
[NLP]对话系统简介
对话系统包含两个部分:对话和系统。
对话是指为达到特定目的活动。
对话特点:连续性和跳跃性。连续性是指针对一个主题进行有来有往的交谈,跳跃性是指在谈论一个具体的话题时,突然插入另一个主题,比如说我们正在谈论某个电影,突然插入一个话题,某某路出车祸了,这种从一个话题跳到另一个话题,即对话的跳跃性。
对话系统:是指具备同人类进行连贯交互的计算机系统。
这里,重点关注“连贯交互”四个字,这说明目前工业界还不能开发出一套可以进行跳跃性交互的对话系统,即开放领域的对话系统。虽然GPT3可以达到一定程度的开放域对话,但是还是有一定的局限性。
二、常见应用场景
1、语音助手:可以解放人的双手,如siri,各种订票、订餐等语音助手。
2、智能客服:主要解决人工客服成本过高的问题。
3、智能音箱:如天猫精灵,小米小爱,百度小度等。
三、系统架构
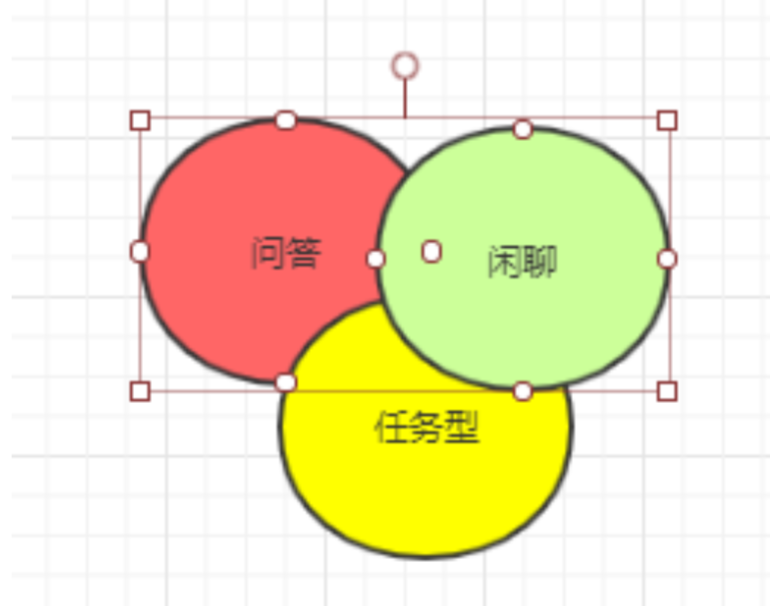
1、对话系统分类:主要分为闲聊型、问答型、任务型三类。
闲聊型对话机器人:理想状态是开放域闲聊对话机器人,但由于目前技术达不到,因此现在的闲聊型对话机器人都是一定领域的闲聊型对话机器人。
问答型对话机器人:具体形式是一问一答型,没有上下文语义继承关系,针对问题进行回答。如咨询客服:信用卡还款日期,这是一个具体问题,直接回答即可。
