《DSGN:Deep Stereo Geometry Network for 3D Object Detection》论文解读
论文链接:https://arxiv.org/pdf/2001.03398.pdf
博客原作者Missouter,博客链接https://www.cnblogs.com/missouter/
文章用了许多方法定义了3D结构的表达,其中平面扫描体与3D几何体的建立是我接触立体检测之前没有接触过的,而最后的损失函数则和之前做过的目标检测大同小异,与单纯的目标检测不同的是损失函数中加入了3D检测框的损失回归。
【摘要】
大多数先进的3D目标检测器依赖线性向量,因对3D场景的表达方式不同,基于图像的检测方法与基于线性的方法有着巨大的性能差距。文章提出了一种深度立体几何的检测方法,通过在一种全新的3D几何体的表达方式上进行3D目标检测以降低性能差距,从而高效地将3D立体几何编码为3D规则空间;同时通过这种表达方式获取深度信息与语义提示。文章提供了一种简单有效的一阶段立体3D检测方式作为pipeline,DSGN较前者在AP上高了10%,在3D目标检测上甚至获得了与基于线性的检测方法相当的性能。
【创新优势】
要建立高效的3D表达,首先要将3D的几何信息精确地编码为3D空间。立体相机提供了像素相关的约束条件,为建立可以利用像素间约束条件的联合网络,文章提出了一种可以同时提取基于立体联系的像素层次关系与基于高层次特征的语义信息的深度结构。
同时像素对应约束是沿着投影光线通过每个像素施加的,每个像素深度被认为是确定的。文章从双目图像对中创建一个中间平面扫描体,以学习相机视锥体中的立体对应约束,然后将其转换为3D空间中的三维体。三维体拥有从平面扫描中获得的3D结构信息,从而使得模型能够更好的从真实世界中的物体中学习3D特征。
DSGN结构如下:
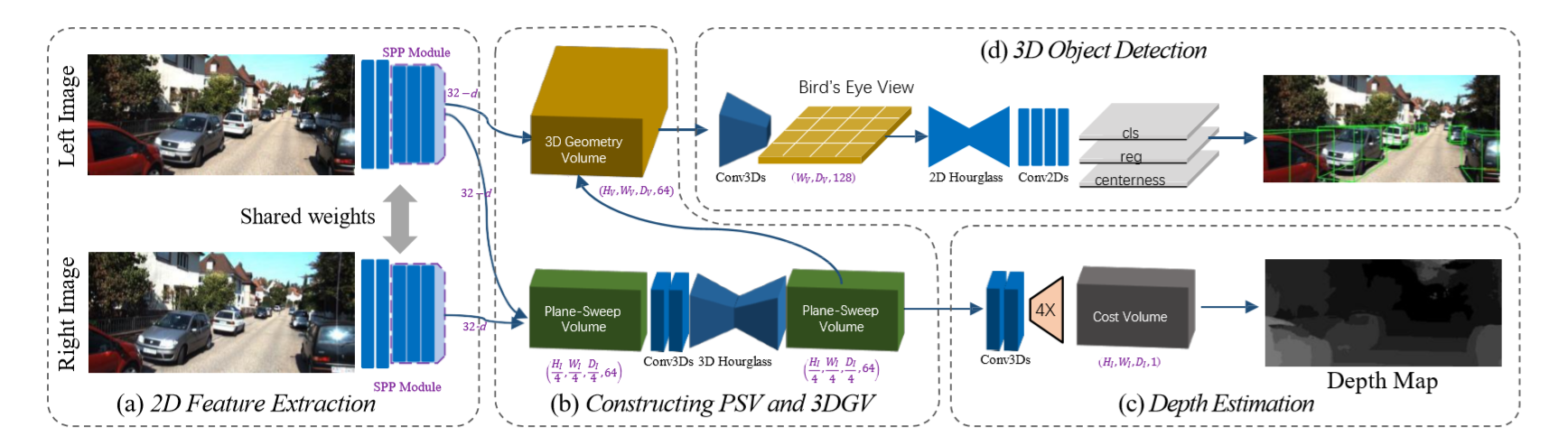
整个网络结构分为四部分:a部分以双目图像对为输入,通过一个孪生神经网络提取像素与高层次特征;在b部分使用平面扫描体学习像素相关性,通过可微变形,将平面扫描体变为3D几何体来建立3D世界中的3D几何结构,3D神经网络据此学习3D检测必要的结构。C部分用于在平面扫描体上估计像素深度;d部分为基于3D几何体的3D目标检测。
【图像特征提取】
从a部分的图片特征提取看起,文章借鉴了PSMNet的网络结构用于立体匹配。为满足检测网络高级别语义特征与大信息量的需求,该网络将接受更多高级别的信息。接下来是论文中一个让笔者费解的点,文章原文为:Besides, the following 3D CNN for cost volume aggregation takes much more computation, which gives us room to modify the 2D feature extractor without introducing extra heavy computation overhead in the overall network.初读不太理解为什么更多用于成本体积聚合的计算,能使2D特征提取器的修改不会给整个网络带来额外的计算开销。对此我导师给出的解释是3D匹配的计算量比较大,在提取3D特征的同时,提取2D特征并不需要额外的计算量,计算量都包含在了3D的端到端网络里。
