Apache Flink:(一) Flink的主要特点及快速上手WordCount
最近公司上了一个改造项目,本来想用SparkStreaming来解决,但是公司的另一个小伙伴说,上flink吧!
好!就这定了,于是开启了本系列的Flink学习之路。
感谢尚硅谷的开放课程,在此表示最诚挚的敬意!感谢大佬!
Flink简介

Flink 项目的理念是:“Apache Flink 是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架”。
Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink 被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
是目前为止,最接近 Google DataFlow 模型的实现。
Flink的主要特点
- 事件驱动(Event-driven)
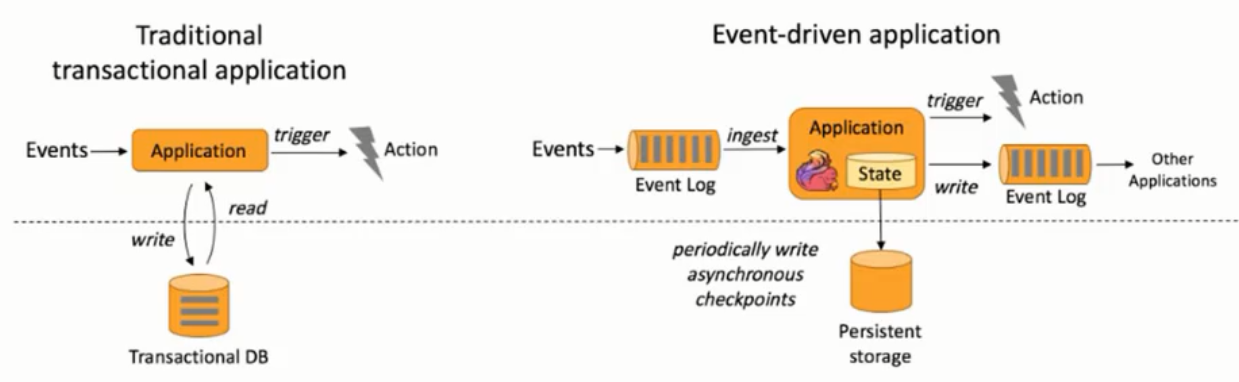
- 基于流的世界观
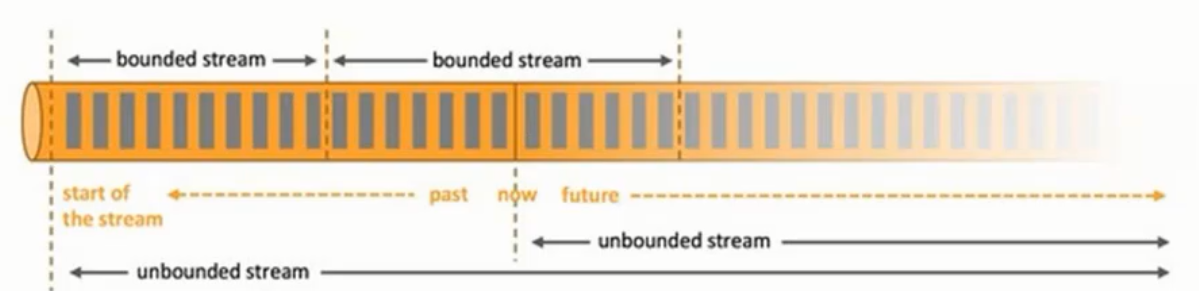
在大数据的计算中,一般可分为批处理和流处理两大类。但在flink的设计中,一起数据都是由流组成的,只是离线数据是有界的流(批处理),实时数据是一个没有界限的流。这就是所谓的有界流和无界流。
注:在spark的设计中,是基于批的世界观,流也是批,只不过是很小的批。
这种以流为世界观的架构,获得的最大好处就是具有极低的延迟。
无界数据流: 无界数据流有一个开始但是没有结束,它们不会在生成时终止并
提供数据,必须连续处理无界流,也就是说必须在获取后立即处理 event。对于无界数据流我们无法等待所有数据都到达,因为输入是无界的,并且在任何时间点都不会完成。处理无界数据通常要求以特定顺序(例如事件发生的顺序)获取 event,以便能够推断结果完整性。
有界数据流: 有界数据流有明确定义的开始和结束,可以在执行任何计算之前
通过获取所有数据来处理有界流,处理有界流不需要有序获取,因为可以始终对有界数据集进行排序,有界流的处理也称为批处理。 - 分层API
越顶层越抽象,表达含义越简明,使用月方便
越底层越具体,表达能力越丰富,使用越灵活

最底层级的抽象仅仅提供了有状态流,它将通过过程函数(Process Function) 被嵌入到 DataStream API 中。底层过程函数( Process Function) 与 DataStream API 相集成,使其可以对某些特定的操作进行底层的抽象,它允许用户可以自由地处理来自一个或多个数据流的事件,并使用一致的容错的状态。除此之外,用户可以注册事件时间并处理时间回调,从而使程序可以处理复杂的计算。
DataStream API( 有界或无界流数据) 以及 DataSet API(有界数据集)。这些 API 为数据处理提供了通用的构建模块, 比如由用户定义的多种形式的转换( transformations),连接( joins),聚合( aggregations),窗口操作( windows) 等等。DataSet API 为有界数据集提供了额外的支持, 例如循环与迭代。这些 API 处理的数据类型以类( classes)的形式由各自的编程语言所表示。
Table API 是以表为中心的声明式编程,其中表可能会动态变化(在表达流数据时)。Table API 遵循( 扩展的)关系模型:表有二维数据结构( schema)( 类似于关系数据库中的表),同时 API 提供可比较的操作,例如 select、project、join、group-by、aggregate 等。Table API 程序声明式地定义了什么逻辑操作应该执行,而不是准确地确定这些操作代码的看上去如何。