任务型对话机器人:多轮对话形式,有上下文语义关联信息,需要上一轮的信息决定下一轮对话的状态或者行为。
三者区分不明显,一般是你中有我我中有你的态势,如下图所示:
举个例子:
A:今天天气真好 B:是的,温度适宜呢 ——>闲聊型
A:体感温度多少啊? B:37度 ——>问答型
A:才37度,怎么这么热啊 B:可是我不觉得热呢? ——>任务型
三、对话系统架构
以客服为例:
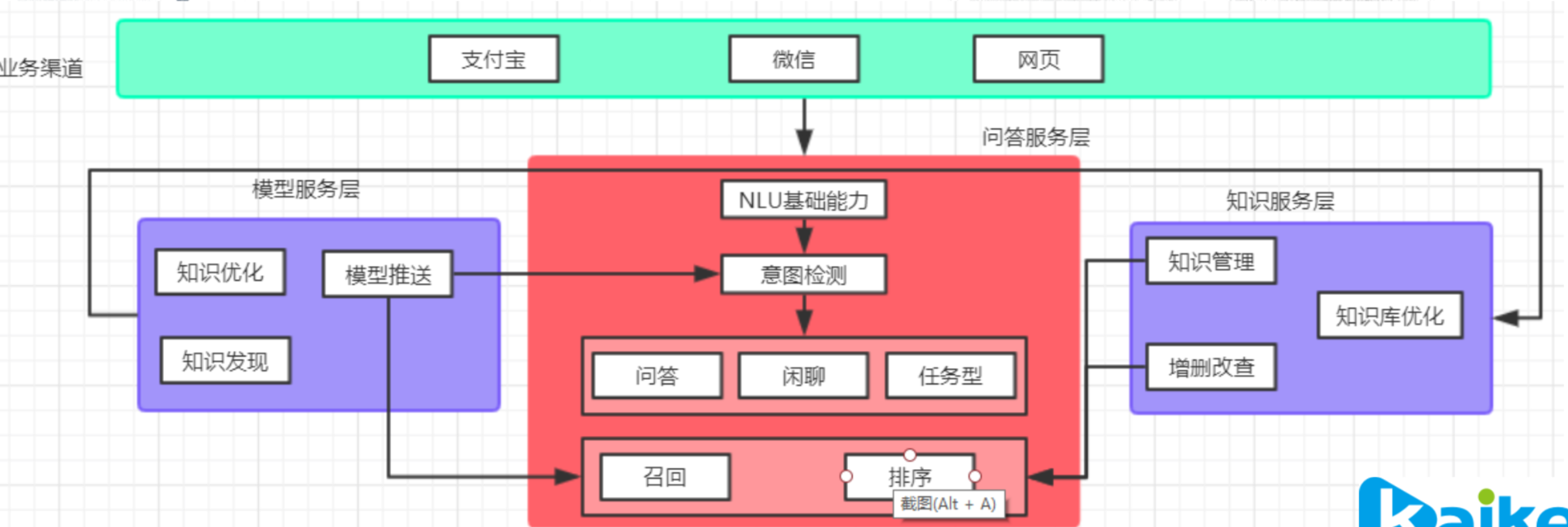
这里忽略输入过程的语音识别,以及输出过程的语音合成,假设输入输出都是文本,下面我具体讲解一下客服对话系统的架构。
该过程包含三个部分:模型服务层,知识服务层,问答服务层。
注1:召回:倒排(速度慢);跳表(速度快,占内存);向量搜索(faiss,annoy)
注2:排序:gbrt(并行,速度快)
注3:NLU基础:对query进行分析后,与知识库中相关性的计算(速度瓶颈),可以使用bm25方法进行计算,但是计算结果会影响意图分类,因此如果意图分类的准确率比较高,下一步则可以按照意图选择一个对话机器人进行后续步骤;否则,如果意图分类的准确率比较低,也可以让一个query同时经过闲聊、任务、问答三个机器人,然后对三个结果进行召回和排序后,选择得分最高的一项输出。
