
Python学习 day13
一、可迭代对象和迭代器
1、回顾可以被for循环的对象
list、dic、str、set、tuple、文件句柄f、range()、enumerate()
只有可迭代对象才能被for循环,当我们遇到一个新的变量,不确定能不能for循环时就判断它是否可迭代,那如何判断对象可迭代?
2、双下方法
dir() -- 打印一个对象的所有方法
打印一个列表的所有方法:
print(dir([]))
结果:
['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
可以看到,前面的方法前后都带有两条下划线,这就是我们说的双下方法
双下方法使用C语言写好的,可以有不同调用方式调用的方法,在实际使用中,我们一般不会直接调用双下方法,而是采用其他的调用方式。
如上面列表中的__add__方法:
print([1, 3] + [1, 2]) # 列表可以直接相加 print([1, 3].__add__([1, 2])) # 调用__add__方法
结果:

从这个例子可以理解,在实际使用时我们会使用“+”来对两个列表相加,但实际“+”机器是不认识的,在调用时实际上还是调用了__add__方法,根据方法中的步骤执行操作,包括数字的加减也是一样。
3、可迭代对象的秘密
利用dir我们可以得到所有可迭代对象的所有方法,为了找到可迭代的秘密,我们对可迭代对象的方法求交集:
print(set(dir([])) & set(dir(())) & set(dir({})) & set(dir(set([])))) # dir 获取的结果是集合,转化为set可求交集
结果:
{'__format__', '__doc__', '__ne__', '__setattr__', '__getattribute__', '__contains__', '__ge__', '__str__', '__init__', '__dir__', '__sizeof__', '__delattr__', '__reduce__', '__gt__', '__iter__', '__lt__', '__subclasshook__', '__repr__', '__len__', '__hash__', '__reduce_ex__', '__new__', '__le__', '__eq__', '__class__'}
“可迭代的”英文即“iterable”,在上面的方法中可以找到与这个词相近的方法__iter__方法,这个方法就是可迭代对象的秘密了
检验:
print('__iter__' in dir(range(10))) print('__iter__' in dir(enumerate([]))) print('__iter__' in dir(int)) print('__iter__' in dir(bool))
结果:
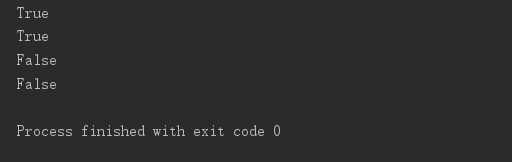
结论:只要是能被for循环的,即可迭代的,就一定拥有__iter__方法
4、迭代器
上面我们已经知道了__iter__方法,那执行__iter__方法后有什么结果?
print([].__iter__())
结果:
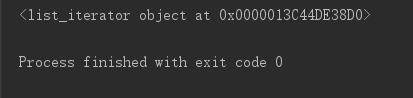
iterator即“迭代器”的意思,事实上,在调用__iter__方法后,该方法会返回一个迭代器。
再次使用set来计算迭代器与可迭代对象所拥有的方法差异:
print(set(dir([].__iter__())) - set(dir([]))) # 利用set求差集
结果:
{'__setstate__', '__next__', '__length_hint__'}
其中“__next__”就是我们要找的方法了,调用__next__将获取到迭代器的下一个元素
使用__length_hint__查看迭代器的元素个数
print(['momo', 2, 5, [1, 2, 3]].__iter__().__length_hint__())
结果:
4
判断迭代器的方法中是否有__iter__方法:
print('__iter__' in dir([].__iter__()))
结果:
True
所以迭代器也是可迭代对象,可以被for循环
5、可迭代协议和迭代器协议
可迭代协议 -- 只要含有__iter__方法的都是可迭代的(即可被for循环的)
迭代器协议 -- 内部含有__next__和__iter__方法的就是迭代器
可迭代的对象.__iter__()方法就可以得到一个迭代器
迭代器也是可迭代对象,迭代器调用__iter__()方法就返回它本身
迭代器中的__next__()方法可以一个一个地获取值
判断是否是可迭代对象或迭代器:
from collections import Iterable from collections import Iterator print(isinstance([], Iterable)) print(isinstance([], Iterator))
而且,根据上述两个协议,我们可以自定义对象来进行测试:
from collections import Iterable from collections import Iterator class A: def __iter__(self): pass # 可以注释掉再测试 def __next__(self): pass # 可以注释掉再测试 a = A() print(isinstance(a, Iterable)) print(isinstance(a, Iterator))
6、迭代器取值
- 使用__next__()/next()方法取值
iterator = [1, 4, 'python', [1, 2, 3], {'iter': 'iterator'}].__iter__() print(iterator.__next__()) print(iterator.__next__()) print(iterator.__next__()) print(next(iterator)) print(next(iterator))
结果:

迭代器的元素个数是固定的,最后一个值取完后如果再调用__next__就会报错:
Traceback (most recent call last):
File "F:/Users/alice/PycharmProjects/exercise/test/test18.py", line 30, in <module>
print(iterator.__next__())
StopIteration
next(iterator, default=None) -- 内置函数next()调用的应该就是__next__方法,看源代码注释:
"""
next(iterator[, default])
Return the next item from the iterator. If default is given and the iterator
is exhausted, it is returned instead of raising StopIteration.
"""
调用next()方法更好的一点是,如果default传了值,在迭代器耗尽后再取值不会抛异常,而是返回default的值。另外,就是之前说的,不要直接使用双下方法。
- 使用for循环取值
iterator = [1, 4, 'python', [1, 2, 3], {'iter': 'iterator'}].__iter__() for i in iterator: print(i)
结果:

for循环使用的是for关键字而不是调用某一方法,这里就可以想到,其实for循环实际是调用了某个双下方法。
可以推测,有__iter__方法的才能被for循环,所以for循环时首先调用__iter__方法,拿到迭代器,然后每次循环调用一次__next__方法,因为for循环是自动结束的,所以结束的标志自然是__next__报错Stop Iteration。验证可以自己写个类验证,添加__iter__和__next__方法,已验证。
- next和for
可迭代对象每调用一次__iter__方法都可以拿到一个新的迭代器
同一个迭代器从头到尾只能取一次,不循环
lst_iter = [1, 2, 3, 4, 5].__iter__() print(next(lst_iter, None)) print(next(lst_iter, None)) for i in lst_iter: print(i)
结果:
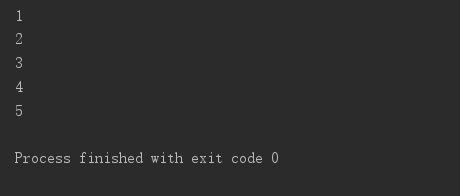
可以看到,不管用next还是for循环取值,迭代器中的值始终是顺序取值,一个迭代器每个元素只能取一次。
- 数据类型的强制转换
除了上述的常用的取值方法外,数据类型强制转换也是生成器的取值方法,如 lst = list(range(10)) ,但是这种取值方式一般不要用,因为转换相当于把所有值一次性取出,如果生成器内容很多,很容易造成内存占用过多。
7、迭代器的应用
目前使用迭代器的情况还比较少,之后在开发过程中,当调用别人写的函数拿到返回值时,可能存在返回值是迭代器的情况,这时需要合理判断,确定其是否为可迭代对象或迭代器。主要判断方法:
1、Iterator判断,直接打印,是Iterator对象的就是迭代器
2、可迭代对象,判断其中是否有__iter__方法,有就是可迭代对象
3、直接给内存地址,有时打印别人的函数的返回值可能输出是一个内存地址,这是可以判断其可能是迭代器
8、迭代器的特点
1、方便从容器类型中一个一个地取值,会把所有的值都取到
2、节省内存空间,如rang(),文件句柄
3、惰性运算,不要不给
二、生成器
写生成器有两种方式:
1、生成器函数
2、生成器表达式
1、生成器函数
先看示例:
1 def generator(): 2 print("第一个值") 3 yield "a" 4 print("第二个值") 5 yield "b" 6 7 8 g = generator() 9 print("generator运行了吗") 10 ret = next(g) # 调用__next__()也是可以的 11 print(ret) 12 ret = next(g) 13 print(ret)
结果:
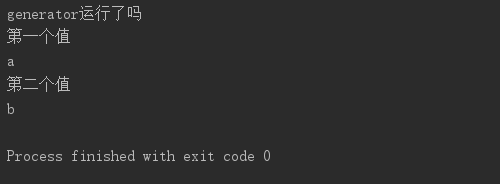
上面generator函数就是一个生成器函数,与普通函数不同的是,生成器函数中没有return,而是有yield
第8行执行generator函数后,可以看到实际上函数并没有执行,而是在第9行打印后,函数内代码才开始执行
所以生成器函数的执行过程是在第一次调用时会返回一个生成器,即g,生成器可以调用next方法取值,每次取值生成器函数向下执行,遇到yield停止,将yield后面的对象返回,即得到一个next取的值。
所以,生成器本质上就是一个迭代器。
生成器函数:只要含有yield关键字的函数就是生成器函数
yield不能和return共用,且需要写在函数内
2、监听文件输入的例子
有这样一个需求:写一个生成器,监听某一文件是否输入了新的内容,每输入一行就返回一行。
def tail(file_path): with open(file_path, encoding="utf-8") as f: while True: line = f.readline().strip() # 这里会过滤掉空行,如果不加strip()后面再输入的都会多一个空行,所以这里不能把完整的原文档显示,也是个小bug if line: yield line # for line in f: # line = line.strip() # if line: # yield line g = tail("../homework/employeeInfo") for i in g: print(i)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号