
win7下idea远程连接hadoop,运行wordCount
1.将hadoop-2.6.1.tar.gz解压到本地
配置环境变量
HADOOP_HOME
E:\kaifa\hadoop-2.6.1\hadoop-2.6.1
HADOOP_BIN_PATH
%HADOOP_HOME%\bin
HADOOP_PREFIX
%HADOOP_HOME%
配置path
E:\kaifa\jdk1.7.0_21\bin;%HADOOP_HOME%\bin;%HADOOP_HOME%\sbin;
2.用idea新建一个maven项目
导入hadoop依赖包
File>Project Structure>Project Settings>Libraries,点+号然后选择Java,然后选择解压出来的hadoop-2.6.1文件夹下share\hadoop\下的jar包
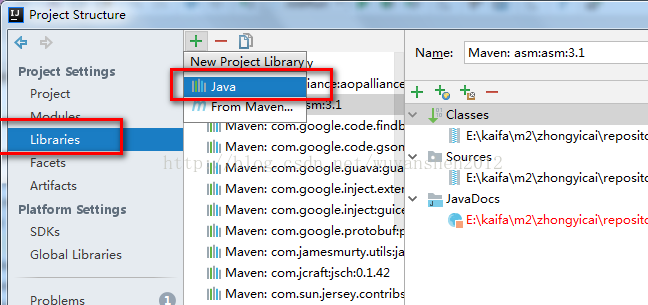
pom.xml配置
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.hadoop261</groupId> <artifactId>myhadoop</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.6.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-jobclient</artifactId> <version>2.6.1</version> </dependency> <dependency> <groupId>commons-cli</groupId> <artifactId>commons-cli</artifactId> <version>1.2</version> </dependency> </dependencies> <build> <finalName>${project.artifactId}</finalName> </build>
WcMapper.java
package hadoop.test; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; import java.util.StringTokenizer; public class WcMapper extends Mapper<LongWritable,Text,Text,IntWritable>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // IntWritable one=new IntWritable(1); String line=value.toString(); StringTokenizer st=new StringTokenizer(line); //StringTokenizer "kongge" while (st.hasMoreTokens()){ String word= st.nextToken(); context.write(new Text(word),new IntWritable(1)); //output } } }
McReducer.java
package hadoop.test; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * Created by iespark on 2/26/16. */ public class McReducer extends Reducer<Text,IntWritable,Text,IntWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> iterable, Context context) throws IOException, InterruptedException { int sum=0; for (IntWritable i:iterable){ sum=sum+i.get(); } context.write(key,new IntWritable(sum)); } }
JobRun.java