尽管 Table API 可以通过多种类型的用户自定义函数( UDF)进行扩展,其仍不如核心 API 更具表达能力,但是使用起来却更加简洁(代码量更少)。除此之外, Table API 程序在执行之前会经过内置优化器进行优化。
你可以在表与 DataStream/DataSet 之间无缝切换,以允许程序将 Table API 与DataStream 以及 DataSet 混合使用。但目前还不是很成熟,DataStream API 仍然是目前为止使用最多的部分。更多的是使用其做流处理
Flink 提供的最高层级的抽象是 SQL 。这一层抽象在语法与表达能力上与Table API 类似,但是是以 SQL 查询表达式的形式表现程序。SQL 抽象与 Table API 交互密切,同时 SQL 查询可以直接在 Table API 定义的表上执行。
在最底层的api中,可以访问到流的事件、状态、时间等。。。
在使用久了以后就会发现,不管什么时候,都是可以用一个ProcessFunction来解决的。。。
- 支持多种时间语义
Event Time:事件时间,即数据自带的时间戳
Process Time:处理时间,事件被处理时机器的系统时间,与机器相关
Ingestion Time:事件进入 Flink 的时间
5.Exactly Once的状态一致性保证
6.低延迟大吞吐量
每秒可处理数百万个事件,毫秒级延迟
7.其他
与众多存储系统连接
高可用
动态扩展
可7*24小时运行
flink与SparkStreaming的对比
流(stream)和微批(micro-batching)
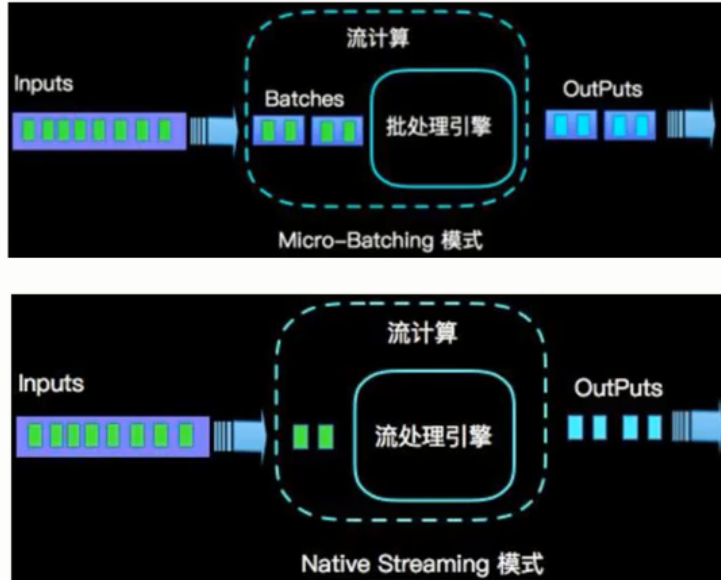
数据模型
- spark采用的是RDD的模型,SparkStreaming的DStream实际上也是一组小批数据RDD的集合
- flink基本数据模型是数据流,以及事件(Event)序列
故一般称SparkStreaming是微批处理,准实时
运行时架构 - spark是批计算,将DAG划分为不同的stage,一个完成后才可计算下一个
- flink是标准的流执行模式,一个事件在一个节点处理完之后可以直接发往下一个节点进行处理
快速上手WordCount程序
pom文件中,引flink即可,在此不做细致说明了,maven插件略
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.7.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.7.2</version>
</dependency>
</dependencies>
批处理的WordCount
//涉及到隐式转换
import org.apache.flink.api.scala._
// 批处理代码
/**
* flink的分层api中,在中间那层
*/
object BatchDataSetWordCount {
def main(args: Array[String]): Unit = {
// 创建一个批处理的执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 从文件中读取数据
val inputPath = "E:\\WorkSpace\\0_top_project\\AggregationProject\\xdf_flink\\src\\main\\resources\\wc_data.txt"
val inputDataSet = env.readTextFile(inputPath)
