将一个文件描述符 fd 复制到另一个 fd2 |
| 11 |
通过文件描述符改变当前工作目录 |
| 12 |
改变一个文件的访问权限,该文件由参数fd指定,参数mode是Unix下的文件访问权限。 |
| 13 |
修改一个文件的所有权,这个函数修改一个文件的用户ID和用户组ID,该文件由文件描述符fd指定。 |
| 14 |
强制将文件写入磁盘,该文件由文件描述符fd指定,但是不强制更新文件的状态信息。 |
| 15 |
os.fdopen(fd[, mode[, bufsize]]) 通过文件描述符 fd 创建一个文件对象,并返回这个文件对象 |
| 16 |
返回一个打开的文件的系统配置信息。name为检索的系统配置的值,它也许是一个定义系统值的字符串,这些名字在很多标准中指定(POSIX.1, Unix 95, Unix 98, 和其它)。 |
| 17 |
返回文件描述符fd的状态,像stat()。 |
| 18 |
返回包含文件描述符fd的文件的文件系统的信息,像 statvfs() |
| 19 |
强制将文件描述符为fd的文件写入硬盘。 |
| 20 |
裁剪文件描述符fd对应的文件, 所以它最大不能超过文件大小。 |
| 21 |
返回当前工作目录 |
| 22 |
返回一个当前工作目录的Unicode对象 |
| 23 |
如果文件描述符fd是打开的,同时与tty(-like)设备相连,则返回true, 否则False。 |
| 24 |
设置路径的标记为数字标记,类似 chflags(),但是没有软链接 |
| 25 |
修改连接文件权限 |
| 26 |
更改文件所有者,类似 chown,但是不追踪链接。 |
| 27 |
创建硬链接,名为参数 dst,指向参数 src |
| 28 |
返回path指定的文件夹包含的文件或文件夹的名字的列表。 |
| 29 |
设置文件描述符 fd当前位置为pos, how方式修改: SEEK_SET 或者 0 设置从文件开始的计算的pos; SEEK_CUR或者 1 则从当前位置计算; os.SEEK_END或者2则从文件尾部开始. 在unix,Windows中有效 |
| 30 |
像stat(),但是没有软链接 |
| 31 |
从原始的设备号中提取设备major号码 (使用stat中的st_dev或者st_rdev field)。 |
| 32 |
以major和minor设备号组成一个原始设备号 |
| 33 |
递归文件夹创建函数。像mkdir(), 但创建的所有intermediate-level文件夹需要包含子文件夹。 |
| 34 |
从原始的设备号中提取设备minor号码 (使用stat中的st_dev或者st_rdev field )。 |
| 35 |
以数字mode的mode创建一个名为path的文件夹.默认的 mode 是 0777 (八进制)。 |
| 36 |
创建命名管道,mode 为数字,默认为 0666 (八进制) |
| 37 |
os.mknod(filename[, mode=0600, device]) |
| 38 |
打开一个文件,并且设置需要的打开选项,mode参数是可选的 |
| 39 |
打开一个新的伪终端对。返回 pty 和 tty的文件描述符。 |
| 40 |
返回相关文件的系统配置信息。 |
| 41 |
创建一个管道. 返回一对文件描述符(r, w) 分别为读和写 |
| 42 |
os.popen(command[, mode[, bufsize]]) 从一个 command 打开一个管道 |
| 43 |
从文件描述符 fd 中读取最多 n 个字节,返回包含读取字节的字符串,文件描述符 fd对应文件已达到结尾, 返回一个空字符串。 |
| 44 |
返回软链接所指向的文件 |
| 45 |
删除路径为path的文件。如果path 是一个文件夹,将抛出OSError; 查看下面的rmdir()删除一个 directory。 |
| 46 |
递归删除目录。 |
| 47 |
重命名文件或目录,从 src 到 dst |
| 48 |
递归地对目录进行更名,也可以对文件进行更名。 |
| 49 |
删除path指定的空目录,如果目录非空,则抛出一个OSError异常。 |
| 50 |
获取path指定的路径的信息,功能等同于C API中的stat()系统调用。 |
| 51 |
os.stat_float_times([newvalue]) |
| 52 |
获取指定路径的文件系统统计信息 |
| 53 |
创建一个软链接 |
| 54 |
返回与终端fd(一个由os.open()返回的打开的文件描述符)关联的进程组 |
| 55 |
设置与终端fd(一个由os.open()返回的打开的文件描述符)关联的进程组为pg。 |
| 56 |
os.tempnam([dir[, prefix]]) Python3 中已删除。返回唯一的路径名用于创建临时文件。 |
| 57 |
os.tmpfile() Python3 中已删除。返回一个打开的模式为(w+b)的文件对象 .这文件对象没有文件夹入口,没有文件描述符,将会自动删除。 |
