核稀疏化
十岁的小男孩
本文为终端移植的一个小章节。
目录
概念
Regular法
Irregular法
论文
A. Learning Structured Sparsity in Deep Neural Networks
B. Dynamic Network Surgery for Efficient DNNs
C. Training Skinny Deep Neural Networks with Iterative Hard Thresholding Methods
概念
核的稀疏化,是在训练过程中,对权重的更新加以正则项进行诱导,使其更加稀疏,使大部分的权值都为0。我们大多数情况下,在网络loss上面增加的权重衰减,是用权重的L2范数,制约数据损失,起到提高泛化能力的作用,如果再增加一项正则,如下:
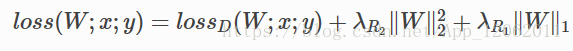
其中第一项数据损失,第二项,权重的L2正则,第三项,稀疏化正则L1,这样也可以起到模型压缩的作用。
另外,上面这种正则是对每个节点进行限制,还有组正则,即指定一个组单位(可以是卷积核,通道,层),进行正则,如下:
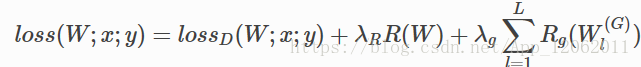
其中:
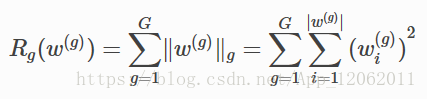
核的稀疏化方法分为regular和irregular。
Regular法
regular的稀疏化后,裁剪起来更加容易,尤其是对im2col的矩阵操作,效率更高。
Irregular法
irregular的稀疏化后,参数需要特定的存储方式,或者需要平台上稀疏矩阵操作库的支持。
论文
该节摘录核稀疏化的三篇论文探入不深,请读者自行研读。
A. Learning Structured Sparsity in Deep Neural Networks
本文作者提出了一种Structured Sparsity Learning的学习方式,能够学习一个稀疏的结构来降低计算消耗,所学到的结构性稀疏化能够有效的在硬件上进行加速。 传统非结构化的随机稀疏化会带来不规则的内存访问,因此在GPU等硬件平台上无法有效的进行加速。 作者在网络的目标函数上增加了group lasso的限制项,可以实现filter级与channel级以及shape级稀疏化。所有稀疏化的操作都是基于下面的loss func进行的,其中Rg为group lasso: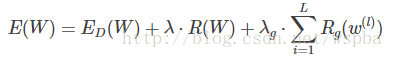
则filter-channel wise:
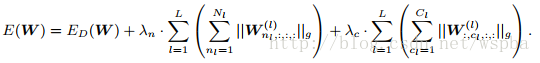
而shape wise:
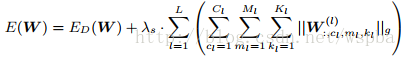
由于在GEMM中将weight tensor拉成matrix的结构,因此可以通过将filter级与shape级的稀疏化进行结合来将2D矩阵的行和列稀疏化,再分别在矩阵的行和列上裁剪掉剔除全为0的值可以来降低矩阵的维度从而提升模型的运算效率。该方法是regular的方法,压缩粒度较粗,可以适用于各种现成的算法库,但是训练的收敛性和优化难度不确定。
B. Dynamic Network Surgery for Efficient DNNs
作者提出了一种动态的模型裁剪方法,包括以下两个过程:pruning和splicing,其中pruning就是将认为不中要的weight裁掉,但是往往无法直观的判断哪些weight是否重要,因此在这里增加了一个splicing的过程,将哪些重要的被裁掉的weight再恢复回来,类似于一种外科手术的过程,将重要的结构修补回来,它的算法如下:

作者通过在W上增加一个T来实现,T为一个2值矩阵,起到的相当于一个mask的功能,当某个位置为1时,将该位置的weight保留,为0时,裁剪。在训练过程中通过一个可学习mask将weight中真正不重要的值剔除,从而使得weight变稀疏。由于在删除一些网络的连接,会导致网络其他连接的重要性发生改变,所以通过优化最小损失函数来训练删除后的网络比较合适。
优化问题表达如下: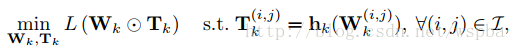
参数迭代如下:
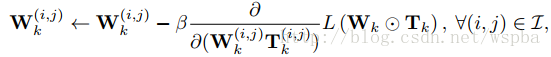
其中用于表示网络连接的重要性 h 函数定义如下:
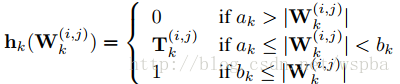
该算法采取了剪枝与嫁接相结合、训练与压缩相同步的策略完成网络压缩任务。通过网络嫁接操作的引入,避免了错误剪枝所造成的性能损失,从而在实际操作中更好地逼近网络压缩的理论极限。属于irregular的方式,但是ak和bk的值在不同的模型以及不同的层中无法确定,并且容易受到稀疏矩阵算法库以及带宽的限制。
C. Training Skinny Deep Neural Networks with Iterative Hard Thresholding Methods
作者想通过训练一个稀疏度高的网络来降低模型的运算量,通过在网络的损失函数中增加一个关于W的L0范式可以降低W的稀疏度,但是L0范式就导致这是一个N-P难题,是一个难优化求解问题,因此作者从另一个思路来训练这个稀疏化的网络。算法的流程如下:

先正常训练网络s1轮,然后Ok(W)表示选出W中数值最大的k个数,而将剩下的值置为0,supp(W,k)表示W中最大的k个值的序号,继续训练s2轮,仅更新非0的W,然后再将之前置为0的W放开进行更新,继续训练s1轮,这样反复直至训练完毕。 同样也是对参数进行诱导的方式,边训练边裁剪,先将认为不重要的值裁掉,再通过一个restore的过程将重要却被误裁的参数恢复回来。也是属于irregular的方式,边训边裁,性能不错,压缩的力度难以保证。
总结
以上三篇文章都是基于核稀疏化的方法,都是在训练过程中,对参数的更新进行限制,使其趋向于稀疏,或者在训练的过程中将不重要的连接截断掉,其中第一篇文章提供了结构化的稀疏化,可以利用GEMM的矩阵操作来实现加速。第二篇文章同样是在权重更新的时候增加限制,虽然通过对权重的更新进行限制可以很好的达到稀疏化的目的,但是给训练的优化增加了难度,降低了模型的收敛性。此外第二篇和第三篇文章都是非结构化的稀疏化,容易受到稀疏矩阵算法库以及带宽的限制,这两篇文章在截断连接后还使用了一个surgery的过程,能够降低重要参数被裁剪的风险。之后还会对其他的模型压缩方法进行介绍。
知识应该是开源的,欢迎斧正,929994365@qq.com
参考文献:大佬博客

 浙公网安备 33010602011771号
浙公网安备 33010602011771号