


最近在学习spark相关知识。准备搭建eclipse开发环境。在安装过程中遇到的问题记录下来。
首先在scala网站上下载了scalaIDE:http://scala-ide.org/download/prev-stable.html
下载完成后,新建scala项目,在项目上右键, 选择properties,
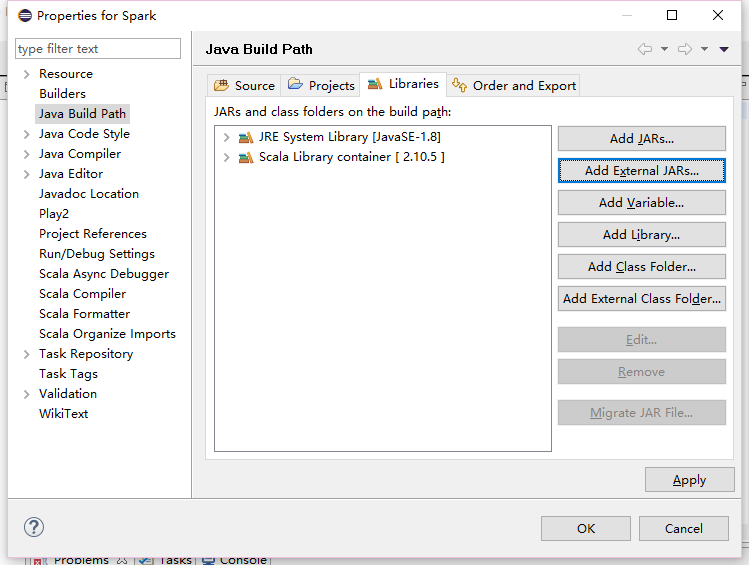
添加spark的jar包。
编写wordcount 程序,
package example import org.apache.spark._ import SparkContext._ object WordCount { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("worldCount") val sc = new SparkContext(conf) val textFile = sc.textFile(args(0)) val result = textFile.flatMap(line => line.split(" ")) .map(word => (word, 1)).reduceByKey(_+_) result.saveAsTextFile(args(1)) } }
将程序导出为jar包,拷贝至linux上,执行命令:
./spark-submit --class example.WordCount --master spark://192.168.1.241:7077 /opt/word-count.jar /opt/spark/README.md /opt/result
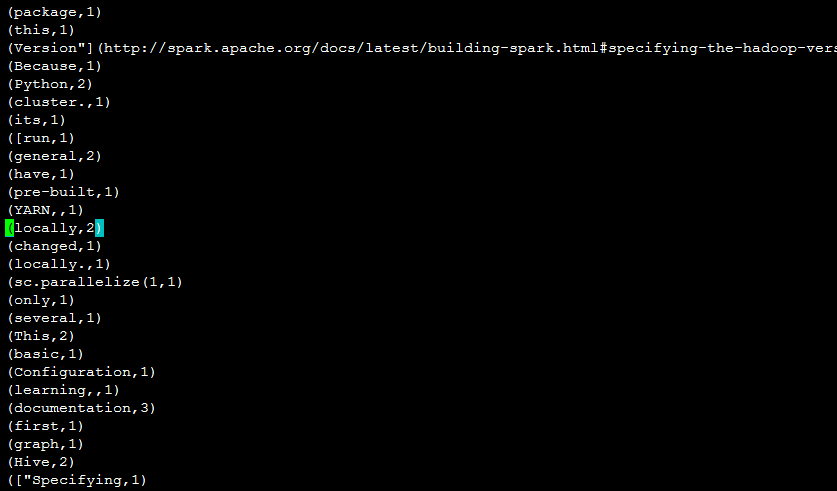
运行结果:
注意: 搭建spark集群时,最好选择spark-with-hadoop,否则会出现缺少hadoop jar 包的问题