| 58 |
os.tmpnam() Python3 中已删除。为创建一个临时文件返回一个唯一的路径 |
| 59 |
返回一个字符串,它表示与文件描述符fd 关联的终端设备。如果fd 没有与终端设备关联,则引发一个异常。 |
| 60 |
删除文件路径 |
| 61 |
返回指定的path文件的访问和修改的时间。 |
| 62 |
os.walk(top[, topdown=True[, onerror=None[, followlinks=False]]]) 输出在文件夹中的文件名通过在树中游走,向上或者向下。 |
| 63 |
写入字符串到文件描述符 fd中. 返回实际写入的字符串长度 |
常用操作:
os.sep可以取代操作系统特定的路径分隔符。windows下为 “\\”
os.name字符串指示你正在使用的平台。比如对于Windows,它是'nt',而对于Linux/Unix用户,它是'posix'。
os.getcwd()函数得到当前工作目录,即当前Python脚本工作的目录路径。
os.getenv()获取一个环境变量,如果没有返回none
os.putenv(key, value)设置一个环境变量值
os.listdir(path)返回指定目录下的所有文件和目录名。
os.remove(path)函数用来删除一个文件。
os.system(command)函数用来运行shell命令。
os.linesep字符串给出当前平台使用的行终止符。例如,Windows使用'\r\n',Linux使用'\n'而Mac使用'\r'。
os.curdir:返回当前目录('.')
os.chdir(dirname):改变工作目录到dirname
========================================================================================
os.path常用方法:
os.path.isfile()和os.path.isdir()函数分别检验给出的路径是一个文件还是目录。
os.path.existe()函数用来检验给出的路径是否真地存在
os.path.getsize(name):获得文件大小,如果name是目录返回0L
os.path.abspath(name):获得绝对路径
os.path.normpath(path):规范path字符串形式
os.path.split(path) :将path分割成目录和文件名二元组返回。
os.path.splitext():分离文件名与扩展名
os.path.join(path,name):连接目录与文件名或目录;使用“\”连接
os.path.basename(path):返回文件名
os.path.dirname(path):返回文件路径
hashlib
import hashlib #导入模块
######## md5 ###########
m = hashlib.md5() #创建一个对象
m.update(b"hhf") #加密字符串 b代表byte,是把字符串转换成byte类型,也可以用bytes()强制转换
#m.update(bytes("hhf",encoding='utf-8')) #不指定encoding会报错,TypeError: Unicode-objects must be encoded before hashing
#bytes() 强制转换为字节类型
print(m.digest()) #取加密后字符串 转换成2进制格式hash
print(m.hexdigest()) #16进制格式hash,比较常用
###########-sha1 ########
hash = hashlib.sha1()
hash.update(b'admin')
print(hash.hexdigest())
# # ######## sha256 ########
hash = hashlib.sha256()
hash.update(b'admin')
print(hash.hexdigest())
# # ######## sha384 ########
hash = hashlib.sha384()
hash.update(b'admin')
print(hash.hexdigest())
# # ######## sha512 ########
hash = hashlib.sha512()
hash.update(b'admin')
print(hash.hexdigest())
#以上的加密方法都无法解密
例子
import hashlib
hash = hashlib.md5()#md5对象,md5不能反解,但是加密是固定的,就是关系是一一对应,所以有缺陷,可以被对撞出来
hash.update(bytes('admin',encoding='utf-8'))#要对哪个字符串进行加密,就放这里
print(hash.hexdigest())#拿到加密字符串
