

面试及总结4
今天周末,导师让我来实验室,帮他一起把数据从服务器上拷贝下来,然后做预处理,周一上午给出结果。 现在干得都差不多了,放在服务器让自个跑着,我闲来没事就随便看看新闻,逛逛论坛,写写博客,回顾总结一下前天面试的经验教训和心得体会
先说说前天百度面试的经历吧,那天下课后匆匆在教学楼打印代码后,便直接骑车飞奔五道口13号地铁站,进站、刷卡、等车、呼呼……、下车、刷卡、出站、然后从西二旗以100米冲刺的速度狂奔百度大厦,跨进B座门后,手机显示16:48分,还好,总算没迟到!
和一面一样,提前5分钟预约面试官,17:00面试正式开始 balabala... 18:00面试over。刚好面试完后,哥哥就给我打电话问我面试的情况如何(可能哥哥就站在4楼看着我面试呢 ^_^),并让我在一楼大厅等一会,他下楼带我去百度一楼吃饭(这个点回学校肯定也都没饭啦) 于是我和哥哥一块下楼到百度食堂,也随便感受一下百度的食堂文化——哇,人好多啊!需要排队、需要刷卡、也有免费的绿豆汤。。。有点像中科院的食堂,颇具学校食堂的气氛——于是点了一份喜欢吃的鱼和一小盘海带丝,要了一大份米饭,端了一大碗绿豆汤,哥哥替我打卡,好好蹭饭呗 哈哈
面试的序幕和片尾都讲完了,下面再回放一段精彩的剧情吧——回顾一下面试GG让我用Linux Shell命令进行字符串匹配的那道题吧(第二道)
题目大意:给出一个文件,里面包含两个字段{url、size},url即为网址,size为网址对应访问的次数,要求:问题1、利用Linux Shell命令或自己设计算法,查询出url字符串中包含“baidu”子字符串对应的size字段值;问题2、根据问题1的查询结果,对其按照size由大到小的排列
面试时我采用的是自己设计算法,面试回来后我man sort查了排序命令的参数使用手册,下面我就详细讲一下用Shell命令的做法
分析题意:baidu.txt{url, size},baidu.txt是文件,{url, size}是文件中的两个字段,并且url和size都是字符串型,字段之间用tab(/t)隔开
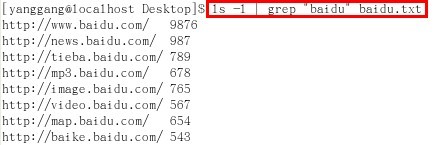
第一步,查询匹配url字符串中的字串"baidu",直接用grep命令,具体格式 grep "baidu" baidu.txt(每行仅url可能含有baidu子字符串)
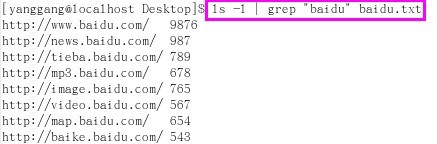
第二步,显示含有字串"baidu"的url及其对应的size,可以直接用ls命令,具体格式 ls -l | grep "baidu" baidu.txt(管道传值)
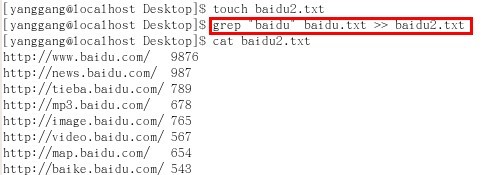
第三步,将步骤2的结果,通过重定向命令>>保存在baidu2.txt文件中,即 grep "baidu" baidu.txt >> baidu2.txt 保存匹配结果
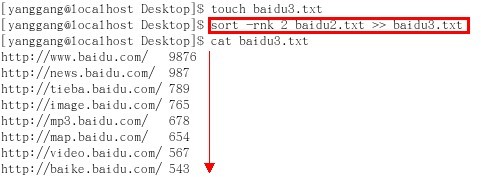
第四步,排序,直接利用sort命令,即格式ls -l | sort -rnk 2 baidu.txt (sort反向r、以第二个字段k 2、数值型n进行排序)
第五步,将步骤4的结果,通过重定向命令>>保存在baidu3.txt文件中,即 sort -rnk 2 baidu2.txt >> baidu3.txt 保存排序结果
按照上面五步,我们先看结果,用数据说话,然后我将在下面依次详细介绍上面五步中用到的Shell命令及其参数的确切含义:
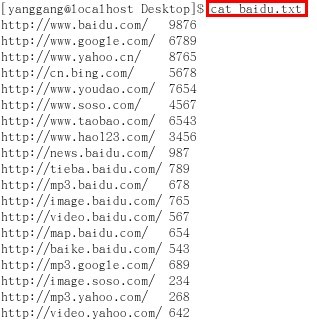
首先,新建baidu.txt文件,即用Vim编辑器输入创建的测试用例(我用过的主流搜索引擎及百度的部分产品),然后利用cat命令查看文件
其次,我们查询url字符串中包含子串"baidu"的项,并打印出url及其size
然后,我们新建baidu2.txt文件,用于保存问题1的结果(即匹配字符串url中包含子串"baidu"的结果项url和size)
接着,我们对上述问题1的结果,利用sort命令按照size由大到小进行排序