2、模型服务层主要是管理模型部分,具体内容如下图所示:
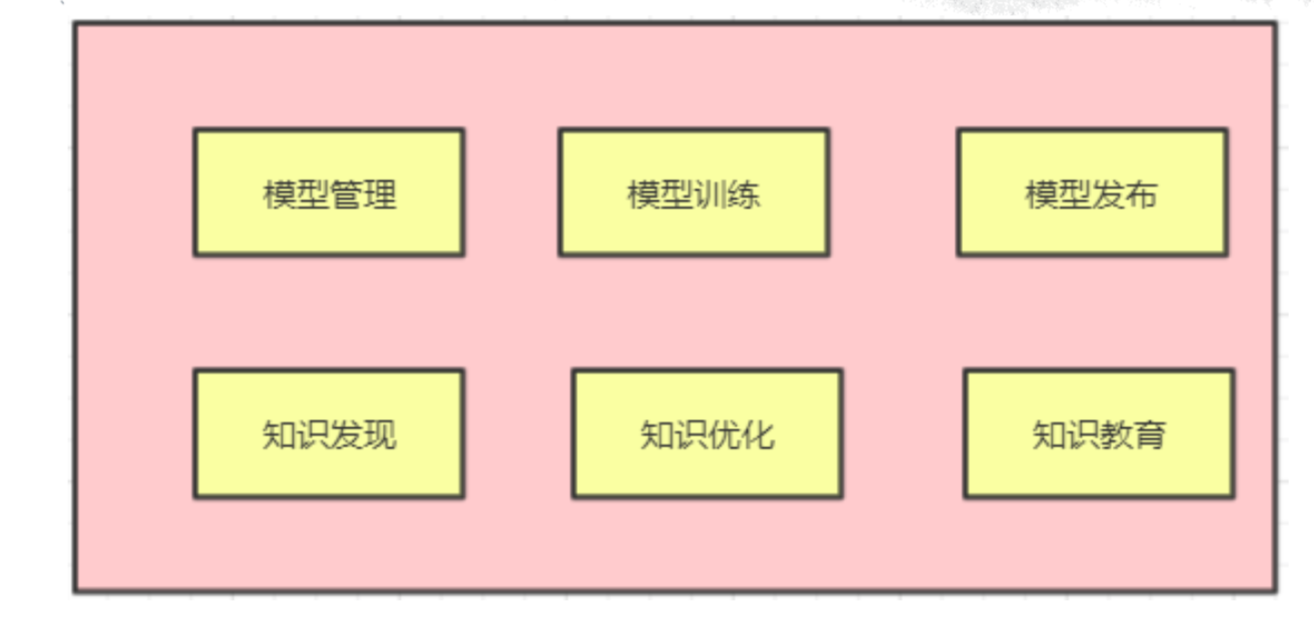
(1)模型管理是管理所有的模型,模型训练及模型发布就是字面意思,这里主要讲一下知识发现、知识优化、知识教育等三个方面:
(2)知识发现是指在 模型预测过程中,模型发现的新知识以及从query中发现的新知识;
(3)发现知识后,需要进行知识优化;
(4)知识教育的模块则比较复杂,是指人工标注数据更新/前端知识管理后,要在知识教育模块里出发模型训练,以形成模型的闭环。
3、知识服务层:是管理各种知识的,包括三类对话机器人的知识库等,具体内容如下图所示:
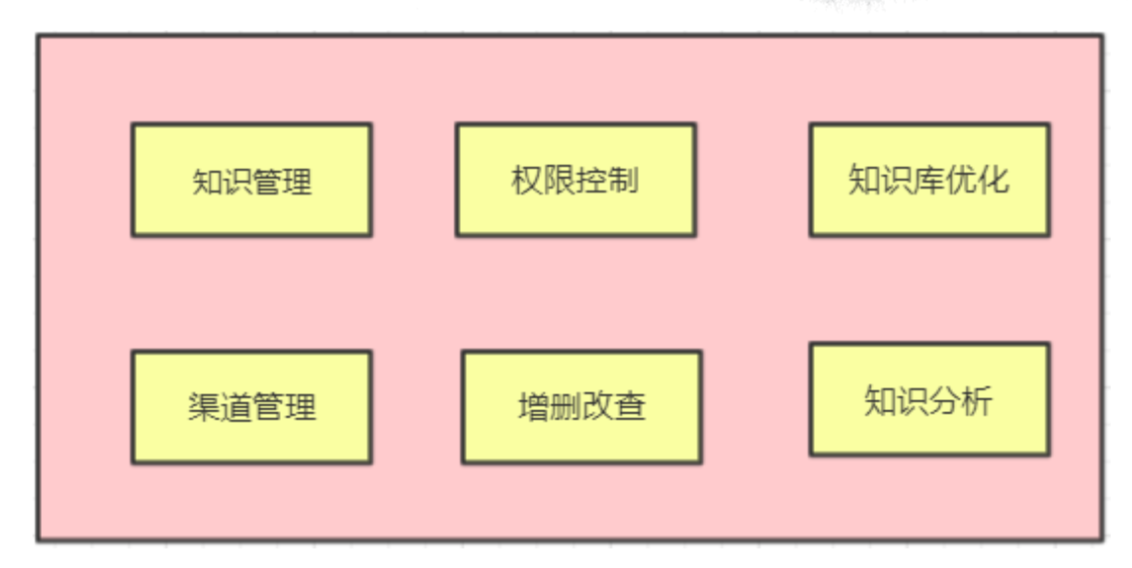
其中知识管理即进行各类知识的管理;
权限控制:进行知识管理是一个比较重要的部分,也需要比较多的运维人员来做,但是不同运维人员的权限不同,管理的知识库也不同,因此需要设置知识库的权限控制。
知识优化:是指对知识库进行优化,包括业务上的回答/问题,多轮场景中的入口问题、寒暄、闲聊的文法等等内容。
知识分析:就是分析各类知识的合理性,知识分析后就会对知识进行优化。
增删改查:是指对各类知识的增删改查处理
渠道管理:主要是管理知识的来源。
以上是客服对话系统的各部分细节,本篇先讲到这里。下一篇会继续讲解对话机器人。
