YOLO
全名
You Only Look Once: Unified, Real-Time Object Detection
代码地址
参考
https://www.jianshu.com/p/13ec2aa50c12
Abstract
我们将对象检测定义为一个回归问题(什么叫做回归问题?),用于空间分离边界框和相关的类概率。单个神经网络直接从完整图像预测边界盒和类概率。由于整个检测管道是一个单一的网络,可以直接从检测性能上进行端到端优化。
我们的基本YOLO模型以每秒45帧的速度实时处理图像。一个更小版本的网络,Fast YOLO,处理速度达到惊人的每秒155帧。
1.Introduction

图1
处理过程:
- 首先将输入图像的大小调整为448×448
- 在图像上运行单个卷积网络
- 通过模型的置信度对结果进行阈值检测。
YOLO模型优点:
- YOLO非常快。因为我们将检测作为一个回归问题,所以我们不需要复杂的pipeline。
- 在进行预测时,YOLO对图像进行全局推理。
- YOLO学习对象的泛化表示
YOLO模型缺点:
YOLO在准确性方面仍然落后于最先进的检测系统。虽然它可以快速识别图像中的对象,但它很难精确定位某些对象,尤其是小对象。
2.Unified Detection(统一检测)
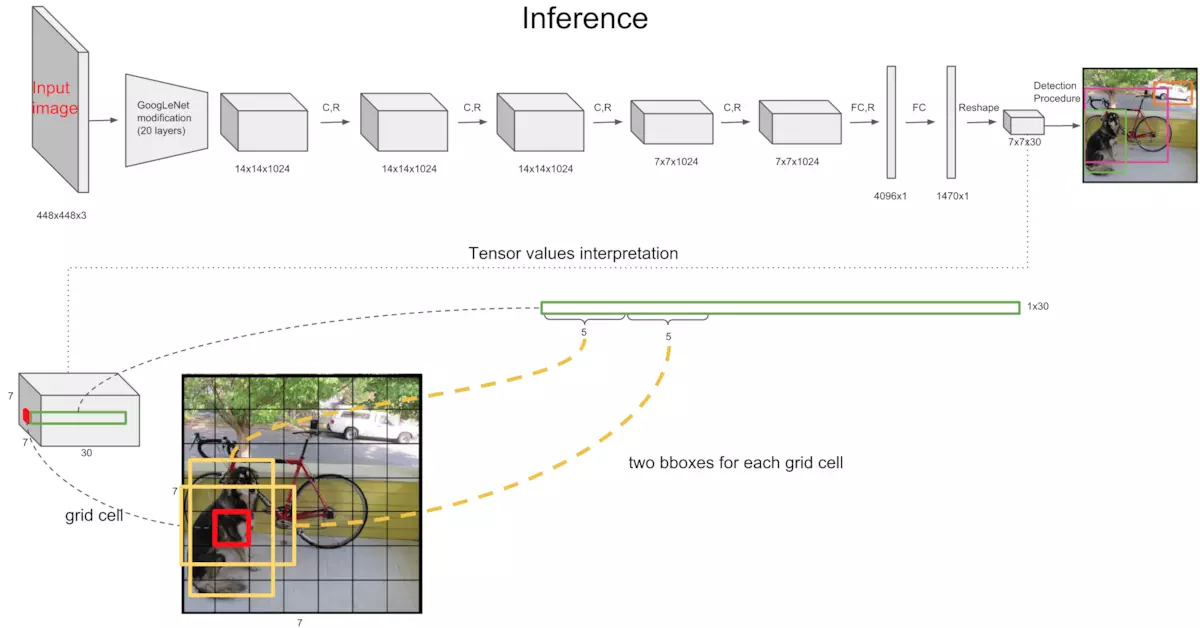
图2
系统将输入图像分割成S×S网格(原文S=7)。如果一个物体的中心落在一个网格单元中,该网格单元负责检测该物体。
每个网格单元格预测:
- B个边界框(原文中B=2,参见图2中单元格中的两个框。边界框的预测包括坐标和宽高)和这些框的置信度分数,因此每个单元格预测Bx(4+1)个值。
- C个(物体种类个数)条件类概率Pr(Classi|Object)。这些概率以包含对象的网格单元为条件。
我们只预测每个网格单元的一组分类概率,而不考虑框B的数量。
这些预测被编码为S×S×(B∗5+C)张量。(张量解释)
定义置信度:

如果该单元格中不存在对象,则置信度分数应为零。否则,我们希望置信度分数等于预测框和基本事实之间的IOU。
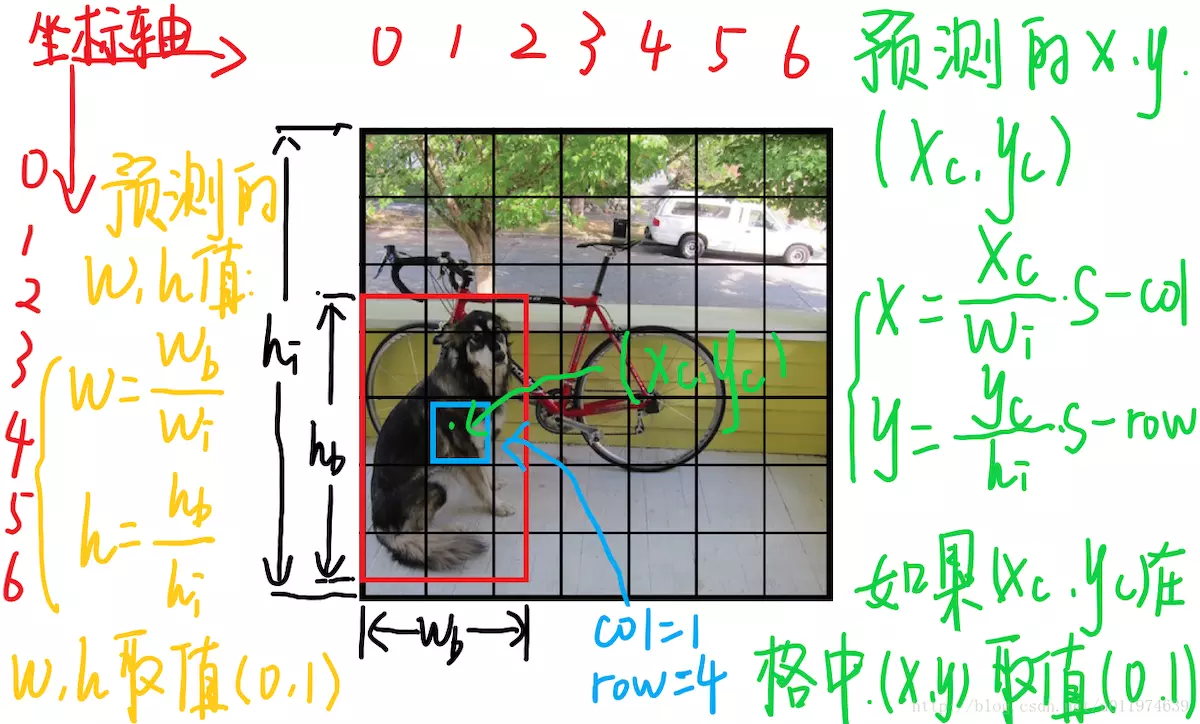
图三
每个边界框包含5个预测:x、y、w、h和置信度。相对于网格单元格的边界,(x, y)坐标表示框的中心。宽度和高度是相对于整个图像预测的,参见图3。
每个网格单元还预测C个条件类概率Pr(Classi|Object)。这些概率以包含对象的网格单元为条件。
在测试时,我们将条件类概率和各个框置信度预测相乘:

这给了我们每个盒子特定类的置信度分数。这些分数既编码了该类出现在框中的概率,也编码了预测框与对象的匹配程度。

2.1.Network Design
网络的初始卷积层从图像中提取特征,全连接层预测输出的概率和坐标。
我们的网络架构受到了GoogLeNet图像分类模型的启发。
我们的网络有24个卷积层,然后是2个全连接层。
我们不使用GoogLeNet的inception模块,而是简单地使用1×1reduction层(reduction层介绍)和3×3卷积层。

