Python:多线程及多进程的使用-Threading and multiprocessing
进程:由程序,数据集,进程控制块三部分组成,它是程序在数据集上的一次运行过程。如果同一段程序在某个数据集上运行了两次,那就是开启了两个进程。进程是资源管理的基本单位。在操作系统中,每个进程有一个地址空间,而且默认就有一个控制进程。
线程:是进程的一个实体,是CPU调度和分派的基本单位,也是最小的执行单位。它的出现降低了上下文切换的消耗,提高了系统的并发性,并克服了一个进程只能干一件事的缺陷。线程由进程来管理,多个线程共享父进程的资源空间。
进程和线程的关系:
一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。
资源分配给进程,同一进程的所有线程共享该进程的所有资源。
CPU分给线程,即真正在CPU上运行的是线程。
线程的工作方式:
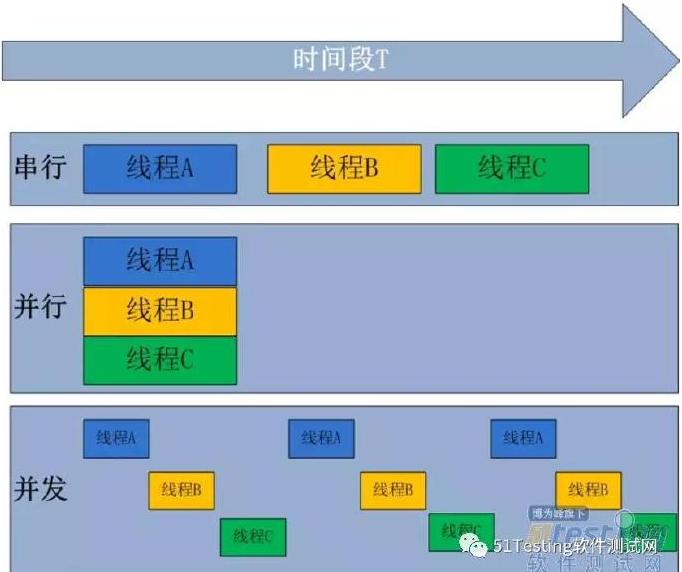
如下图所示,串行指线程一个个地在CPU上执行;并行是在多个CPU上运行多个线程;而并发是一种“伪并行”,一个CPU同一时刻只能执行一个任务,把CPU的时间分片,一个线程只占用一个很短的时间片,然后各个线程轮流,由于时间片很短所以在用户看来所有线程都是“同时”的。并发也是大多数单CPU多线程的实际运行方式。
多线程:单核多线程
import threading # 导入threading模块,为多线程非多进程,一个核来跑
from queue import Queue #导入queue模块
import pyhdfs
import pandas as pd
import os
import datetime
import time
prov_id_list = ["010", '011','013'] # 要循环的省份
def runProvDelay(prov_id,queue):
"""主程序"""
print(f"---------------当前省份为{prov_id}-------------------------")
# 向队列(共享变量)中写入数据
queue.put((xxx,xxx))
if __name__ == '__main__':
start_time = time.time()
file_time_list_queue = Queue(maxsize=100) # 用Queue构造一个大小为1000的线程安全的先进先出队列
# 先创造多个线程
prov_thread = []
for prov_id in prov_id_list:
thread = threading.Thread(target=runProvDelay, args=(prov_id,file_time_list_queue)) # 方法名不可加括号,参数全部写在args中
prov_thread.append(thread)
# 启动多个线程,但实际并行度被核的性能限制
for thread in prov_thread:
thread.start()
# 等待所有线程结束,thread.join()函数代表子线程完成之前,其父进程一直处于阻塞状态。
for thread in prov_thread:
thread.join()
prov_time_list = []
while (file_time_list_queue.empty()==False):
prov_time = file_time_list_queue.get() #Queue队列的get方法用于从队列中提取元素
prov_time_list.append(prov_time)
print(prov_time_list)
df_file_time_list = pd.DataFrame(file_time_list)
print("df_file_time_list: %s" % df_file_time_list)
print("last time: {} s".format(time.time() - start_time))
多进程:多核多进程
以并行读取hdfs文件并分析为例
from multiprocessing import Process,Queue # 多进程多个核,Queue用于做共享变量
import pyhdfs
import pandas as pd
import os
import datetime
import time
file_time_list_queue = Queue() # 共享变量,可在各进程间随时写入和读取
fs = pyhdfs.HdfsClient(hosts=['10.162.166.178', '10.162.166.179'], user_name='ubd_oy')
fs.get_active_namenode() # 返回可用的namenode节点
# fs.get_home_directory()#返回这个用户的根目录
start = datetime.datetime.now()
prov_id_list = ['010', '011', '013'] # 循环的省份
def runProvDelay(prov_id,queue):
"""主程序"""
print(f"---------------当前省份为{prov_id}-------------------------")
# 往queue中写入数据
queue.put((xxx,xxx))
def main(prov_id_list):
prov_thread = []
for prov_id in prov_id_list:
# 将队列传过去,做共享变量使用
th = Process(target=runProvDelay, args=(prov_id,file_time_list_queue,))
th.start()
prov_thread.append(th)
for thread in prov_thread:
thread.join()
# 在主进程中将队列中的数据拿出来放到list里,便于处理
prov_time_list = []
while (file_time_list_queue.empty() == False):
prov_time = file_time_list_queue.get() # Queue队列的get方法用于从队列中提取元素
prov_time_list.append(prov_time)
print(prov_time_list)
df_file_time_list = pd.DataFrame(prov_time_list)
# df_file_time_list.rename( columns={0: 'prov_id', 1: 'start_time_min',2:'start_time_max',3:'start_time_avg',4:'insert_time',5:'check_time'},inplace=True)
df_file_time_list.rename(
columns={0: 'prov_id', 1: 'start_time_min', 2: 'start_time_max', 3: 'insert_time', 4: 'check_time'},
inplace=True)
print("df_file_time_list: %s" % df_file_time_list)
# end = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
end = datetime.datetime.now()
print("start: %s" % start)
print("end: %s" % end)
print("all_time: %s" % (end - start))
if __name__ == '__main__':
# 执行
main(prov_id_list)
