
[NLP]embedding——one-hot,word2vec,fasttext,Glove,sentence embedding
即one-hot编码,nlp中,假设我们有一个词典,包含所有需要的词语,共V个,如果想将文字符号转换成向量表示,one-hot就是一种当前词是1其他词是0的表示方法,其维度是V*1维。举例如下:假设我们祥表示“鼠标”这个词,该词在词典中处于第一个位置,则“鼠标”的one-hot编码为:[1,0,0,...,0],且这个向量是Vx1维。
优点:一是将文字符号转换成数字向量表示,二是一定程度上起到了特征扩充的作用
缺点:①得到的特征是离散稀疏的 ②假设词与词相互独立
③它是一个词袋模型,不考虑词与词之间的顺序
One-hot是高维向量,使用它会增加大量的计算量,我们知道深度学习是极度吃资源的,所以降低计算量是极好的一个省钱省资源手段。而对one-hot降维的方法是使用Distributed representation,它的思路是通过训练,将每个词映射到一个较短的词向量上。所有的这些词向量就构成了向量空间,进而可以用普通的统计学的方法来研究词与词之间的关系。具体的向量维度需要我们再训练时自己指定。
例如向量维度可以设置为4个:"Royalty","Masculinity","Femininity","Age",则"king"这个词对应的词向量可能为(0.99,0.99,0.05,0.7),当然在实际情况中,我们并不能对词向量的每个维度做一个很好地解释。但是使用该方法,讲一个Vx1维的向量转成了一个4x1维的向量。
我们将"king"这个词从一个非常稀疏的向量所在的空间,映射到这个四维向量所在的空间,必须满足一下性质:
-
这个映射是单设
-
映射之后的向量不会丢失之前的那种向量所含的信息。
这个过程称为word embedding(词嵌入),即将高维词向量嵌入到一个低维空间。
word2vec
Word2vec是词嵌入的一种,但是它是使用简单的神经网络计算词向量。它只有三层,输入层、隐藏层和输出层。
-
输入层:输入是one-hot向量,
-
隐藏层:没有激活函数,只是线性单元
-
输出层:维度跟输入层一致,用softmax回归。
word2vec常用的两种模型是CBOW(Continuous Bag-of-Words)和Skip-Gram模型。
-
Skip-gram模型:用一个词语做输入,来预测该词周围的上下文
-
skip-gram对于出现频率比较低的词汇,embedding的效果要优于cbow(因为skip-gram中频率比较低的词汇计算次数更多一些)。
Skip-Gram