package hadoop.test; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * Created by iespark on 2/26/16. */ public class JobRun { public static void main(String[] args){ Configuration conf=new Configuration(); try{ Job job = Job.getInstance(conf, "word count"); onfiguration conf, String jobName job.setJarByClass(JobRun.class); job.setMapperClass(WcMapper.class); job.setReducerClass(McReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //解决No job jar file set. User classes may not be found. See Job or Job#setJar(String)报错的问题 job.setJar("E:\\idea2017workspace\\myhadoop\\out\\artifacts\\myhadoop_jar\\myhadoop.jar"); FileInputFormat.addInputPath(job,new Path(args[0])); FileSystem fs= FileSystem.get(conf); Path op1=new Path(args[1]); if(fs.exists(op1)){ fs.delete(op1, true); System.out.println("存在此输出路径,已删除!!!"); } FileOutputFormat.setOutputPath(job,op1); System.exit(job.waitForCompletion(true)?0:1); }catch (Exception e){ e.printStackTrace(); } } }
3.设置jar包的生成位置
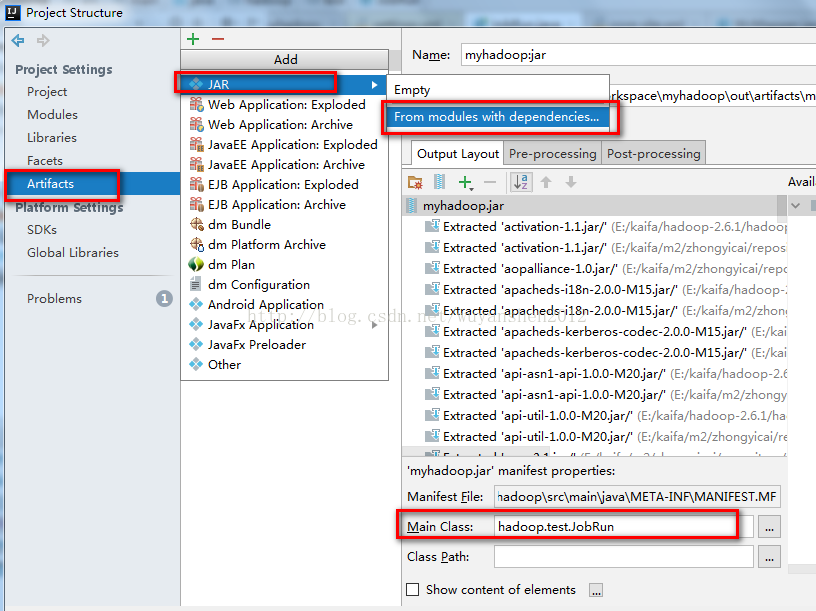
注意最下面的Main Class别忘记选择
然后把这个路径放在JobRun.jar中的
job.setJar("E:\\idea2017workspace\\myhadoop\\out\\artifacts\\myhadoop_jar\\myhadoop.jar");
3.在sources文件夹中新增core-site.xml和log4j.properties文件
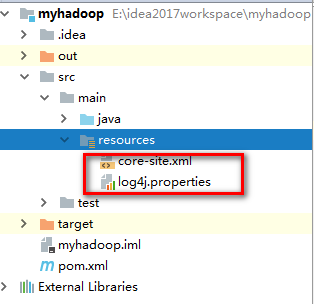
core-site.xml 配置内容和你的hadoop集群的配置一样
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <!--配置namenode的地址--> <property> <name>fs.defaultFS</name> <value>hdfs://10.102.19.229:9000</value> </property> <!-- 指定hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>file:///data/hadoop/data/tmp</value> </property> </configuration>
log4j.properties文件可以将hadoop-2.6.1下的hadoop-2.6.1\etc\hadoop中的log4j.properties复制过来,不用修改!
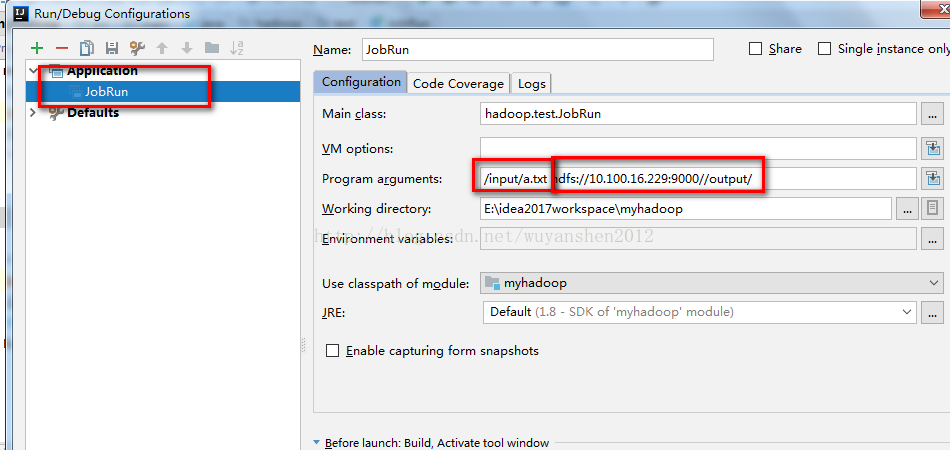
4.配置运行参数
我们可以直接在JobRun.java右键运行,但是还少两个参数,一个是输入路径,一个是输出路径,下面Program arguments中的第一个是输入路径,第二个是输出路径。
注意:1.这两个路径中间要用空格隔开!
2.这两个路径都是你hadoop上hdfs文件系统中的路径,不是你win7本地的路径!
3.输入路径的a.txt是你要处理的文件,需要自己新建:hadoop fs -mkdir /input hadoop fs -put ./a.txt /input
我的a.txt的内容是:
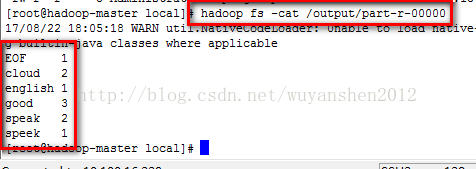
speak good cloud speek good good cloud speak english
EOF
运行结果就是统计每个单词出现了几次
5.运行
看到下面的输出,我们就成功远程到了linux上的hadoop并执行了wordCount程序!