最后,我们新建baidu3.txt文件,用于保存sort排序结果
附图说明:
以上截图,均截自我电脑Linux RedHat 5.2(安装在VMWare 7.0虚拟机上)
其中的Shell命令都在Redhat Linux OS环境已测试通过
====================================================================================
好啦,今晚在man sort 查看了sort详细参数使用方法后,似乎可以不用awk命令就可以搞定此题,看来并没有我面试时想得那么复杂。现在就让我们具体看看sort的参数以及grep、重定向等Shell命令的详细使用方法吧
sort命令
格式:sort 【参数】 【文件】
举例:sort -rnk 2 baidu.txt
参数:r 逆序; n字符串按数值处理; k 2 表示第二个字段(列)
说明:在文件baidu.txt中,按照第二个字段的数值型由大到小进行排序
首先,在 Linux Shell命令行界面输入 man sort 查看 sort 的帮助手册
然后,查看本题中,我们需要用到的三个参数 r n k 的详细使用方法
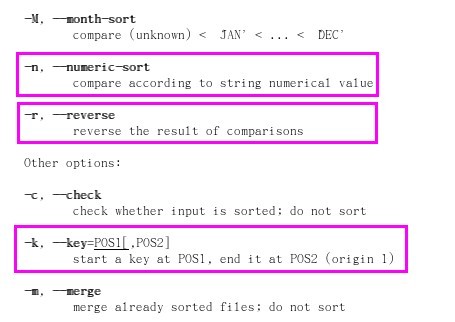
由sort帮助文档显示:
1、参数n是把string字符串转换成numberical的值value进行比较(即把字符串转换成数值型,再进行比较)
2、参数r是反向,即逆序。由于sort默认排序是由小到大,而题意需要从大到小排序,因此此处需要逆序(注意:v在某些命令中也可表示反向,如正则表达式中)
3、参数k是字段分隔,即从哪个字段开始直到哪个字段结束,按其进行排序(注意:Linux Redhat 第一列从1开始,而不是0,本题格式中size为第二列,因此我们k定为2,而不是1。区别于通常用的Array数组下限和Python语言中分组的下限,即从0开始)
grep命令
格式:grep 【参数】 【查询字符串】 【文件】
举例:grep "baidu" baidu.txt
参数:此处无参数(省略了参数)
说明:查询匹配文件baidu.txt中,判断是否包含"baidu"子字符串
在Linux Shell命令行输入:man grep