上图是skip-gram的网络结构。其中输入向量X是one-hot编码形式的输入(V维是因为词典中共有V个单词),是经过隐藏层计算后在这V个词上输出的概率。我们使用反向传播算法训练这个神经网络,本质上是链式求导。
skip-gram的具体步骤如下:输入向量x_k,维度为1 * V,先后乘以词向量矩阵W_{V*N}和W'_{N*V},计算得出各个词汇的得分score矩阵,维度为C * V, 再经过softmax计算,即可得出各个词的概率分布。
优化方法:
①使用层次softmax方法:如果词汇量是10万的话,计算softmax值的话,计算量会很大,因此提出了一个优化算法,就是得出score矩阵后,先使用哈夫曼树重新计算各个单词位置及其权重,然后再使用层次softmax进行计算各个词的概率,此时计算复杂度变为O(log n),比原始方法的复杂度O(n)要小很多。
②负采样:对于输出层输出的得分来说,我们ground truth对应的单词的概率最大,因此可以将其看做是正样本,其余的所有|V|-1个单词看做是负样本,对于正负样本极度不平衡的情况来说,我们可以采用负采样的方法来减少计算量。
注1:哈夫曼树,是一种二叉树结构,具体的计算过程是:score矩阵大小是C * V,取每一行即一个词汇的score矩阵(维度为1 * V)作为一个向量,向量中每一列的索引对应着词典中的一个单词,向量中每一列的值对应着该词的得分,根据这两个值,按照得分升序排列,可得到一个备选词汇库(该词汇库大小是词典的大小,即V),每一次都将分值最小的两个词语组合成二叉树的两个叶子,此时从备选词汇中删除这两个词语,保留新形成的这棵二叉树(二叉树的分值是根结点的左右节点的分值之和)作为一个新的词汇表放进备选词汇库中,直到最终形成一棵二叉树。
这棵二叉树依然是各个单词的得分,还没有经过softmax计算其概率分布,具体的看注2.
哈夫曼树的计算形式如下图所示:
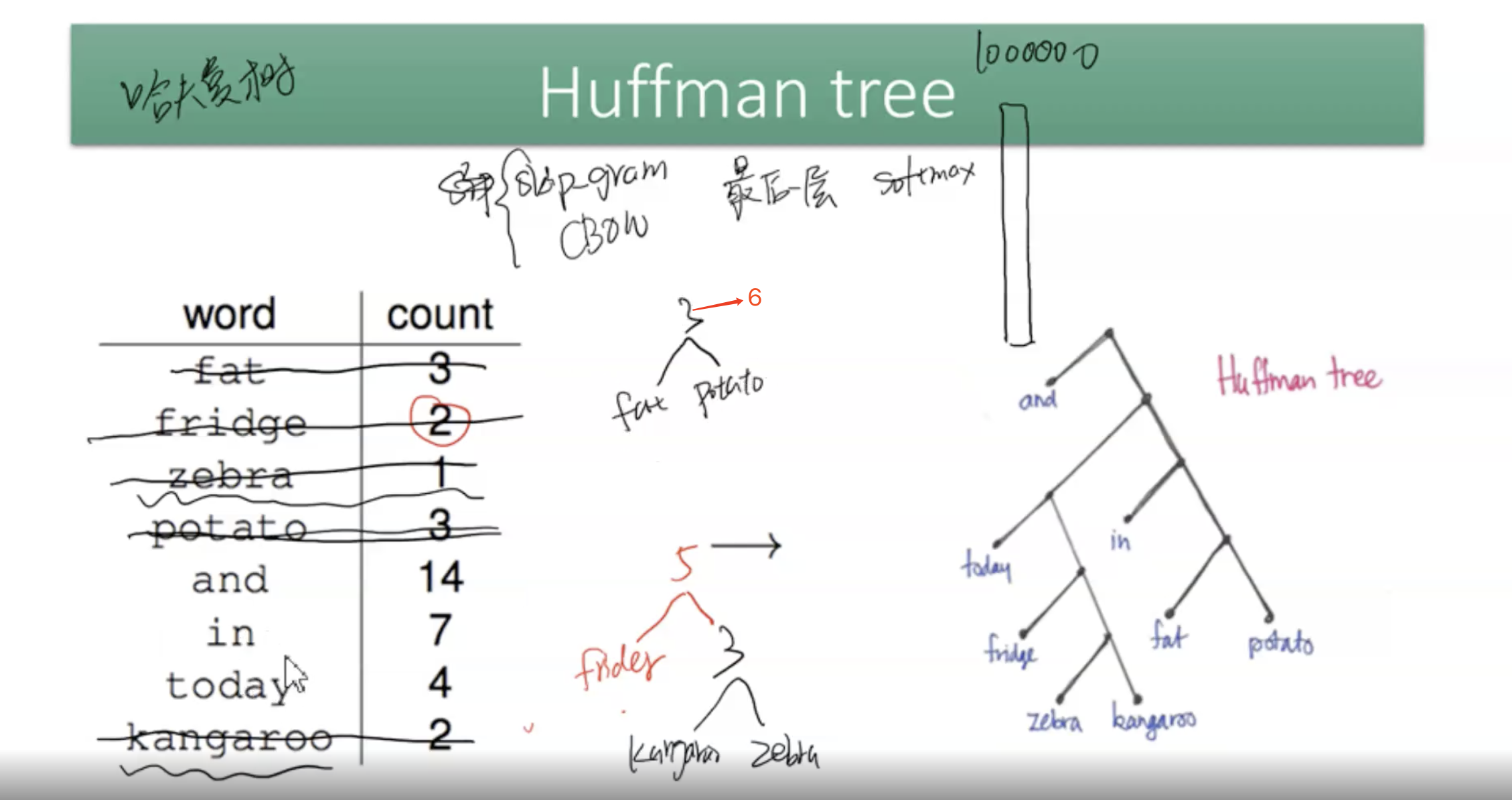
注2:hierarchical softmax(层次softmax),我们利用哈夫曼树重新排列了各个单词的得分后,依然需要使用softmax来计算各个词汇的概率分布,但是对于树结构,我们采用层次softmax来计算,

