知识蒸馏
十岁的小男孩
本文为终端移植的一个小章节。
引言
蒸馏神经网络,是Hinton在上面这篇论文提出来的一个概念。文章开篇用一个比喻来引入网络蒸馏:
昆虫作为幼虫时擅于从环境中汲取能量,但是成长为成虫后确是擅于其他方面,比如迁徙和繁殖等。
同理神经网络训练阶段从大量数据中获取网络模型,训练阶段可以利用大量的计算资源且不需要实时响应。然而到达使用阶段,神经网络需要面临更加严格的要求包括计算资源限制,计算速度要求等等。
由昆虫的例子我们可以这样理解神经网络:一个复杂的网络结构模型是若干个单独模型组成的集合,或者是一些很强的约束条件下(比如dropout率很高)训练得到的一个很大的网络模型。一旦复杂网络模型训练完成,我们便可以用另一种训练方法:“蒸馏”,把我们需要配置在应用端的缩小模型从复杂模型中提取出来。
“蒸馏”的难点在于如何缩减网络结构但是把网络中的知识保留下来。知识就是一幅将输入向量导引至输出向量的地图。做复杂网络的训练时,目标是将正确答案的概率最大化,但这引入了一个副作用:这种网络为所有错误答案分配了概率,即使这些概率非常小。
我们将复杂模型转化为小模型时需要注意保留模型的泛化能力,一种方法是利用由复杂模型产生的分类概率作为“软目标”来训练小模型。在转化阶段,我们可以用同样的训练集或者是另外的“转化”训练集。当复杂模型是由简单模型复合而成时,我们可以用各自的概率分布的代数或者几何平均数作为“软目标”。当“软目标的”熵值较高时,相对“硬目标”,它每次训练可以提供更多的信息和更小的梯度方差,因此小模型可以用更少的数据和更高的学习率进行训练。
像MNIST这种任务,复杂模型可以给出很完美的结果,大部分信息分布在小概率的软目标中。比如一张2的图片被认为是3的概率为0.000001,被认为是7的概率是0.000000001。Caruana用logits(softmax层的输入)而不是softmax层的输出作为“软目标”。他们目标是是的复杂模型和小模型分别得到的logits的平方差最小。而我们的“蒸馏法”:第一步,提升softmax表达式中的调节参数T,使得复杂模型产生一个合适的“软目标” 第二步,采用同样的T来训练小模型,使得它产生相匹配的“软目标”
“转化”训练集可以由未打标签的数据组成,也可以用原训练集。我们发现使用原训练集效果很好,特别是我们在目标函数中加了一项之后。这一项的目的是是的小模型在预测实际目标的同时尽量匹配“软目标”。要注意的是,小模型并不能完全无误的匹配“软目标”,而正确结果的犯错方向是有帮助的。
设计思想
在用神经网络训练大规模数据集时,为了处理复杂的数据分布:一种做法是建立复杂的神经网络模型,例如含有上百层的残差网络,这种复杂的网络往往含有多达几百万个参数;
另一种做法往往会混合多种模型,将几个大规模的神经网络在同一个数据集上训练好,然后综合(ensemble)多个模型,得到最终的分类结果。
但是这种复杂模型,一是在新的场景下重新训练成本过高,二是由于模型过于庞大而难以大规模部署(deployment)。
所以,最基本的想法就是将大模型学习出来的知识作为先验,将先验知识传递到小规模的神经网络中,之后实际应用中部署小规模的神经网络。这样做有三点依据:
大规模神经网络得到的类别预测包含了数据结构间的相似性;
有了先验的小规模神经网络只需要很少的新场景数据就能够收敛;
Softmax函数随着温度变量(temperature)的升高分布更均匀。
1. 数据结构间的相似性:
神经网络模型在预测最终的分类结果时,往往是通过softmax函数产生概率分布的:
这里将T定义为温度参数,是一个超参数,q_i是i类的概率值大小。
比如一个大规模网络,如ImageNet这样的大网络,能够预测上千种类别,正确类别的概率值能够达到0.9,错误类的概率值可能分布在10^-8~10^-3这个区间中。虽然每个错误类别的的概率值都很小,但是10^-3还是比10^-8高了五个数量级,这也反映了数据之间的相似性。
比如一只狗,在猫这个类别下的概率值可能是0.001,而在汽车这个类别下的概率值可能就只有0.0000001不到,这能够反映狗和猫比狗和汽车更为相似,这就是大规模神经网络能够得到的更为丰富的数据结构间的相似信息。

2. 将大规模神经网络的soft target作为训练目标
由于大规模神经网络在训练的时候虽然是通过0-1编码来训练的,由于最后一层往往使用softmax层来产生概率分布,所以这个概率分布其实是一个比原来的0-1 编码硬目标(hard target)更软的软目标(soft target)。这个分布是由很多(0,1)之间的数值组成的。
同一个样本,用在大规模神经网络上产生的软目标来训练一个小的网络时,因为并不是直接标注的一个硬目标,学习起来会更快收敛。
更巧妙的是,这个样本我们甚至可以使用无标注的数据来训练小网络,因为大的神经网络将数据结构信息学习保存起来,小网络就可以直接从得到的soft target中来获得知识。
这个做法类似学习了样本空间嵌入(embedding)信息,从而利用空间嵌入信息学习新的网络。
3. 随着温度上升,软目标分布更均匀
公式(1)中,T参数是一个温度超参数,按照softmax的分布来看,随着T参数的增大,这个软目标的分布更加均匀。
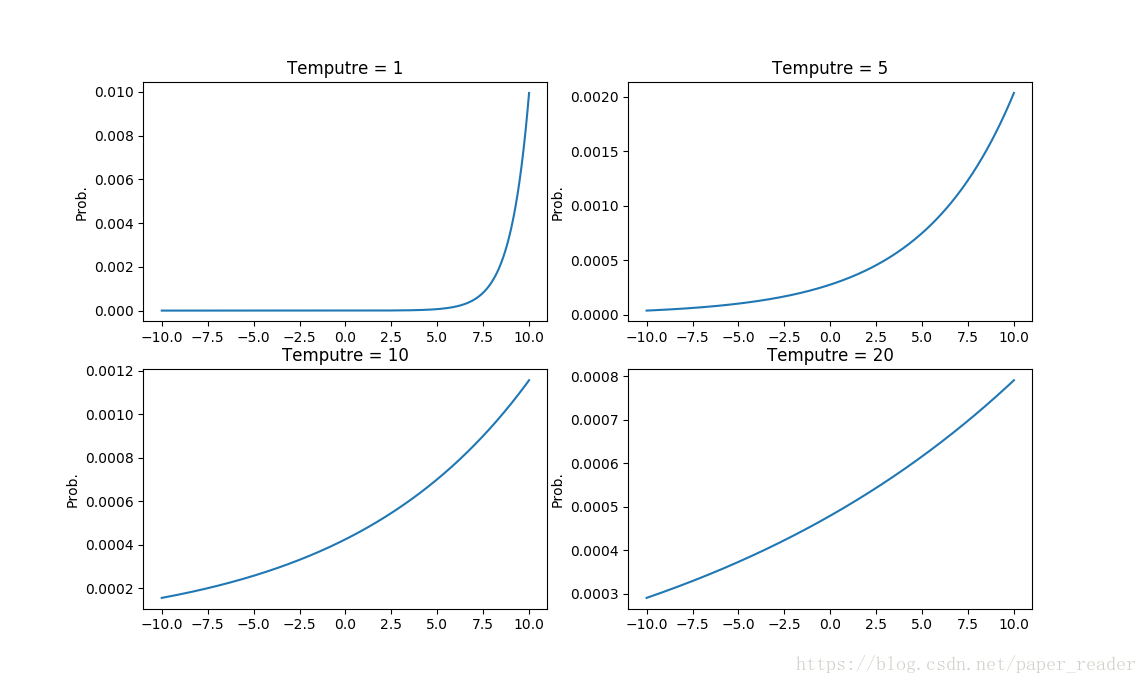
因此:
首先用较大的T值来训练模型,这时候复杂的神经网络能够产生更均匀分布的软目标;
之后小规模的神经网络用相同的T值来学习由大规模神经产生的软目标,接近这个软目标从而学习到数据的结构分布特征;
最后在实际应用中,将T值恢复到1,让类别概率偏向正确类别。
所以,蒸馏神经网络取名为蒸馏(Distill),其实是一个非常形象的过程。
我们把数据结构信息和数据本身当作一个混合物,分布信息通过概率分布被分离出来。首先,T值很大,相当于用很高的温度将关键的分布信息从原有的数据中分离,之后在同样的温度下用新模型融合蒸馏出来的数据分布,最后恢复温度,让两者充分融合。这也可以看成Prof. Hinton将这一个迁移学习过程命名为蒸馏的原因。
论文
A. Distilling the Knowledge in a Neural Network
B. A survey on transfer learning.
C. Model compression.
Buciluǎ, Cristian, Rich Caruana, andAlexandru Niculescu-Mizil. "Model compression." Proceedings of the12th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2006.
知识应该是开源的,欢迎斧正。929994365@qq.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号