

[NLP]jieba分词理解
一、jieba分词特点:支持3种分词模式;支持繁体分词;支持自定义词典。
二、jieba分词的过程:
1、基于前缀词典实现词图扫描,生成句子中所有可能的词语构成有向无环图(DAG),采用动态规划方法寻找最大概率的路径,即基于词频的最大切分组合;
-
jieba分词中有个词典dict.txt,其中包含2万多条词语,根据这个词典生成trie树。
①trie树是前缀树,是一种多叉树,根结点为空,具有相同前缀的字符串在一条分叉上,但是每一个到叶结点的分叉都是唯一的——没有冲突,它具有查找速度快的优势,但它是一种以空间换时间的算法。
②dict.txt中除了词语外,还有词语出现的次数(即词频)和词性,是作者基于人民日报语料等资源训练出来的。
-
根据输入的待分词的句子,根据dict.txt生成的trie树,生成DAG,即将句子中所有可能的切分都查询出来,构成DAG。
-
根据动态规划查找最大概率路径的方法,对句子从右往左反向计算最大概率。
具体过程如下:
①P(N) = 1.0
②P(N-1)=P(N) * max(P(倒数第一个词))
③以此类推,最后得到最大概率路径,得到最大概率的切分组合。
2、对于未登录词,采用了HMM模型,并用维特比算法进行计算
-
采用HMM模型将中文词汇按照BEMS四个状态来标记(分别表示begin,end,middle,single单独成词的位置)
-
作者利用大量语料来进行训练,得到了三个概率表。分别是:
①位置转换概率:即BEMS四种状态的转移概率,如P(E|B) = 0.851, P(M|B) = 0.149,说明当我们处于一个词的开头时,下一个字是结尾的概率要远高于下一个字是中间字的概率,符合我们的直觉,因为二个字的词比多个字的词更常见。
②位置到单字的发射概率:如P(和|M)表示一个词的中间出现“和”这个字的概率
③词语以某种状态开头的概率:其实只有两种,B和S。这是起始向量,就是HMM系统的最初模型状态。具体的说,给定一个待分词的句子,即观察序列,对HMM(BEMS)四种状态的模型来说,就是为了找到一个最佳的BEMS序列,这里使用维特比算法来得到这个最佳的隐藏状态序列。举个例子:全世界都在学中国话,得到一个BEMS序列[S,B,E,S,S,S,B,E,S],将连续的BE凑到一起得到一个词,最终会得到一个分词结果。
3、基于维特比算法的词性标注
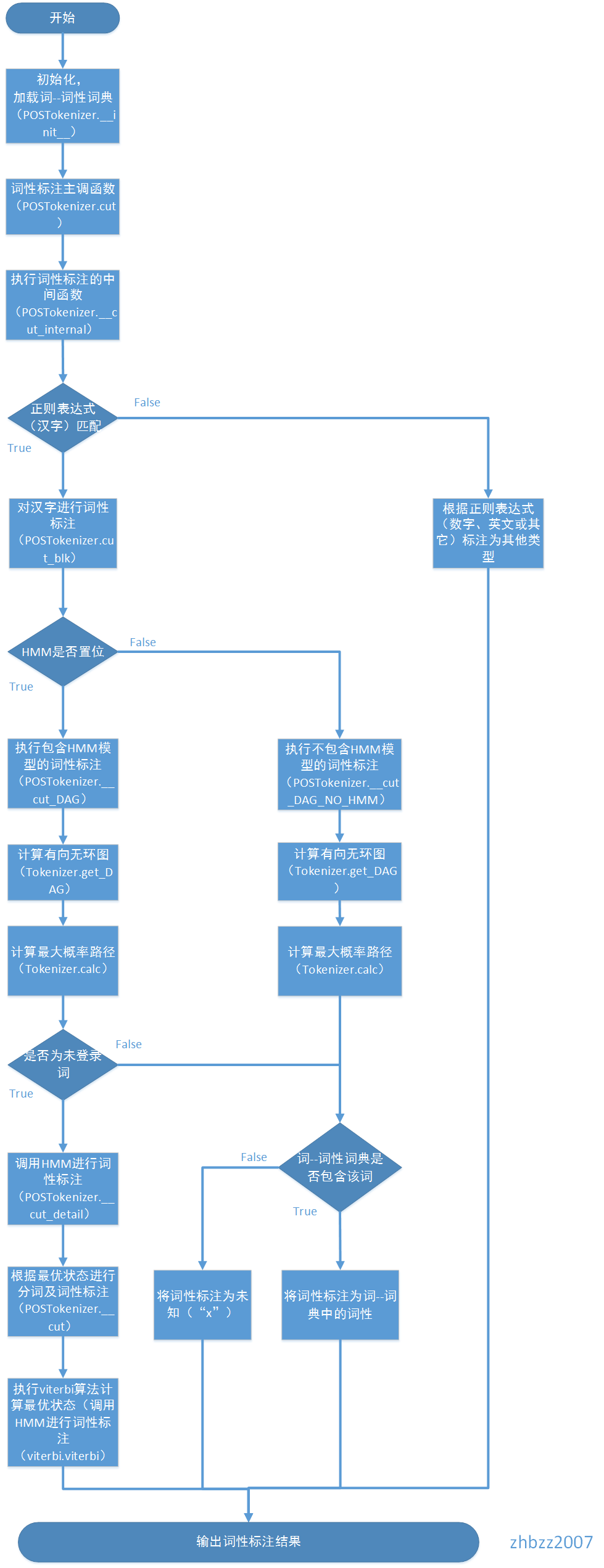
同2类似,转换成序列标注问题。jieba在分词的时候,同时进行分词和词性标注。词性标注时,则首先基于正则表达式(汉字)进行判断,如果是汉字:则基于前缀词典构建DAG,然后计算最大概率路径,同时查找所分出的词的词性,如果没有找到,则将其词性标注为x;如果是HMM标志位置位,并且该词为未登录词,则通过HMM对其进行词性标注;如果是其他,则根据正则表达式判断其类型,标注为x,m(数词),eng(英文)等。
4、分别基于ti-idf和textrank模型抽取关键词;
jieba分词的流程图如下:
三、jieba分词的不足:
1、dict.txt字典占用内存为140多M,占用内存过多。且该词典是通用词典,通用词的分割有效果,但是对于专业领域的分词则效果不好,需要自备专业领域词典进行分词。
2、HMM识别新词在时效性是不足的,并且只能识别2个字的词,对于3个字的词,识别能力有限,
3、ner效果不够好。
4、不能进行句法分析和语义分析。
参考资料:
[1]https://blog.csdn.net/miner_zhu/article/details/83246153
[2] https://www.cnblogs.com/zhbzz2007/p/6076246.html?utm_source=itdadao&utm_medium=referral%C2%A0
[3]