我们到linux控制台查看运行结果:
可以看到有了output文件夹(input是我们自己建的)
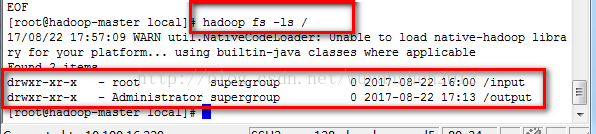
我们可以用
hadoop fs -ls /output
继续查看,看到有两个文件,part-r-00000就是运行的结果!

我们用
hadoop fs -cat /output/part-r-00000
查看执行结果
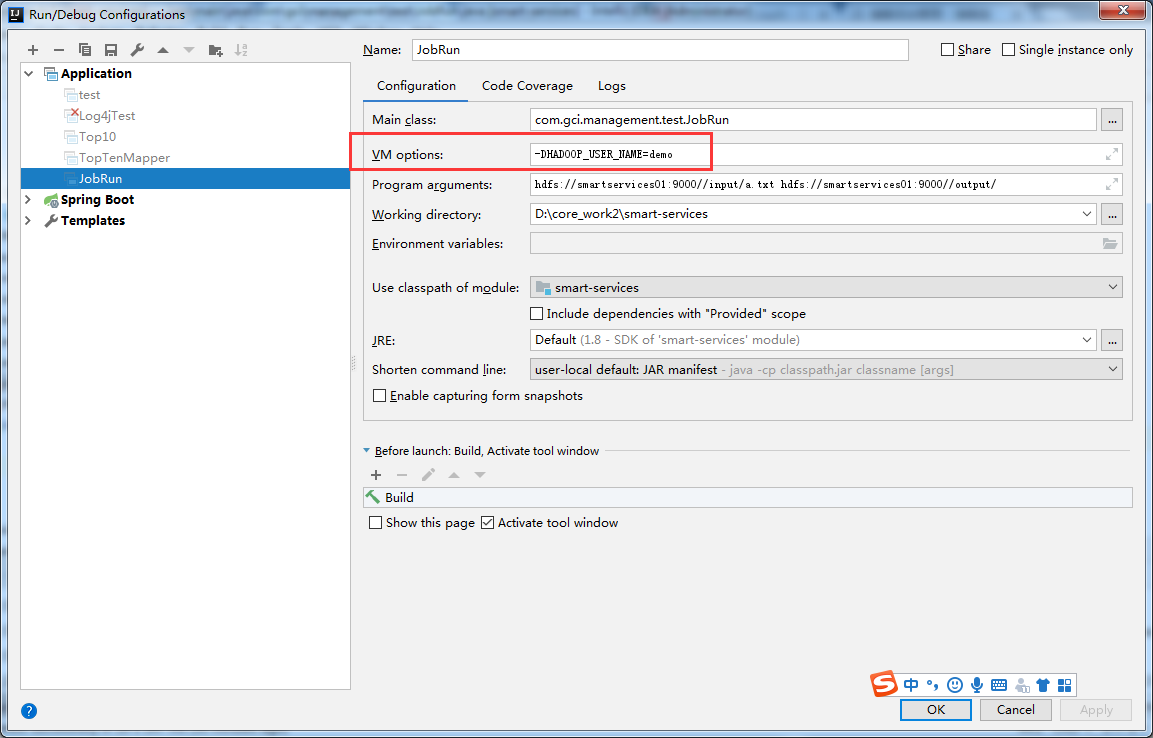
温馨提醒:为了以防空指针等一些莫名其妙的的错误在此处需要把你的hadoop的配置文件里面的core-site.xml、hdfs-site.xml和log4j.properties复制过来放在你的 src目录下。然后在开始运行你的程序了。在此处我们准备做测试的文件放在集群根目录下的data下。所需需要在你的hdfs文件系统的根目录创建data文件夹,并上传你要的测试文件。
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=Administrator, access=WRITE, inode="/":root:supergroup:drwxr-xr报错
至此,我们成功在win7下远程调用linux的hadoop-2.6.1运行了wordCount程序!
---------------------
作者:龙丿一
来源:CSDN
原文:https://blog.csdn.net/wuyanshen2012/article/details/77482892
版权声明:本文为博主原创文章,转载请附上博文链接!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号