注3:通过使用哈夫曼树和层次softmax的方法优化还是有点复杂(因为要建一棵树),因此提出了负采样方法,该方法的主要思想是:由于ground_truth告诉了我们应该取哪一个词语(该词汇是可以看做是正样本),那么词汇表中的其他|V-1|个词汇对我们来说都可以是负样本,我们选取k个负样本进行计算即可(选取方法:选择频率较高的k个词作为负样本),其目标函数变为正样本的log再加上负样本的log(负值)的和。
具体内容看下图:

举个例子:I like run with my sister every morning.
这里需注意有两个参数skip_window和num_skips参数,skip_window是输入语句中词汇窗口的大小,假设设置skip_window=2,则取input word左侧和右侧各2个词汇(包括input word),设input word='run',则窗口中的词={like,run,with,my};num_skpis代表着我们从整个窗口中选取多少个不同的词作为output word,假设num_skips=2,则我们会得到两组训练数据:(run,like),(run,with),最终输出的2xV维向量中,每个元素代表一个词的概率大小 ,在训练阶段,有可能输出的2个词不是like和with,没关系,我们会计算输出的两个词汇与训练数据中正确的输出词汇的距离然后更新权重矩阵,最终保存训练完成的权重矩阵。
CBOW
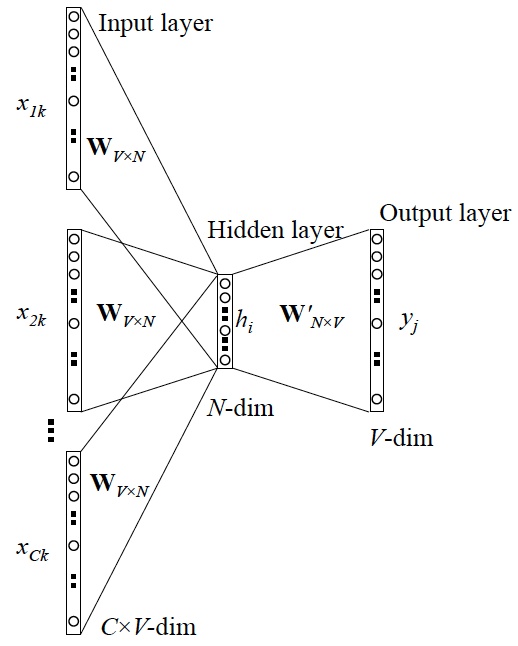
上图是CBOW的网络结构,输入是上下文的one-hot向量,输出是某一个该上下文对应的词汇。
具体步骤如下:
①输入层:上下文单词的one-hot. {假设单词向量空间dim为V,上下文单词个数为C}
② 所有one-hot分别乘以共享的输入权重矩阵W. {VxN矩阵,N为自己设定的数,初始化权重矩阵W}
③ 将隐藏层计算所得的向量相加求平均作为隐层向量, size为1xN.
④ 乘以输出权重矩阵
⑤得到向量 (维度为1xV)
⑥概率最大的index所指示的单词为预测出的中间词(target word),与true label的one-hot做比较,误差越小越好(根据误差更新权重矩阵)
这里,使用的loss function(一般为交叉熵代价函数),采用梯度下降算法更新W和W'。训练完毕后,我们会保存隐藏层的权重矩阵W,当我们需要计算一个词的词向量时,只要将该词的上下文one-hot向量与权重矩阵W相乘即可得到该词的词向量。
以上,是简单的word2vec介绍,想要了解的更透彻,可以看参考资料[3]中的博客,博客里更多涉及了预备知识以及相关公式,讲解的更加详细。
注1:参考资料[4]是对于词向量的总结,可以看看。
注2:word2vec与bert的主要区别:①从静态到动态:一词多义问题②简单到丰富:词的多层特性
注3:负采样通过考虑相互独⽴的事件来构造损失函数,这些事件同时涉及正例和负例。训练的计算量与每⼀步的噪声词数成线性关系。
分层softmax使⽤⼆叉树中从根节点到叶节点的路径构造损失函数。训练的计算成本取决于词表⼤小的对数。
fasttext
fasttext的网络结构同word2vec一致(但是它要比skip-gram慢1.5倍),但是它与word2vec的区别是它的输入是对已分好词的词汇做n-gram操作,然后将n-gram作为一个样本输入到模型中,如下图所示。