// 分词之后做count
val wordCountDataSet = inputDataSet.flatMap(_.split(" "))
.map( (_, 1) ) //
//Spark中可用reduceBykey,但flink中只有reduceBy,groupBy,没有groupByKey
.groupBy(0) //用int型数字标志用啥groupBy;.groupBy(_._1)亦可
.sum(1) //相当于用第二个字段进行sum 其实此处也可以传string(字段的名字),Fuc(函数)
// 打印输出
wordCountDataSet.print()
}
}
流处理的WordCount
流处理可以对接多种数据源,此处以最简单的netcat手动发送来示例
import org.apache.flink.api.java.utils.ParameterTool
//涉及隐式转换
import org.apache.flink.streaming.api.scala._
/**
* 使用在cmd中使用nc -lk 7777的形式在本地的7777端口启动一个socket接口,可以输入数据
*/
object StreamWordCount {
def main(args: Array[String]): Unit = {
// 这是org.apache.flink.api.java.utils;也可不用,直接接受args的参数也可,这种方式可以解析 --host localhost --port 7777的参数
val params = ParameterTool.fromArgs(args)
val host: String = params.get("host")
val port: Int = params.getInt("port")
// 创建一个流处理的执行环境,注意环境不同!!!此处为流的环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// env.setParallelism(1)
// env.disableOperatorChaining()
// 接收socket数据流
val textDataStream = env.socketTextStream(host, port)
// 逐一读取数据,分词之后进行wordcount
val wordCountDataStream = textDataStream.flatMap(_.split("\\s"))
.filter(_.nonEmpty).startNewChain()
.map( (_, 1) )
// flink的DataStream api中,无groupby,要用keyBy
.keyBy(0)
.sum(1)
// 打印输出.setParallelism(1)指定的并行度,下面的输出的3,2其实就是执行在哪个线程上执行。开发环境中默认并行度是当前电脑的CPU核数
wordCountDataStream.print().setParallelism(3)
/*
输出为:
3> (hello,1)
2> (world,1)
前面的数字代表的是任务的并行度,或者是任务执行在哪个线程上
*/
// 执行任务,程序的真正执行
env.execute("stream word count job")
}
}
测试时,Windows本使用在cmd中使用nc -lk 7777的形式在本地的7777端口启动一个socket接口,可以输入数据.-l相当于启动一个server,-k表示保持一个状态,可以被多个连接打开。若不加k,一个连接销毁时,nc的这个连接也退出了
集群测试请见下篇
