终端移植
十岁的小男孩
未来,All In AI。IT三分天下,算法、算力和终端。
本文终端移植方向,助力AI落地。该方向的矛盾在于资源和性能的平衡,即在有限的资源下使性能最大化。本文意在将学习过程中遇到的知识点进行总结,试图构建一个简单的框架,各章节将独起博文,也意抛砖引玉,希望大佬们将知识点完善,知识应该是开源的。
该方向主要分理论和工程两部分,即模型优化和模型移植,前者为理论支撑,主要在时间和空间两个维度进行优化;后者现阶段通过移植框架在终端运行,框架百花齐放,百家争鸣;后文摘录当前较流行的几个开源框架,本文试图权衡这些框架之间的优劣,其后海纳百川。
1. 模型优化
1.1模型压缩
通常意义上的网络模型压缩,主流思路有两个方向,一个是一个是设计更小的网络模型,即重构;另外一种思路是网络模型结构不变,对模型进行精简。
1.1.1 重构
重构包括迁移学习和更轻量级网络模型设计,如SqueezeNet,MobileNet,ShuffleNet等,可以根据实际精度要求,不断裁剪模型,调试优化。
1. 迁移学习
2. 轻量化模型设计
Squeeze-Net、Mobile-Net、Shuffle-Net、X-ception
1.1.2 精简
通过一定方法减小网络带宽,内存开销,提升速度,主要基于目前多数网络模型存在大量冗余节点,节点权重存在占位浪费等原因,做一定算法实现层面的加速优化。
1. 参数裁剪与共享
2. 低秩分解和稀疏性
1.2 优化加速
1.2.1 Op-level的快速算法
FFT Conv2d (7x7, 9x9)、 Winograd Conv2d (3x3, 5x5)
1.2.2 Layer-level的快速算法
Sparse Block Net
1.2.3 优化工具库
TensorRT (Nvidia) 、Tensor Comprehension (Facebook) 、Distiller (Intel)
1.2.4 BNN
1.3 异构计算
X-PU(CPU、GPU、TPU、NPU。。)
1.4 AUTO
1.4.1 PocketFlow
1.4.2 AutoML
1.4.3 AutoKears
1.4.4 TensorFlow
2. 模型移植
2.1 TensorFlow Lite
2.2 Mace
2.2.1 环境搭建
2.2.2 模型编译
2.2.3 工程化
2.3 Tengine
2.4 NCNN
2.5 QNNPACK
2.6 OpenCV
背景
为了解决全连接层参数规模的问题,人们转而考虑增加卷积层,使全连接参数降低。随之带来的负面影响便是大大增长了计算时间与能耗。
现代卷积神经网络主要由两种层构成,他们具有不一样的属性和性能:
- 卷积层,占据了90% ~ 95%的计算量,5%的参数,但是对结果具有很大的表达能力。
- 全连接层,占据了5% ~ 10%的计算量,95%的参数,但是对于结果具有相对较小的表达的能力。
综上:卷积层计算量大,所需参数系数 W 少,全连接层计算量小,所需参数系数 W 多。因此对于卷积层适合使用数据并行,对于全连接层适合使用模型并行。
一个典型的例子是具有50个卷积层的ResNet-50需要超过 95MB的存储器以及38亿次浮点运算。在丢弃了一些冗余的权重后,网络仍照常工作,但节省了超过75%的参数和50%的计算时间。
研究现状
这里所谓的模型压缩,主要是指第二种,即网络结构基本不变,做模型压缩。主要从以下几个方面进行压缩:
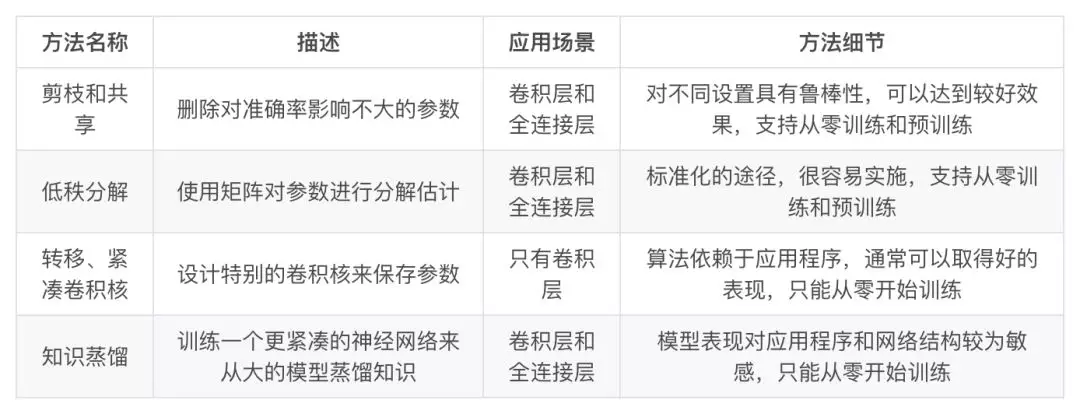
模型裁剪,权重共享,核稀疏(正则),量化,二值化,Low-rank分解,知识蒸馏等方向,下图是Distiller实现的几种方案。
- 参数修剪和共享(parameter pruning and sharing):针对模型参数的冗余性,试图去除冗余和不重要的项。
- 低秩因子分解(low-rank factorization):使用矩阵/张量分解来估计深度学习模型的信息参数。
- 转移/紧凑卷积滤波器(transferred/compact convolutional filters):设计了特殊的结构卷积滤波器来降低存储和计算复杂度。
- 知识蒸馏(knowledge distillation):通过学习一个蒸馏模型,训练一个更紧凑的神经网络来重现一个更大的网络的输出。
参数修剪和共享、低秩分解和知识蒸馏方法可以用于全连接层和卷积层的CNN,但另一方面,使用转移/紧凑型卷积核的方法仅支持卷积层(因为只是修改卷积filter)。
低秩因子分解和基于转换/紧凑型卷积核的方法提供了一个端到端的流水线,可以很容易地在 CPU/GPU 环境中实现。
参数修剪和共享使用不同的方法,如矢量量化,二进制编码和稀疏约束来执行任务,这导致常需要几个步骤才能达到目标。
关于训练协议,基于参数修剪/共享、低秩分解的模型可以从预训练模型或者从头开始训练,因此灵活而有效。然而转移/紧凑的卷积核和知识蒸馏模型只能支持从零开始训练。
这些方法是独立设计和相辅相成的。例如,转移层和参数修剪和共享可以一起使用,并且模型量化和二值化可以与低秩近似一起使用以实现进一步的加速。
挑战
深度模型的压缩和加速技术还处在早期阶段,目前还存在以下挑战:
-
依赖于原模型,降低了修改网络配置的空间,对于复杂的任务,尚不可靠;
-
通过减少神经元之间连接或通道数量的方法进行剪枝,在压缩加速中较为有效。但这样会对下一层的输入造成严重的影响;
-
结构化矩阵和迁移卷积滤波器方法必须使模型具有较强的人类先验知识,这对模型的性能和稳定性有显著的影响。研究如何控制强加先验知识的影响是很重要的;
-
知识精炼方法有很多优势,比如不需要特定的硬件或实现就能直接加速模型。个人觉得这和迁移学习有些关联。
-
多种小型平台(例如移动设备、机器人、自动驾驶汽车)的硬件限制仍然是阻碍深层 CNN 发展的主要问题。相比于压缩,可能模型加速要更为重要,专用芯片的出现固然有效,但从数学计算上将乘加法转为逻辑和位移运算也是一种很好的思路。
知识应该是开源的,欢迎斧正。929994365@qq.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号