我们的检测网络有24个卷积层,然后是2个全连接层。交替的1×1卷积层减少了前一层的特征空间。我们在ImageNet分类任务中以一半的分辨率(224×224输入图像)对卷积层进行预训练,然后将检测的分辨率提高一倍。我们的网络的最终输出是预测的7×7×30张量。
2.2. Training
对预训练,我们使用上图中的前20个卷积层,然后是1个平均池化层和1个全连接层。
然后将模型转换为执行检测。Ren等人的研究表明,将卷积层和连接层都加入到预先训练的网络中可以提高性能。
按照他们的例子,我们添加了4个卷积层和2个全连接层,它们的权值是随机初始化的。
检测时我们将网络输入的分辨率从224×224提高到448×448。
Detection often requires fine-grained visual information so we increase the input resolution of the network from 224 × 224 to 448 × 448.
最后一层预测类概率和边界框坐标。我们使用图像宽度和高度来归一化边界框的宽度和高度,使它们落在0和1之间。将边界框的x和y坐标参数化为特定网格单元位置的偏移量,以便它们也在0和1之间。
对最终层使用线性激活函数,所有其他层均使用以下leaky rectified linear激活:

我们对模型输出的平方和误差进行了优化。我们使用平方和误差是因为它很容易优化,但是它并不完全符合我们最大化平均精度(maximizing average precision)的目标。它将定位误差与可能不理想的分类误差同等加权。此外,在每个图像中,许多网格单元都不包含任何对象。这会将这些单元格的“置信度”分数推向零,通常会压倒确实包含对象的单元格的梯度。这可能会导致模型不稳定,导致早期训练出现分歧。
为了解决这个问题,我们增加了边界框坐标预测的损失,并减少了不包含对象的框的置信度预测的损失。
我们使用两个参数,λcoord和λnoobj来实现这一点,λcoord=5和λnoobj=0.5。
平方和误差在大方框和小方框中的权重也是相等的。我们的误差度量应该反映出大盒子里的小偏差比小盒子里的小偏差更重要。为了部分解决这个问题,我们预测边界框宽度和高度的平方根,而不是直接预测宽度和高度。
YOLO在每个网格单元格预测多个边界框。在训练时,我们只希望一个边界框预测器负责每个对象。哪一个预测与真值框具有当前最高的IOU,我们就指定一个预测器来“负责”预测一个对象。
在训练过程中,我们优化了以下多个部分:

其中,![]() 表示对象是否出现在单元格i中。
表示对象是否出现在单元格i中。![]() 表示单元格i中第j个边界框预测器负责该预测。
表示单元格i中第j个边界框预测器负责该预测。
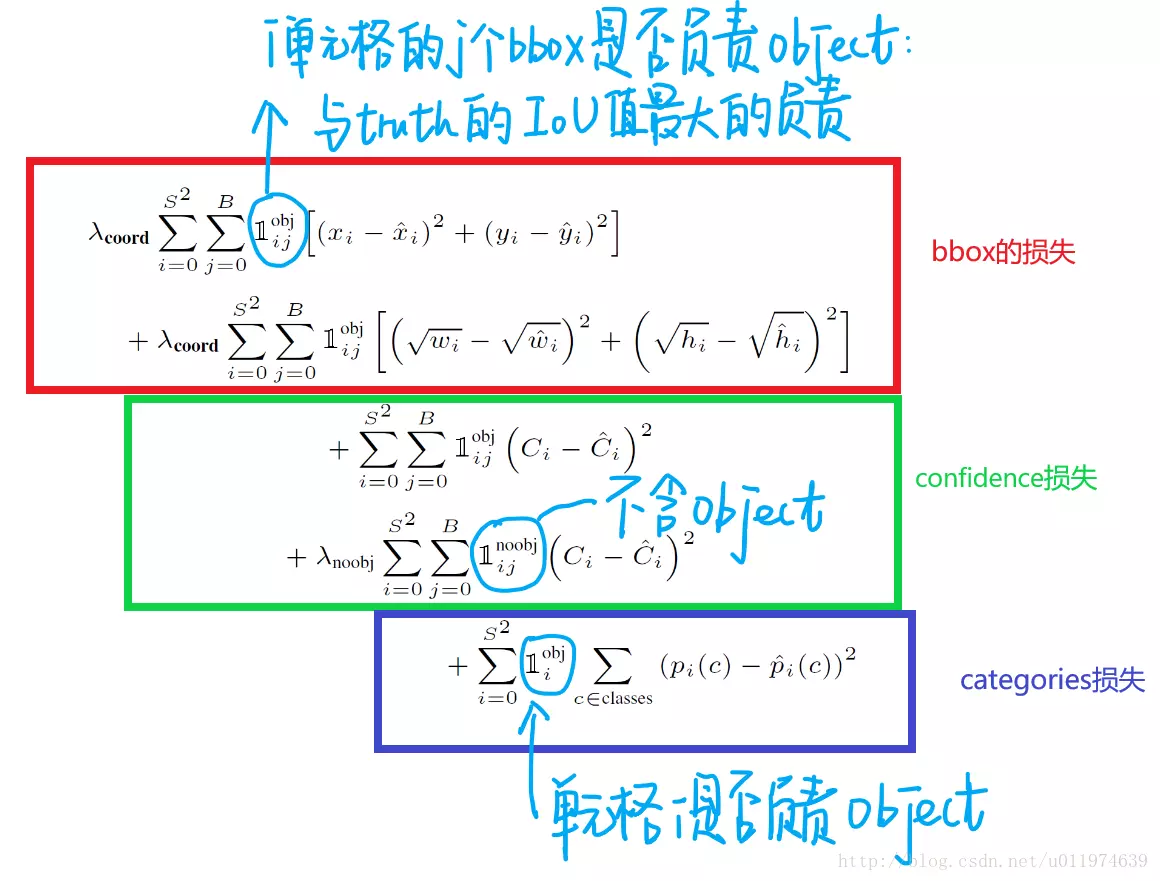
损失函数仅在该网格单元中存在对象的情况下惩罚分类错误(因此是前面讨论的条件类概率)。如果预测器对真值框“负责”(即在该网格单元中具有任何预测器中最高的IOU),则它也仅惩罚边界框坐标错误。
在整个训练过程中,我们使用批处理大小为64,动量为0.9,衰减为0.0005。
我们的学习速率如下:
在第一个阶段,我们缓慢地将学习速率从10−3提高到10−2。如果我们从一个高的学习率开始,我们的模型经常由于不稳定的梯度而发散。我们继续以10-2训练75个epochs,然后以10-3训练30个epochs,最后以10-4训练30个epochs。
为了避免过度拟合,我们使用了dropout和广泛的数据增强。在第一个连接层之后,速率为0.5的dropout层阻止了层之间的相互适应。为了数据增强,我们引入了随机缩放和高达原始图像大小20%的平移。我们还随机调整曝光和饱和度的图像高达1.5倍的HSV色彩空间。
2.4.Limitations of YOLO
- YOLO对边界框预测施加了很强的空间约束,因为每个网格单元只能预测两个框,并且只能有一个类。这种空间约束限制了我们的模型可以预测的附近对象的数量。我们的模型很难处理成群出现的小物体,比如成群的鸟。
- 由于我们的模型学习从数据中预测边界框,因此很难将其推广到具有新的或不寻常的纵横比或配置的对象。
- 我们的模型还使用相对粗糙的特征来预测边界框,因为我们的体系结构有来自输入图像的多个下采样层。
- 我们训练一个近似于检测性能的损失函数时,我们的损失函数对小边界框中的错误与大边界框中的错误处理相同。大盒子中的小错误通常是良性的,但小盒子中的小错误对IOU的影响要大得多。我们的主要错误来源是不正确的本地化。

