
[NLP]ELMO理解
论文地址:https://arxiv.org/pdf/1802.05365.pdf
简介
以往的词向量如word2vec、glove等词向量模型,针对某一个词生成的词向量都是固定的,无法解决一词多义现象,如“苹果”在不同的上下文中有不同的含义,它可表示一种水果、一个公司名称或者手机、电脑、平板电脑等物品的品牌名等,但是如果使用上述词向量模型生成词向量时,一个词只能对应一个词向量,这明显不能满足我们的需求。而在2018年的NAACL上,终于出现了一个能解决这种问题的词向量模型-ELMO(Embeddings from Language Models )。
1、ELMO的优势:
- 它能考虑上下文,针对不同的上下文生成不同的词向量。
- 它能表达不同的语法或语义信息。如“活动”一词,既可以是名词,也可以是动词,既可以做主语,也可以做谓语等。针对这种情况,elmo能够根据不同的语法或语义信息生成不同的词向量。
2、ELMO的缺点:
- 使用LSTM提取特征,而LSTM提取特征的能力弱于Transformer
- 使用向量拼接方式融合上下文特征,这种方式获取的上下文信息效果不如想象中好
ELMO模型结构
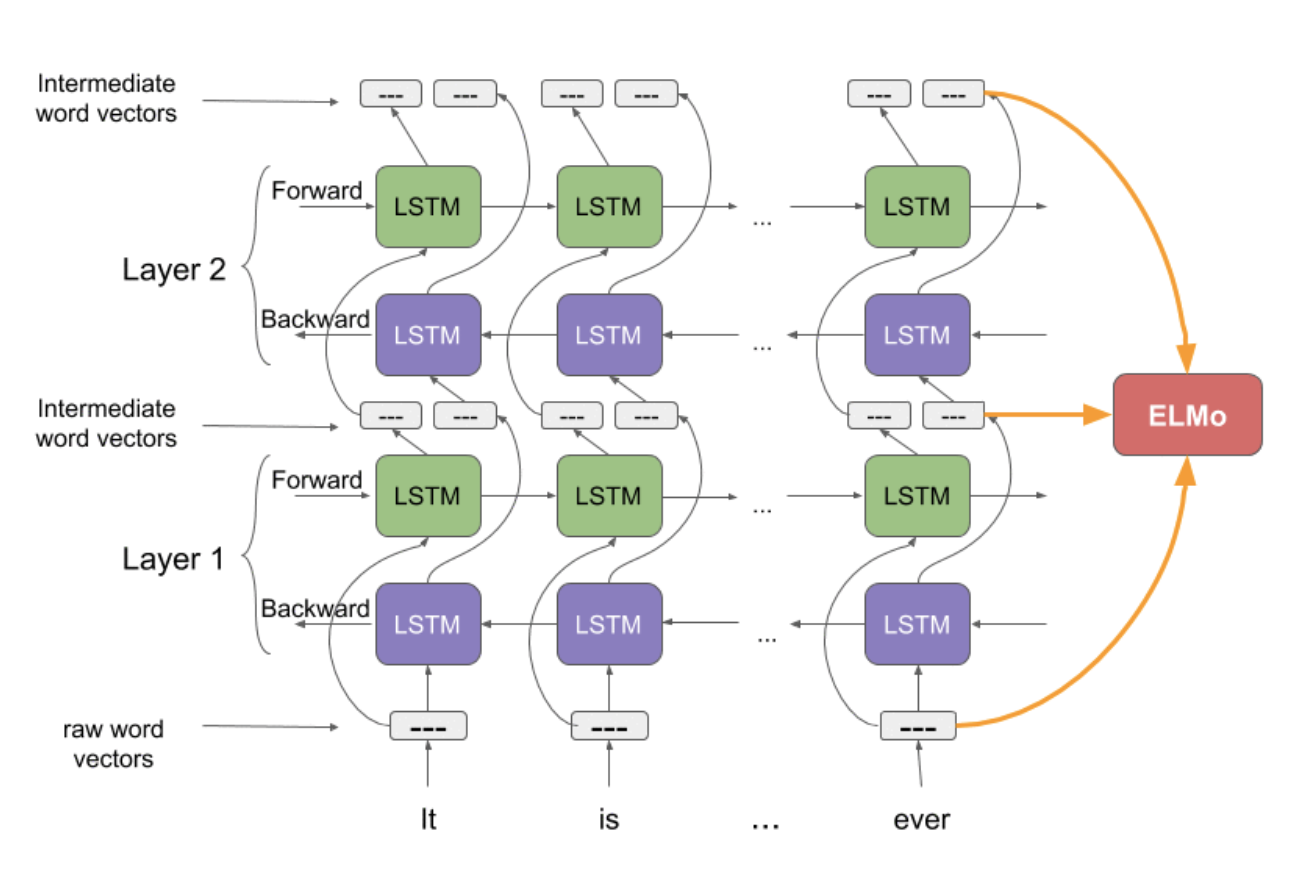
ELMO采用典型的两阶段过程:第一阶段用预训练语言模型训练,第二阶段是在做具体的下游任务时,从预训练模型中提取对应的词的word embedding作为特征补充到下游任务的输入中去。
第一阶段:预训练过程,采用双层双向LSTM对输入进行训练,如下图所示,单词特征使用静态的word embedding(如word2vec,glove等),每一个lstm层都将单词特征与其上文词向量和下文词向量进行拼接作为当前的输入向量,其中第一层lstm获取句法特征,第二层lstm获取语义特征。