管道| 命令
格式:【命令1】(目标) |【命令2】(源数据)
参数:为进程通信,无参数
举例:ls -l | grep "baidu" baidu.txt
说明:把文件baidu.txt中,包含"baidu"子字符串的结果,通过管道|命令,传给ls -l 作为目标内容,进行显示
重定向>或>> 命令
格式:【命令1】(源数据)> 【命令2】(目标) 或者 【命令1】(源数据)>> 【命令2】(目标)
参数:为信道传值,无参数
举例:sort -rnk 2 baidu.txt > baidu2.txt
说明:把文件baidu.txt中,对第二个字段按照数值型进行由大到小的排序,并将结果保存到文件baidu2.txt(清空后重写)
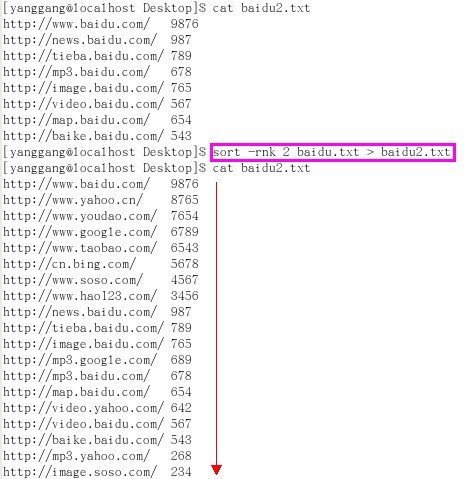
附图举例说明:先清空文件baidu2.txt中原有内容,然后再将sort结果重定向保存到baidu2.txt文件中
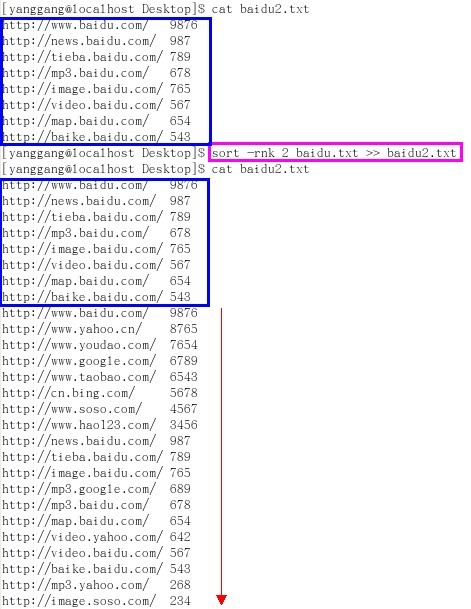
附图举例说明:先并未清空文件baidu2.txt中原有内容,而是直接追加sort结果,重定向保存到baidu2.txt文件中(保留baidu2.txt原有内容)
ls touch cat等其它基本命令,请详见我先前的博客 Linux Shell 常用命令与目录分区的学习总结
====================================================================================
第二步,查询匹配url字符串中是否含有字串"baidu"的另一种做法(在网友showmsg 的提示下,改用 awk 命令代替 grep 命令进行正则匹配)
当然,我们还是先看结果,然后我再介绍awk命令的使用方法
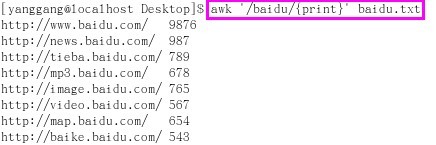
首先,我们查询并打印出含有"baidu"字串的url及其size
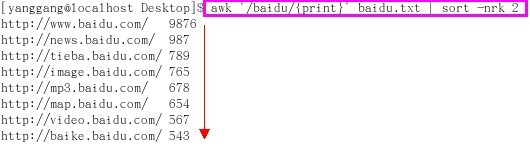
其次,我们对查询含有"baidu"的结果,对size进行有大到小的排序
最后,保存查询匹配"baidu"并对size由大到小排序后的结果到baidu2.txt文件中(重定向)

附加1,如果只想按照size由大到小打印出url(即不打印size,也就是分离字段),则如下
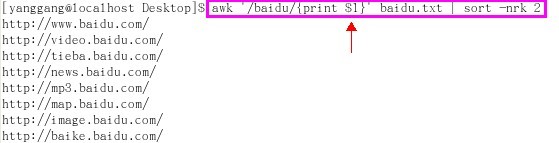
附加2,如果只想按照size由大到小打印出size(即不打印url,也就是分离字段),则如下
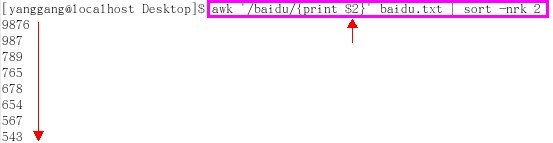
这便是我面试时想用awk命令的解法,不过当时我只知道此命令功能但没具体用过,今在网友showmsg 指点下,总算略通一二,对此表示谢意^_^
====================================================================================
awk 命令
格式:awk commands file 或者 awk script-file file
参数:print 打印;$1 第一个字段; $2 第二个字段; ' ' 单引号需加上,并可写入正则表达式,如查询baidu字串
举例:awk '/baidu/ && $2<800' baidu.txt
说明:查询文件baidu.txt中满足第一字段含有"baidu"字串并且第二个字段数字size<800的所有记录,并显示出结果

附图1:查询文件baidu.txt中满足第一字段含有"baidu"字串并且第二个字段数字size<800的所有记录,并显示出结果
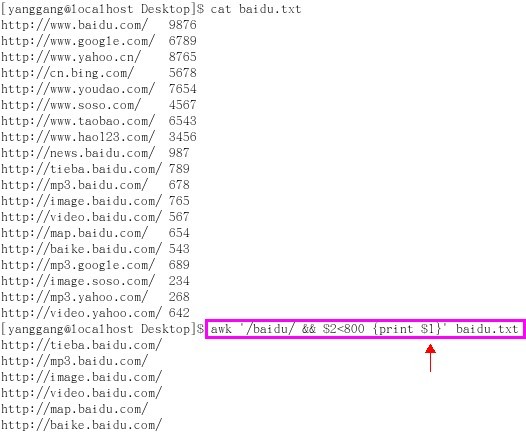
附图2:查询文件baidu.txt中满足第一字段含有"baidu"字串并且第二个字段数字size<800的所有记录,并打印出结果的第一个字段(url)

