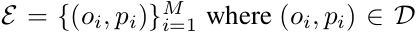Dictionary-Guided Editing Networks for Paraphrase Generation解读
过程:输入->检索->编码->解码
解释:检索:输入一句话x,首先从PPDB中检索出M * 10 个释义对,并排序,记为x的本地字典;
编码:将所有的释义对编码为向量,单字转为字向量,多字将 每个字向量加和;论文认为会得到2×M个向量
解码过程:
首先,使用BiRNN的输出作为x的表征,并用standard attention获取句子信息,用来计算c’_t,它是原句隐藏状态的加权平均;
![]() 其次,计算释义字典侧信息的上下文向量c_t,它用来指导解码器(删除还是增加一个token);
其次,计算释义字典侧信息的上下文向量c_t,它用来指导解码器(删除还是增加一个token);
再次,联结/级联h_t,c_t,c’_t,值为 ,其中h_t表示第t字的隐藏状态;
然后,利用softmax层,获取概率最大的句子y_t;
最后,计算最小NLL值
论文翻译:
1.方法论:
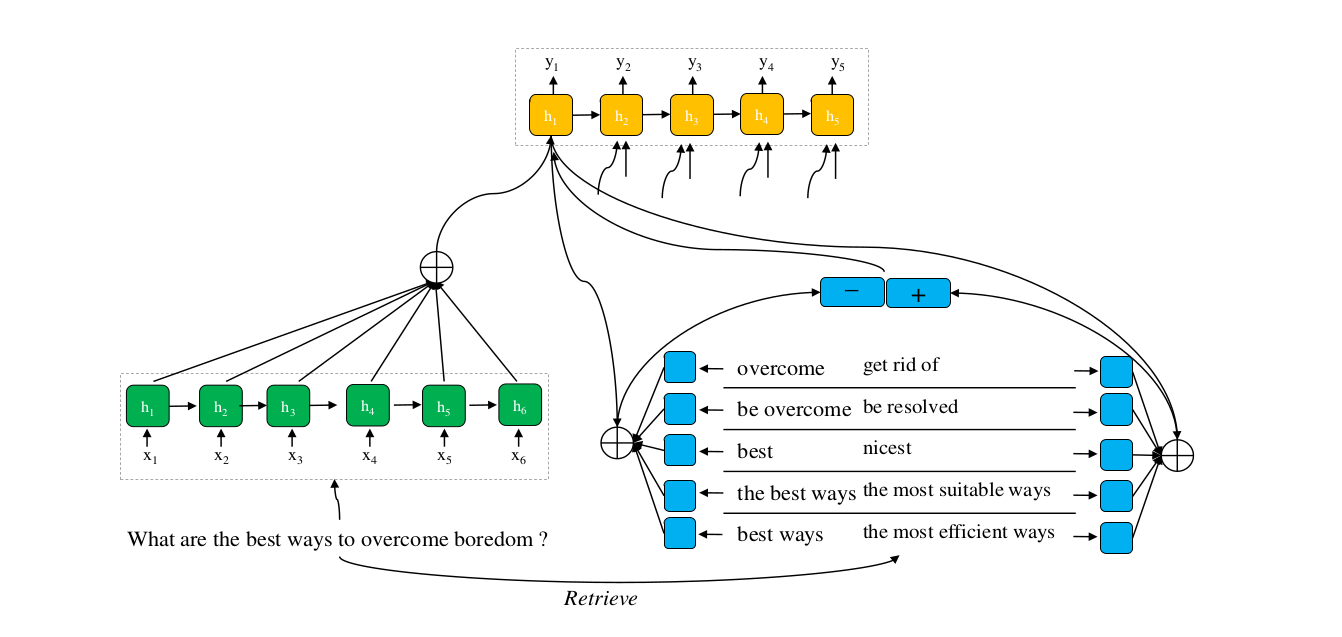
1)问题定义:有一个词汇或者短语字典(从PPDB中获取)
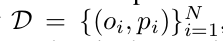
其中,o_i是原始字或者短语,p_i是o_i的字级或者短语级释义。有一个并行的数据集
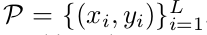
其 中,(x_i,y_i) 是一个释义对。我们的目标是利用D和P来学习一个释义生成器,以便于用y准确的释义一个新句子x.
模型概述:首先,对于原始句子x,我们先检索字级或者短语级的释义对集合