# hash2=hashlib.sha384()#不同算法,hashlib很多加密算法
# hash2.update(bytes('admin',encoding='utf-8'))
# print(hash.hexdigest())
hash3 = hashlib.md5(bytes('abd',encoding='utf-8'))
''' 如果没有参数,所以md5遵守一个规则,生成同一个对应关系,如果加了参数,
就是在原先加密的基础上再加密一层,这样的话参数只有自己知道,防止被撞库,
因为别人永远拿不到这个参数
'''
hash3.update(bytes('admin',encoding='utf-8'))
print(hash3.hexdigest())
#输出
96270535571b70a9c42cedda1851d57c
827a2329d20080baa7f53bdfc7031425
这里写一个利用md5进行用户登陆网站进行注册之后密码加密的基本事例,加深理解
#hashlib简单使用
def md5(arg):#这是加密函数,将传进来的函数加密
md5_pwd = hashlib.md5(bytes('abd',encoding='utf-8'))
md5_pwd.update(bytes(arg,encoding='utf-8'))
return md5_pwd.hexdigest()#返回加密的数据
def log(user,pwd):#登陆时候时候的函数,由于md5不能反解,因此登陆的时候用正解
with open('db','r',encoding='utf-8') as f:
for line in f:
u,p=line.strip().split('|')
if u ==user and p == md5(pwd):#登陆的时候验证用户名以及加密的密码跟之前保存的是否一样
return True
def register(user,pwd):#注册的时候把用户名和加密的密码写进文件,保存起来
with open('db','a',encoding='utf-8') as f:
temp = user+'|'+md5(pwd)
f.write(temp)
i=input('1表示登陆,2表示注册:')
if i=='2':
user = input('用户名:')
pwd =input('密码:')
register(user,pwd)
elif i=='1':
user = user = input('用户名:')
pwd =input('密码:')
r=log(user,pwd)#验证用户名和密码
if r ==True:
print('登陆成功')
else:
print('登陆失败')
else:
print('账号不存在')
sys模块
模块的常见函数列表
-
sys.argv: 实现从程序外部向程序传递参数。 -
sys.exit([arg]): 程序中间的退出,arg=0为正常退出。 -
sys.getdefaultencoding(): 获取系统当前编码,一般默认为ascii。 -
sys.setdefaultencoding(): 设置系统默认编码,执行dir(sys)时不会看到这个方法,在解释器中执行不通过,可以先执行reload(sys),在执行 setdefaultencoding('utf8'),此时将系统默认编码设置为utf8。(见设置系统默认编码 ) -
sys.getfilesystemencoding(): 获取文件系统使用编码方式,Windows下返回'mbcs',mac下返回'utf-8'. -
sys.path: 获取指定模块搜索路径的字符串集合,可以将写好的模块放在得到的某个路径下,就可以在程序中import时正确找到。 -
sys.platform: 获取当前系统平台。 -
sys.stdin,sys.stdout,sys.stderr: stdin , stdout , 以及stderr 变量包含与标准I/O 流对应的流对象. 如果需要更好地控制输出,而print 不能满足你的要求, 它们就是你所需要的. 你也可以替换它们, 这时候你就可以重定向输出和输入到其它设备( device ), 或者以非标准的方式处理它们
sys.argv
功能:在外部向程序内部传递参数
示例:sys.py
#!/usr/bin/env python import sys print sys.argv[0] print sys.argv[1] 输出: # python sys.py argv1 sys.py argv1
sys.exit(n)
功能:执行到主程序末尾,解释器自动退出,但是如果需要中途退出程序,可以调用sys.exit函数,带有一个可选的整数参数返回给调用它的程序,表示你可以在主程序中捕获对sys.exit的调用。(0是正常退出,其他为异常)
示例:exit.py
#!/usr/bin/env python
import sys
def exitfunc(value):
print value
sys.exit(0)
print "hello"
try:
sys.exit(1)
except SystemExit,value:
exitfunc(value)
print "come?"
