教师-学生网络
十岁的小男孩
本文为终端移植的一个小章节。
目录
概念
论文
概念
教师--学生网络的方法,属于迁移学习的一种。迁移学习也就是将一个模型的性能迁移到另一个模型上,而对于教师--学生网络,教师网络往往是一个更加复杂的网络,具有非常好的性能和泛化能力,可以用这个网络来作为一个soft target来指导另外一个更加简单的学生网络来学习,使得更加简单、参数运算量更少的学生模型也能够具有和教师网络相近的性能,也算是一种模型压缩的方式。
论文
A: Distilling the Knowledge in a Neural Network
较大、较复杂的网络虽然通常具有很好的性能,但是也存在很多的冗余信息,因此运算量以及资源的消耗都非常多。而所谓的Distilling就是将复杂网络中的有用信息提取出来迁移到一个更小的网络上,这样学习来的小网络可以具备和大的复杂网络想接近的性能效果,并且也大大的节省了计算资源。这个复杂的网络可以看成一个教师,而小的网络则可以看成是一个学生。
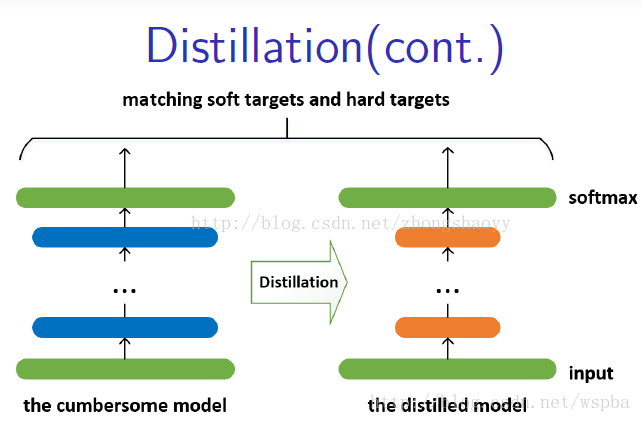
这个复杂的网络是提前训练好具有很好性能的网络,学生网络的训练含有两个目标:一个是hard target,即原始的目标函数,为小模型的类别概率输出与label真值的交叉熵;另一个为soft target,为小模型的类别概率输出与大模型的类别概率输出的交叉熵,在soft target中,概率输出的公式调整如下,这样当T值很大时,可以产生一个类别概率分布较缓和的输出: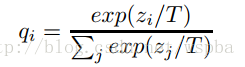
作者认为,由于soft target具有更高的熵,它能比hard target提供更加多的信息,因此可以使用较少的数据以及较大的学习率。将hard和soft的target通过加权平均来作为学生网络的目标函数,soft target所占的权重更大一些。 作者同时还指出,T值取一个中间值时,效果更好,而soft target所分配的权重应该为T^2,hard target的权重为1。 这样训练得到的小模型也就具有与复杂模型近似的性能效果,但是复杂度和计算量却要小很多。
对于distilling而言,复杂模型的作用事实上是为了提高label包含的信息量。通过这种方法,可以把模型压缩到一个非常小的规模。模型压缩对模型的准确率没有造成太大影响,而且还可以应付部分信息缺失的情况。
B: Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer
作者借鉴Distilling的思想,使用复杂网络中能够提供视觉相关位置信息的Attention map来监督小网络的学习,并且结合了低、中、高三个层次的特征,示意图如下:
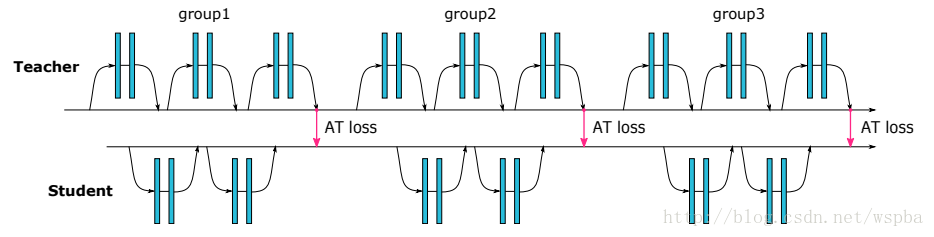
教师网络从三个层次的Attention Transfer对学生网络进行监督。其中三个层次对应了ResNet中三组Residual Block的输出。在其他网络中可以借鉴。 这三个层次的Attention Transfer基于Activation,Activation Attention为feature map在各个通道上的值求和,基于Activation的Attention Transfer的损失函数如下: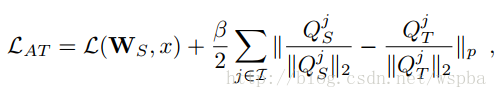
其中Qs和Qt分别是学生网络和教师网络在不同层次的Activation向量,作者提出在这里在这里对Q进行标准化对于学生网络的训练非常重要。
除了基于Activation的Attention Transfer,作者还提出了一种Gradient Attention,它的损失函数如下:
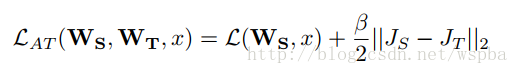
但是就需要两次反向传播的过程,实现起来较困难并且效果提升不明显。 基于Activation的Attention Transfer效果较好,而且可以和Hinton的Distilling结合。
总结
教师学生网络的方法,利用一个性能较好的教师网络,在神经元的级别上,来监督学生网络的训练,相当于提高了模型参数的利用率。其实可以这么来理解,我们一般训练一个神经网络就像是要爬一座山,你的target就是山顶的终点线,给了你一个目标,但是需要你自己去摸索如何找到通往终点的路,你就需要不断学习不断尝试,假如你的体力有效,可能就难以达到目标;但是如果这个时候有一个经验丰富的老司机,他以及达到过终点,那么他就可以为你指明一条上山的路,或者在路上给你立很多路标,你就只要沿着路标上山就好了,这样你也能够很容易的到达山顶,这就是教师--学生网络的意义。
知识应该是开源的,欢迎斧正。929994365@qq.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号