网络结构细节:文章的5个卷积层套用文献《Deep residual learning for image recognition》,所作的修整包括增加第3、4层间的计算量将2至5层的基础模块由3、16、3、3调整至3、6、2、4;通过SPP模块将第四层卷积与第五层卷积的输出串接起来;输出通道的数量增加,在第一个卷积层由32变为64,每个基本残差块的输出由128增加至192。
【平面扫描体的建立】
为了学习3D卷积特征,文章将一个扫描平面体可微地弯曲成一个3D几何体:将三维世界空间中感兴趣的区域沿相机视野的左、下与前方向离散成三维体素占用网格,每个体素(vw , vh, vd)代表其在网络中的宽、高、代价体积;在双目视觉的一个图像对被用于构造基于视差的代价体积,以此计算匹配代价,该代价体积将左图像中的像素与右图像中的对应像素水平偏移一个积分视差值d。接下来是让笔者费解的第二个点,在构建平面扫描体的部分,原文有:In binocular vision, an image pair (IL,IR) is used to construct a disparity-based cost volume for computing matching cost, which matches a pixel I in the left image IL to the correspondence in the right image IR horizontally shifted by an integral disparity value d. The depth is inversely proportional to disparity.最后得出的结论是积分视差值d与深度成反比,涉及到双目立体视觉的原理,深度小,离相机的距离就近。
在构建代价体的过程中,为避免特征到三维空间的不平衡映射,文章遵循经典的平面扫描方法将左图像特征和右图像特征以等间距的深度间隔连接来构造平面扫描体。PSV的坐标以(u, v , d)表示,u,v表其在图像上的位置,d轴与u、v轴正交,表示深度;候选深度di以vd为间隔位于预定的三维网格沿深度尺寸均匀采样,使得网络能够学习用于对象识别的语义特征。为了简化计算,文章应用了一个三维沙漏模块。同时文章表示由于整个网络是可微的,因此在下面的检测网络中可以补偿由此导致的性能下降。
【3D几何体的建立】
在已知摄像机焦距的前提下,文章通过反置三维投影,将平面扫描得到的最后一幅特征图(u, v , d)从摄像机截面空间转换为三维世界空间(x, y, z),由矩阵转化公式:
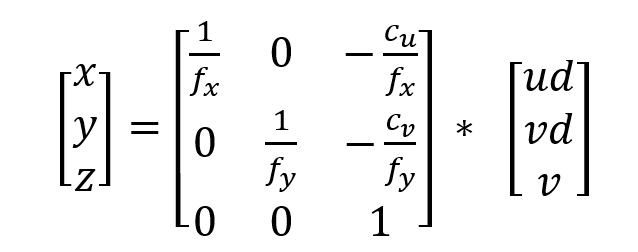
fx、fy为相机的水平、垂直焦距。这种变换是完全可微的,且可通过消除预先定义的网格之外的背景节省计算量,可用三线性插值的翘曲运算实现。上述转换过程如图所示:

将图像以等间距深度投影到左侧摄影机视锥体中得到平面扫描体PSV,图像在中间的摄影机截面空间是扭曲的,通过前文定义的矩阵变换映射,平面扫描体被扭曲为3D几何体,从而汽车的图像得到恢复。计算得到的具有低代价体素(u, v, d)表示沿光线通过焦点和像素点(u, v)在深度d处有高概率存在物体。
【平面扫描代价体积的深度回归】
为了计算平面扫描体上的匹配代价,文章对平面扫描体的最终特征图进行两次三维卷积得到一维代价体。Soft-arg-min运算用于计算所有候选深度的期望值,有计算公式:
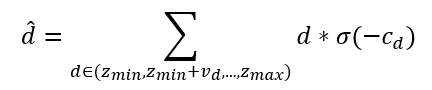
其中σ(-cd)为对应点存在物体的概率。候选深度在预定网格[zmin,zmax]内均匀采样,间隔为匹配代价vd。softmax作为激活函数,使模型为每个像素选择一个深度平面。
【基于3D几何体的3D目标检测】
文章参考了FCOS中心分支的思想,设计了一种基于距离在真实世界中的定位目标策略,因在3D场景中同类目标的大小类似。锚点的设计被保留下来。
设V∈RW*H*D*C为尺寸为(W, H, D)的3D几何体的特征图,并将通道表示为C。考虑到自动驾驶的方案,文章沿着高度维度逐渐向下采样,相当于沿着高度方向投影,最终得到鸟瞰尺寸(W, H)的特征图F。
对于F中的每个位置(x, z),放置几个不同方向和尺寸的锚。锚A和地面真实框G由位置、先前尺寸和方向表示,即(xA ,yA ,zA , wA, lA , θA )和(xG ,yG ,zG , wG, lG , θG )。网络从锚点回归得到最终预测值,
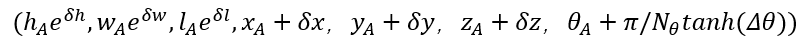
其中Nθ表示锚定向的数量,δ是每个参数的学习偏移量。
考虑到目标的朝向,文章提出了基于距离的目标分配方法。该距离定义为锚和地面真实框之间8个点的距离,如下所示:
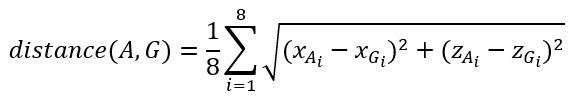
为了平衡正负样本的比例,文章将前N个距离地面真实最近的锚定点作为正样本,其中N=γ*k, k是鸟瞰图上地面真实框内的体素数。Γ用于调整阳性样本的数量。中心值被定义为八个角的负标准化距离的指数,有计算公式:

【多任务训练的损失函数】
多任务训练整体的损失函数被定义为:
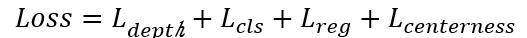
而深度回归的函数引入了smooth损失,具体为:

其中ND表示体素数量;
焦点损失被用于改善3D空间中分类不平衡的问题,分类损失被表达为:
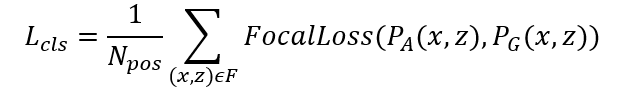
其中Npos表示正样本的数量。
3D回归框的损失函数同样引入了smooth损失,有:
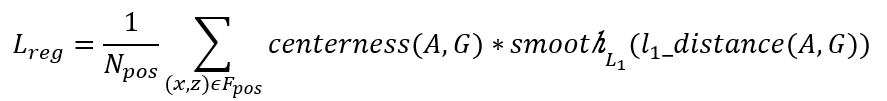
Fpos表示鸟瞰图中所有的正样本。
关于这篇3D检测论文的理论部分解读到这里就结束了,有机会会对实验部分进行跟进。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号