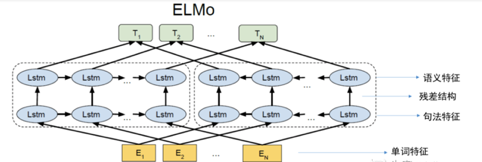
第二阶段:根据下游任务确认如何选择第一阶段的输出向量作为该阶段的输入向量,具体地说,输入语句经过第一阶段训练出的ELMO模型的处理后,会获取三个embedding,包括单词特征,句法特征(第一层lstm的输出向量),语义特征(第二层lstm的输出向量),可对这三个embedding进行加权求和后作为最终向量,输入到下游任务中去,这被称为“Feature-based Pre-Training”。
注1:ELMO在层与层之间使用残差连接,这样就可以实现双向的效果。
注2:ELMO使用双向的LSTM,它通过前向LSTM获取上文信息,后向LSTM结构获取下文信息,最终是将前向LSTM与后向LSTM生成的向量进行拼接,以表示获取上下文信息
ELMO中字向量的计算过程
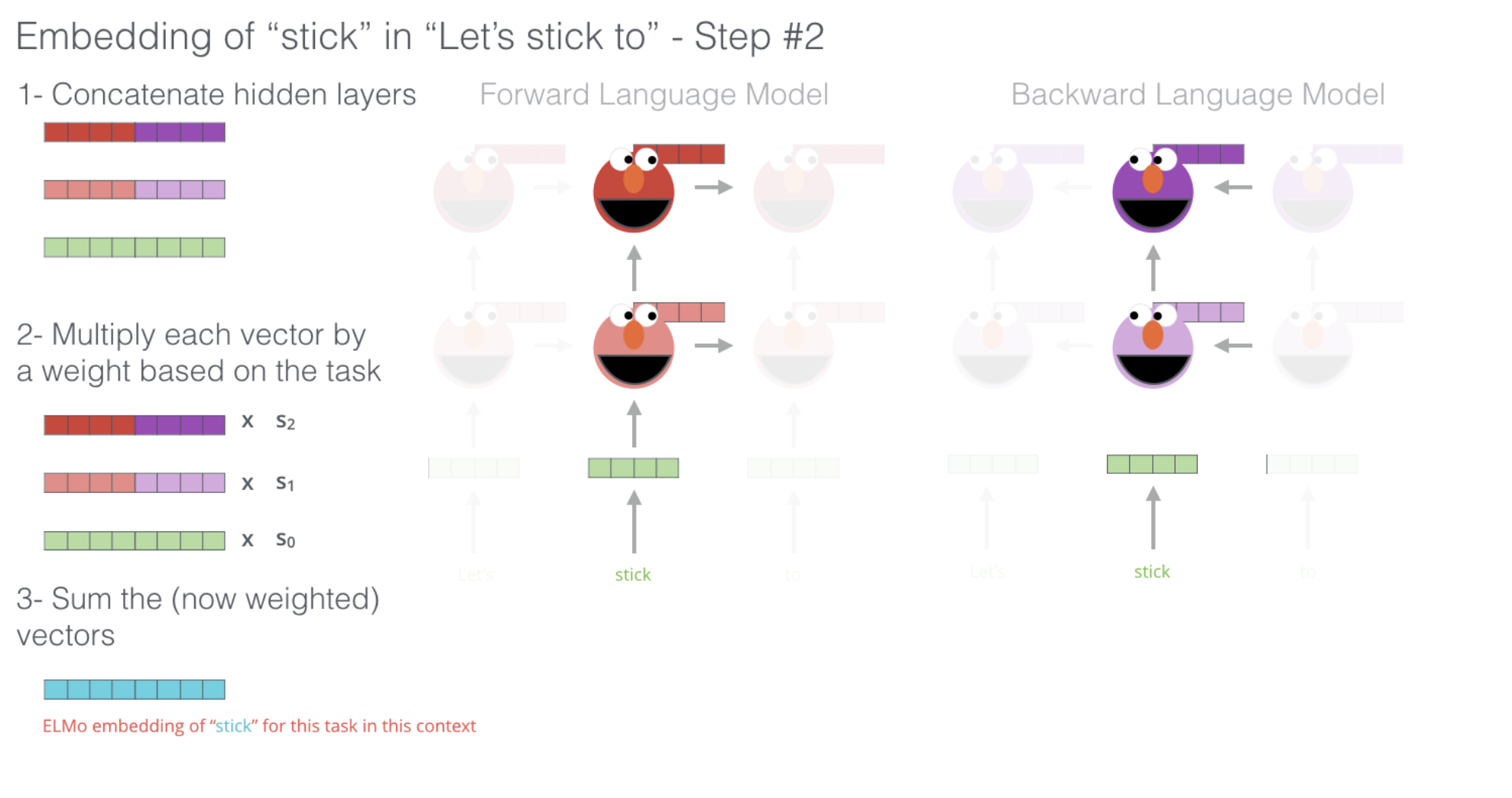
如上图所示,对于“Let’s stick to”这一句话,如果我们想计算“stick”的字向量,
1、拼接:首先使用传统的字向量生成方法静态生成一个字向量vec,如图中绿色长方块表示;之后分别将vec输入进第一层的前向lstm和后向lstm中,获取隐向量h11(表示第一层的前向lstm计算结果,图中浅粉色长方块表示)和h12(表示第一层的后向lstm计算结果,图中浅紫色长方块表示);然后将h11输入到第二层的前向lstm中,获取隐向量h21(表示第二层的前向lstm计算结果,图中红色长方块表示),将h12输入到第二层的后向lstm中,获取隐向量h22表示第二层的后向lstm计算结果,图中深紫色长方块表示)。
