solr配置中文分词器
配置IK分词器
- 在
/opt/solr-7.7.1/server/solr-webapp/webapp/WEB-INF/lib目录中加入IK分词器的jar包 - 在
/opt/solr-7.7.1/server/solr/article_core/conf文件夹下的 managed-schema文件中配置IK中文分词器- 在managed-schema文件中配置ik分词器的配置
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" class="org.wltea.analyzer.lucene.IKAnalyzer" useSmart="false"/>
<analyzer type="query" class="org.wltea.analyzer.lucene.IKAnalyzer" useSmart="false"/>
</fieldType>
*测试分词效果
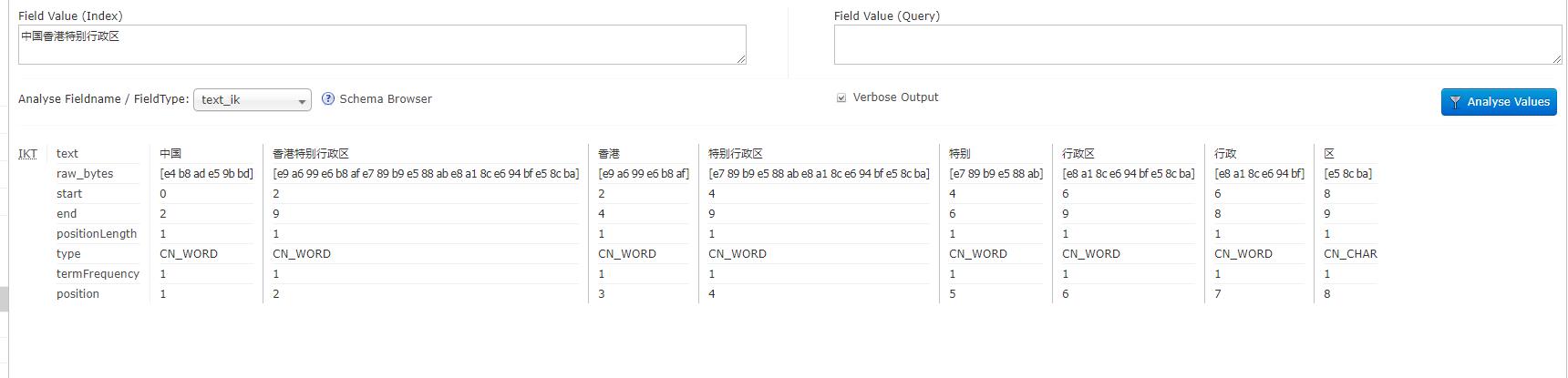
* 配置停用词 扩展词 同义词
停止词 的功能是过滤,把“啊”加入到停止词的字典里,比如搜索“你好啊”,solr会过滤掉“啊”,以“你好”去搜索。应该叫过滤词才好。
扩展词 的功能是强制让扩展词字典里的词不被中文分词器分开,叫它自定义词也好理解。
同义词:搜索结果里出现的同义词。如我们输入”还行”,得到的结果包括同义词”还可以”(需修改IK源码,IK同义词暂没实现)。
在`/opt/solr-7.7.1/server/solr-webapp/webapp/WEB-INF/`文件夹下创建classes文件夹
加入
`IKAnalyzer.cfg.xml`
`ext.dic`
` stopword.dic`
三个文件,在stopword.dic中配置你的停用词 ext.dic中配置自定义扩展词
* 在ext.dic中定义小米手机自定义扩展词后 对`小米手机`四个字分词的对比
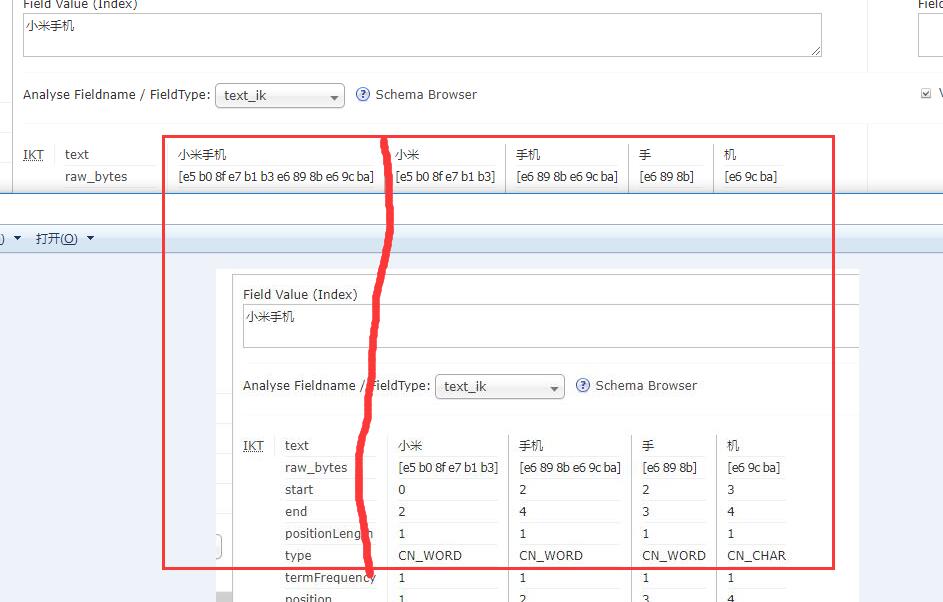
上面为自定义`小米手机`扩展词的分词效果,下面为没有定义扩展词的效果
配置smartcn中文分词器
-
复制
/opt/solr-7.7.1/contrib/analysis-extras/lucene-libs中的lucene-analyzers-smartcn-7.7.1.jar
至/opt/solr-7.7.1/server/solr-webapp/webapp/WEB-INF/lib中 -
编辑managed-schema文件加入
<!-- 配置smartcn分词器 -->
<fieldType name="text_smartcn" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>
- 测试分词效果
不推荐使用该分词器

 浙公网安备 33010602011771号
浙公网安备 33010602011771号