输出:
hello
1
sys.path
功能:获取指定模块搜索路径的字符串集合,可以将写好的模块放在得到的某个路径下,就可以在程序中import时正确找到。
>>> import sys
>>> sys.path
['', '/usr/lib/python2.7', '/usr/lib/python2.7/plat-x86_64-linux-gnu', '/usr/lib/python2.7/lib-tk', '/usr/lib/python2.7/lib-old', '/usr/lib/python2.7/lib-dynload', '/usr/local/lib/python2.7/dist-packages', '/usr/lib/python2.7/dist-packages', '/usr/lib/python2.7/dist-packages/PILcompat', '/usr/lib/python2.7/dist-packages/gtk-2.0', '/usr/lib/python2.7/dist-packages/ubuntu-sso-client']
sys.path.append("自定义模块路径")
shutil 模块
高级的 文件、文件夹、压缩包 处理模块
shutil.copyfileobj(fsrc, fdst[, length])
将文件内容拷贝到另一个文件中
import shutil
shutil.copyfileobj(open('old.xml','r'), open('new.xml', 'w'))
shutil.copyfile(src, dst)
拷贝文件
shutil.copyfile('f1.log', 'f2.log') #目标文件无需存在
shutil.copymode(src, dst)
仅拷贝权限。内容、组、用户均不变
shutil.copymode('f1.log', 'f2.log') #目标文件必须存在
shutil.copystat(src, dst)
仅拷贝状态的信息,包括:mode bits, atime, mtime, flags
shutil.copystat('f1.log', 'f2.log') #目标文件必须存在
shutil.copy(src, dst)
拷贝文件和权限
import shutil
shutil.copy('f1.log', 'f2.log')
shutil.copy2(src, dst)
拷贝文件和状态信息
import shutil
shutil.copy2('f1.log', 'f2.log')
shutil.ignore_patterns(*patterns)
shutil.copytree(src, dst, symlinks=False, ignore=None)
递归的去拷贝文件夹
import shutil
shutil.copytree('folder1', 'folder2', ignore=shutil.ignore_patterns('*.pyc', 'tmp*')) #目标目录不能存在,注意对folder2目录父级目录要有可写权限,ignore的意思是排除
shutil.rmtree(path[, ignore_errors[, onerror]])
递归的去删除文件
import shutil
shutil.rmtree('folder1')
shutil.move(src, dst)
递归的去移动文件,它类似mv命令,其实就是重命名。
import shutil
shutil.move('folder1', 'folder3')
shutil.make_archive(base_name, format,...)
创建压缩包并返回文件路径,例如:zip、tar
创建压缩包并返回文件路径,例如:zip、tar
- base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
如 data_bak =>保存至当前路径
如:/tmp/data_bak =>保存至/tmp/
- format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
- root_dir: 要压缩的文件夹路径(默认当前目录)
- owner: 用户,默认当前用户
- group: 组,默认当前组
- logger: 用于记录日志,通常是logging.Logger对象
#将 /data 下的文件打包放置当前程序目录
import shutil
ret = shutil.make_archive("data_bak", 'gztar', root_dir='/data')
#将 /data下的文件打包放置 /tmp/目录
import shutil
ret = shutil.make_archive("/tmp/data_bak", 'gztar', root_dir='/data')
shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的,详细:
zipfile压缩&解压缩
import zipfile
# 压缩
z = zipfile.ZipFile('laxi.zip', 'w')
z.write('a.log')
z.write('data.data')
z.close()
# 解压
z = zipfile.ZipFile('laxi.zip', 'r')
z.extractall(path='.')
z.close()
tarfile压缩&解压缩
import tarfile
# 压缩
>>> t=tarfile.open('/tmp/egon.tar','w')
>>> t.add('/test1/a.py',arcname='a.bak')
>>> t.add('/test1/b.py',arcname='b.bak')
>>> t.close()
# 解压
>>> t=tarfile.open('/tmp/egon.tar','r')
>>> t.extractall('/egon')
>>> t.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号