论文笔记SR——SFT
Recovering Realistic Texture in Image Super-resolution by
Deep Spatial Feature Transform
Abstract
在单图像超分辨(SR)的高质量重建上,虽然使用CNN会有很好的结果,但是如何恢复自然且逼真的纹理仍是一个挑战性问题。本文在基于语义分割概率图的单个网络中,通过空间特征变换(SFT)提取中间层特征,实现端到端的超分辨重建。
Introduction
单图像超分辨率旨在从单个低分辨率(LR)图像中恢复高分辨率(HR)图像。传统的SR方法一般是基于MSE,即基于像素空间纬度的MSE loss,这种方法会导致产生的图像模糊且过于平滑。SRGAN提出perceptual loss对特征空间纬度进行优化而不是像素纬度,进一步提出adversarial loss来生成更为自然的图片。使用perceptual loss和adversarial loss极大地改善了重建图像的感知质量。然而,生成的纹理趋于单调且不自然。
作者探讨了纹理不自然的一个重要原因是由于,对于不用HR片段其对应的LR片段可能会很相同,这就导致在上采样的时,模型很难区分当前图像的片断属于哪一个类别,从而导致合成的图像的纹理不真实。
本文使用语义分割图作为分类的先验信息来指导SR中不同区域的纹理恢复,使用空间特征变换(SFT)来转换网络的某些中间层的特征,改变SR网络的性能。SFT层以语义分割概率图为条件,生成一对调制参数,用来在空间上对网络的特征图应用仿射变换。
SFT层通过转换单个网络的中间特征,只需一次正向传递就可以实现具有丰富语义区域的HR图像的重建。同时,SFT层可以很容易地引入现有的SR网络结构,能够与SR网络一起进行端到端的训练。
Methodology
3.0定义假设
给定低分辨率图x,超分辨率估计结果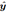 ,真实超分辨结果y,基于CNN的映射假设为
,真实超分辨结果y,基于CNN的映射假设为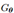 ,则有映射关系:
,则有映射关系:
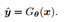
基于loss的参数设定:
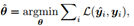
使用语义分割概率图来作为类别先验:
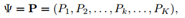
此时,基于先验的映射关系为:
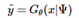
3.1 Spatial Feature Transform SFT层
① 参数对
空间特征变换(SFT)层学习"基于先验条件Ψ,输出调制参数对(γ,β)"的映射函数M.
即 ,M理论上来说应该是任意的方程,但是这里还是指采用卷积神经网络来做这个映射关系,同时SFT得到参数对的过程是条件共享的
,M理论上来说应该是任意的方程,但是这里还是指采用卷积神经网络来做这个映射关系,同时SFT得到参数对的过程是条件共享的
参数对(γ,β)通过在空间上对SR网络中的每个中间特征图应用仿射变换来自适应地影响输出,即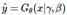
② SFT层的结构
SFT layer就是一个小型的network用于生成不同层的condition信息,变换方式:
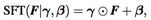
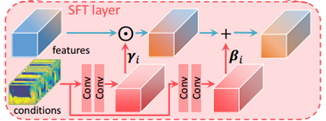
SFT有两个输入,一个输入是condition network的输出conditions,另一个是上一层的输出F。conditions分别通过两层卷积计算得到γ和β,然后参数对与上层F进行变换,计算整个SFT层的输出,而整个SFT层的输出又作为下一层的输入F。
③ SFT的实现
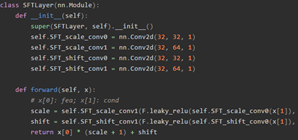
两层卷积之后直接与F做点乘、加法。
3.2 网络结构
① 网络结构

主体分为三个部分,条件网络condition network、SR网络和上采样部分
a)条件网络将分割概率图作为输入,使用四层卷积处理,它生成所有SFT层共享的中间条件。这里为了避免一个图像中不同分类区域的相互干扰,通过对所有卷积层使用1×1个核来限制条件网络的感受域。
b) SR网络由16个残差块构成,每个残差块包含两个SFT+Conv,所有SFT共享conditions,SFT以共享conditions作为输入并学习(γ,β)以通过应用仿射变换来调制特征图。
c)上采样部分使用最近邻上采样+卷积层进行上采样操作
最近邻插值:在待求像素的四邻象素中,将距离待求像素最近的邻像素灰度赋给待求像素,最邻近元法计算量较小,但可能会造成插值生成的图像灰度上的不连续,在灰度变化的地方可能出现明显的锯齿状。
3.3 Loss Function
感知损失perceptual loss
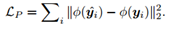
其中使用预训练的VGG-19特征
对抗损失 adversarial loss
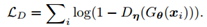
传统的GAN loss,使D对G的判定尽可能的准确
Experiments
①限定七个类别,不属于7类别的则为背景。在训练时,将图像裁剪到只包含一个类别来训练D的识别能力。
②训练时使用包含单个类别的图像进行训练,测试时使用包含多个类别的图像进行测试。
PS:训练时单个类别损失,测试时多个类别,网络是否有效?
——作者在test阶段,输入LR图片和k张分割概率图,每一张概率图中都显示着某一特定物体在该位置存在的概率,输入数据兵分两路进入G,得到输出的SR图像。已经训练好的G+分割概率图,G网络便获得了根据概率图针对性重建图像的能力(根据概率图,将多类别问题转化为单类别问题)
——训练时不是整张图片的训练,而是将原图裁剪到98*98大小进行训练,保证只包含一个分类。但由于使用的是概率图,虽然每次是单个类别,但是整体数据包含了所有的类别,也就保证了结果的鲁棒性。
③D部分,除了包含常规GAN的real/fake分支损失,还包含了一项类别损失,使D能够对不同的类别进行识别,具体是使用多类交叉熵CrossEntropyLoss来对类别进行限制。
summary
① 使用perceptual loss和adversarial loss极大地改善了重建图像的感知质量。然而,早缺少先验信息的情况下,生成的纹理趋于单调且不自然。
② 使用语义分割概率图作为条件先验。传统SR算法着重与PSNR,基于MSE的损失使得图像模糊;SRGAN引入perceptual loss,通过VGG网络提取深层特征进行训练,但纹理信息缺少,因为笼统的提取特征,在遇到不同事物具有相似纹理时往往导致误判,也就是说D网络不尽责,区分墙壁与野草的能力差,使得效率低的G网络轻松通过鉴别,;SFT使用seg map来进行引导,一方面明确告诉G物体的类别,(seg提供信息,SFT处理信息)另一方面告诉D如何识别物体的类别
③ SFT对每个分类寻找通用的增强信息。由于seg map是概率图,所以除了包含spatial信息之外,还会包含一定的纹理细节信息 这些信息会对sft有一定的影响。sft实际上就是针对每个不同的分类对LR feature加入特定的纹理细节,即(β,γ)的作用。整体的过程就是在保留LR的空间信息的情况下,加入基于分类的纹理细节。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号