静态字向量vec自己拼接自己,形成一个大的绿色长方块;第一层隐向量h11和h12拼接形成h1;第二层隐向量h21和h22拼接形成h2。
2、加权:步骤1中的三个向量都有自己的权重(权重是训练出来的?),然后分别对这三个向量进行加权。
3、求和:将步骤2中的三个向量求和即可。这一步输出的就是字“stick”的根据上下文获取的字向量。
总结
ELMO虽然能够看到上下文信息,但是它只能看到单向的上下文信息,这样说是因为ELMO中前向lstm和后向lstm的网络是完全独立的,也就是说当使用前向lstm训练时,词 t 看不到 t+1及之后的所有词,同理使用后向lstm训练时,词 t 看不到 t - 1及之前的所有词,因此本质上来说它依然只能看到单向信息,所谓的“双向”只是将两个方向的信息进行拼接而已。这是ELMO的局限性。(与此相反的是,bert能够同时看到词 t 的上文和下文,因此bert是真正的获取双向信息)
参考资料
[1] https://bitjoy.net/2020/02/24/cs224n%ef%bc%882-19%ef%bc%89contextual-word-embeddings/
[2] https://www.cnblogs.com/zhaopAC/p/11219600.html
[3] https://www.analyticsvidhya.com/blog/2019/03/learn-to-use-elmo-to-extract-features-from-text/

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步