GloVe
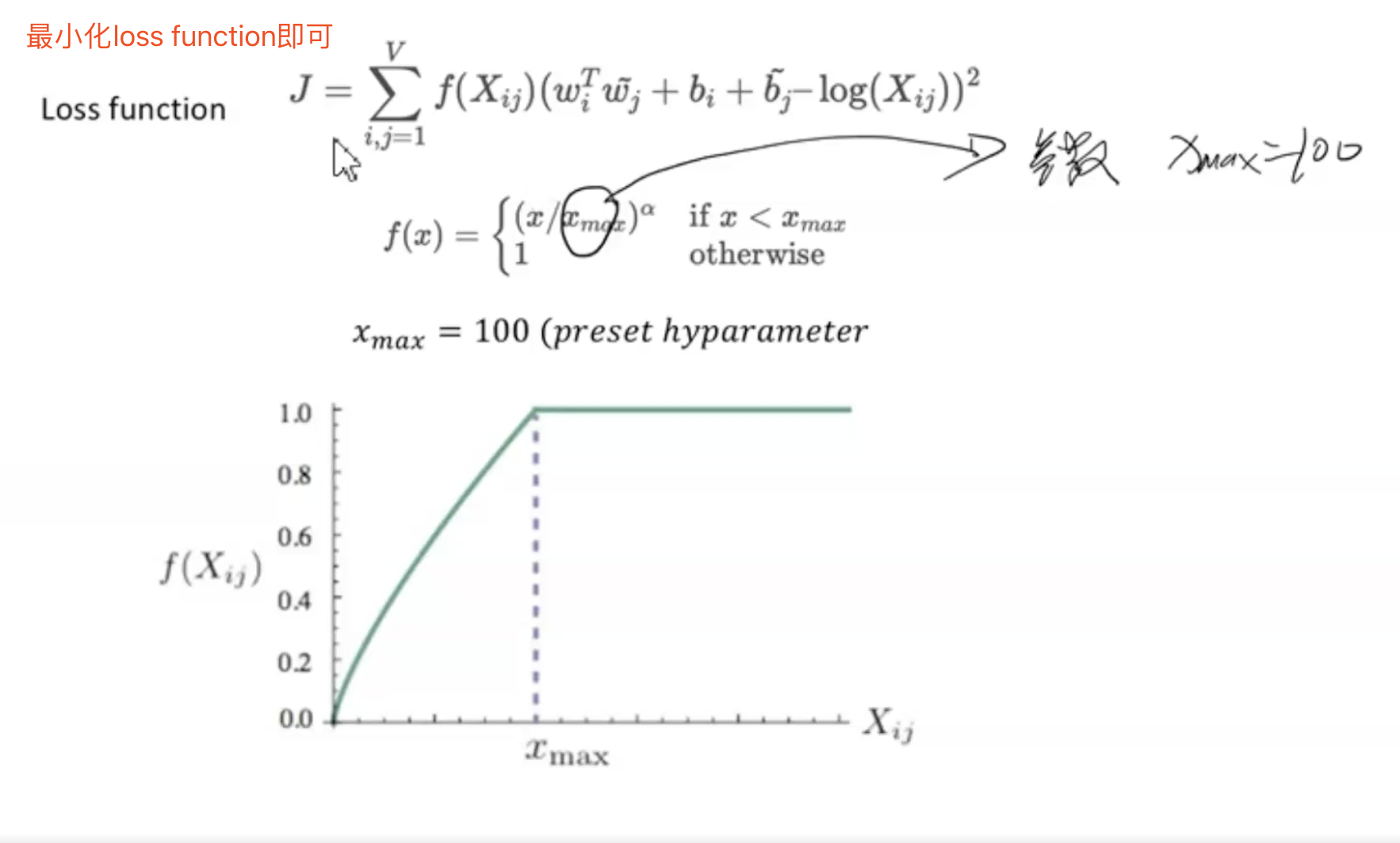
GloVe是一种利用共现矩阵来计算词向量的方法。具体过程如下面三张图所示,其中图glove1是计算共现矩阵的过程,我们需要根据语料库来构建共现矩阵。图glove2是构建loss function的过程,其中f(x)表示权重(词的频率越大则权重越大,频率越小则权重越小),图3则展示了f(x)的计算过程,即当词的频率小于100时,计算该词的频率,当词的频率大于100时,权重为1(其中100是设定的参数)。
具体如下图所示:
图glove1:

图glove2:

图glove3:
sentence embedding
论文:Weighted Bag-of-words + remove some special direction
step 1:构建平滑的加权词向量
step 2:计算PCA,减去最明显的第一个维度。

参考资料
[1]https://www.jianshu.com/p/471d9bfbd72f
[2]https://zhuanlan.zhihu.com/p/26306795
[3]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号