SSD: Single Shot MultiBox Detector
代码地址
https://github.com/weiliu89/caffe/tree/ssd
1、 Introduction
SSD取消了对边界框(bounding box)建议以及后续的像素或特征的重新采样,极大的提高了检测速度,并且准确率也可以保持一样。
改进的地方:
- 使用小型卷积过滤器来预测对象类别和边界框位置中的偏移量
- 使用单独的预测器(过滤器)进行不同的宽高比检测,以及将这些过滤器应用于网络后期的多个特征图,以便执行多尺度检测。
- 我们可以使用相对较低的分辨率输入来实现高精度,从而进一步提高检测速度。
贡献如下:
- SSD是一种用于多个类别的单镜头探测器,它比以前的单镜头探测器(YOLO)速度更快,而且更准确,实际上与执行显式区域建议和池(包括更快的R-CNN)的较慢技术一样准确。
-
SSD的核心是使用应用于特征图的小卷积过滤器来预测一组固定的默认边界框的类别分数和框偏移量。
-
为了实现较高的检测精度,我们从不同尺度的特征图中生成不同尺度的预测,并通过纵横比明确地分离预测。
-
这些设计特点可以实现简单的端到端训练和高精度,甚至在低分辨率的输入图像,进一步提高了速度与精度之间的权衡。
-
实验包括在PASCAL VOC、COCO和ILSVRC上对不同输入大小的模型进行定时和准确性分析,并与一系列最新的先进方法进行比较。
2、 The Single Shot Detector(SSD)
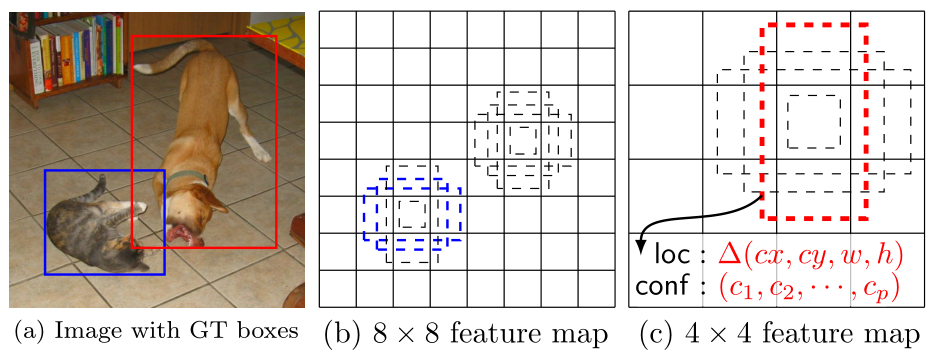
- (a)表明SSD在训练时只需要输入图片以及对应每个物体的真值框。
- (b)和(c)是两个不同的特征图。特征图上的每个单元有不同尺度的default box(虚线的框),Δ(cx,cy,w,h)分别表示default box的中心坐标以及宽高。
- (c)可以看出default box的输出是每个类别的location和confidence。
- 训练中还有一个东西:prior box,它是指实际过程中被选择的default box。
2.1、 Model
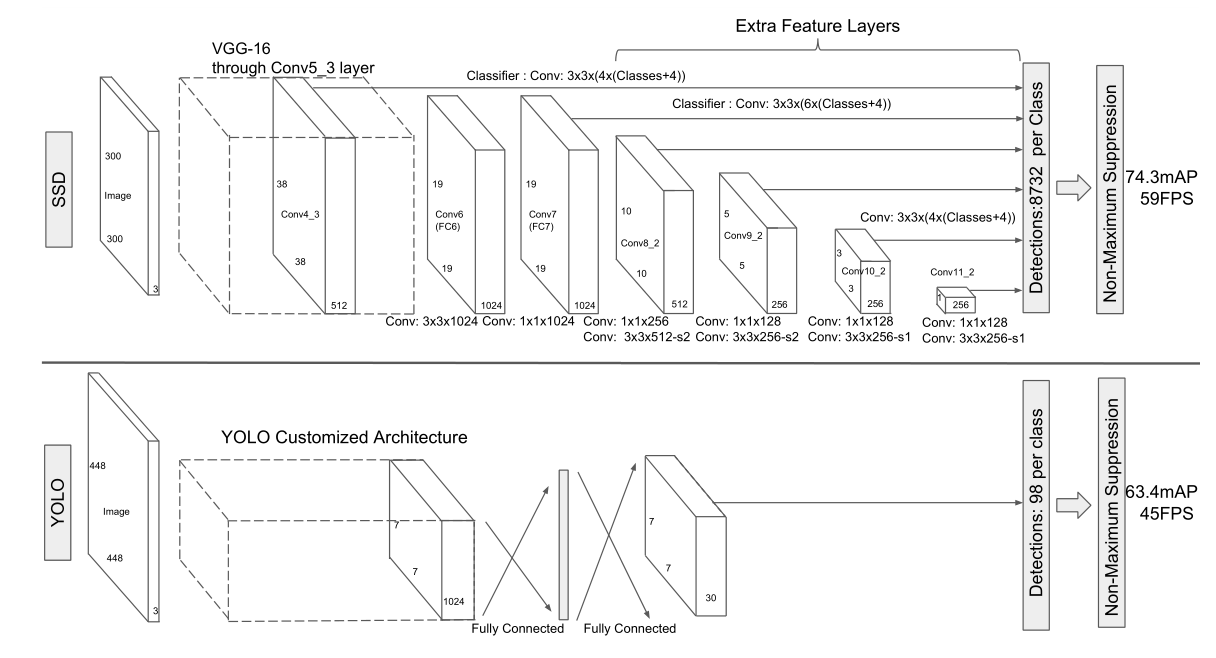
SSD方法基于一个前馈卷积网络,该网络生成一个固定大小的bounding box(边界盒)集合,并根据这些盒中对象类实例的存在程度进行评分,然后执行一个非最大抑制步骤,以产生最终的检测结果。早期的网络层基于用于高质量图像分类(在任何分类层之前截断)的标准体系结构,我们将其称为基础网络。然后在网络中加入辅助结构,产生以下关键特征的检测:
- 用于检测的多尺度特征图:
在截断的基本网络的最后,增加了卷积特征层。层的大小逐渐减小,可以在多个尺度上预测。每个特征层用于预测检测的卷积模型是不同的。
- 用于检测的卷积预测器:
每个增加的特征层(或者从基础网络中选择一个现有的特征层)可以使用一组卷积过滤器生成一组固定的检测预测。对于具有p通道的m×n大小的特征层,预测潜在检测参数的基本元素是一个3×3×p的小核,它可以生成一个类别的分数,也可以生成相对于默认框坐标的形状偏移量。在应用内核的每个m×n个位置上,它都产生一个输出值。边界框偏移量输出值是相对于每个feature map位置的默认框位置来测量的(参见YOLO[5]的架构,该架构使用一个中间的全连接层而不是卷积过滤器)。
- 默认框和宽高比:
对网络顶部的多个feature map,我们将一组默认的边界框与每个feature map单元关联起来。默认框以卷积方式平铺feature map,因此每个框相对于其相应单元格的位置是固定的。在每个feature map单元格中,我们预测相对于单元格中的默认框形状的偏移量,以及每个类的分数,这些分数表示每个框中存在一个类实例。默认框类似于Faster R-CNN中使用的anchor boxes,但是我们将它们应用于不同分辨率的几个feature map。允许在几个feature map中使用不同的默认框形状,可以有效地离散可能的输出框形状空间。
预测值和卷积核数量计算
假设每个feature map cell 有k个default box,对于一个m*n大小的feature map,就一共有m*n*k个default boxes。
假设预测c个类别(其实是一个背景加上c-1个类别),那么每个default box就要预测c个类别的score(得分)和4个offset(可以理解为四个坐标值,分别是中心坐标以及宽高)。
这样我们算一下有多少个预测值:
c个类别加上4个offset,就是(c+4)。每个单元的每个default box预测c+4个值,因为每个单元有k个default box,所以每个单元预测(c+4)*k个预测值。所有的单元预测值的个数就是m*n*k*(c+4)。
在代码中,SSD是分别用不同数量的3*3卷积核对一层feature map进行卷积,对于每个default box,其输出一套独立的检测值,对应一个边界框。检测值分为两个部分:每个类别的置信度(得分)和边界框的location(位置坐标)。对于置信度(confidence)的输出,所用到的卷积核数量是c。对于location的输出,所用到的卷积核数量是4。所以一个default box所用到的卷积核数量是(c+4),那么k个default box所用到的卷积核数量就是(c+4)*k。
2.2、 Training
训练SSD和训练一个使用region proposals的典型的检测器之间的关键区别在于:SSD 训练图像中的 ground truth 需要赋予到那些固定输出的 boxes 上。在前面也已经提到了,SSD 输出的是事先定义好的,一系列固定大小的 bounding boxes。
- 匹配策略
在训练过程中,根据default box的位置,长宽比和比例,我们将ground truth与对应的default box匹配。首先将每个ground truth与具有最佳jaccard重叠的default box进行匹配,只要阈值超过0.5就可以匹配。一个ground truth可能匹配多个default box。
- 训练目标
SSD训练目标源自MultiBox目标,但扩展到处理多个对象类别。让xpij= {1,0}作为将第i个default box与第j个类别p的ground truth进行匹配的指标,在上面的匹配策略中Σixpij≥1(一个ground truth可能匹配多个default box)。总体目标损失函数是位置损失(loc)和置信度损失(conf)的加权和: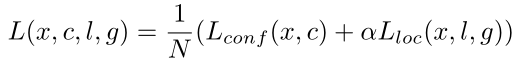
N:匹配的默认框的数量,如果N等于0,损失就为0。
l:预测框。
g:真值框。
定位损失就是l(预测框)和g(真值框)参数之间的Smooth L1损失。
我们回归默认边界框(d)的中心(cx,cy)以及它的宽(w)高(h)的偏移量。默认边界框就是算法跑出来的一个物体框:
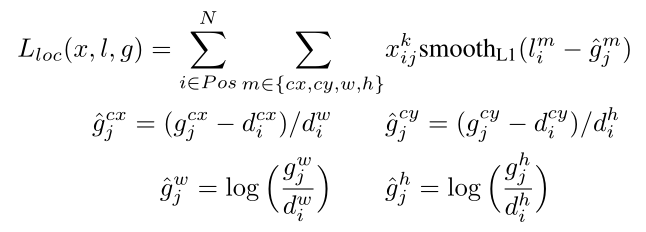
置信度损失多类置信度(c)上的softmax损失,通过交叉验证将权重项α设置为1:

- 选择默认框的比例和纵横比

从后面添加的卷积层中提取Conv7,Conv8_2,Conc9_2,Conv10_2,Conv11_2作为检测用的feature map,再加上Conv4_3层,一共就提取了6个feature map,6个feature map的大小分别是(38,38),(19,19),(10,10),(5,5),(3,3),(1,1)。
default box的设置包括scale和aspect ratio两个方面。
假设我们要用m个特征图(m在这里为5,因为第一层的Conv4_3是单独设置的)来预测。对每一个feature map而言,其default box的scale计算方式为:

Smin= 0.2,比例最小值。
Smax= 0.9,比例最大值
aspect ratio用ar表示。一共有五种aspect ratio:

每个default box的宽为:
![]()
每个default box的高为:
![]()
当aspect ratio为1时,作者还增加了一种scale的default box:
![]()
因此,对于每个feature map而言,一共有6种default box。
我们将每个default box的中心设置为:

其中|fk|是第k个feature map的大小,i, j∈[0,|fk|)。
- 难例挖掘
在匹配步骤之后,大多数default box都是负数,特别是在可能的default box数量很大的情况下。我们根据每个default box的最大置信度损失来排序,选择最高的那些,保持消极和积极的比例最多是3:1。
- 数据扩增
为了使模型对各种输入对象的大小和形状更加健壮,每个训练图像均通过以下选项之一随机采样:
- 使用整个原始输入图像。
- 采样一个patch,使jaccard与对象的最小重叠为0.1、0.3、0.5、0.7或0.9。
- 随机抽样一个patch。
每个采样的patch的尺寸是原始图像尺寸的0.1,长宽比在1/2和2之间。如果真值框的中心在采样patch中,我们就保留了它的重叠部分。在上述采样步骤之后,除了应用一些photo-metric distortions之外,每个采样的patch都被调整到固定的大小,并以0.5的概率水平翻转。
3、 实验结果
- 基本网络
- SSD是基于VGG16,它是在ILSVRC CLS-LOC数据集上预先训练的。
- 将fc6和fc7转换为卷积层,并从模型的 FC6、FC7 上的参数,进行采样得到这两个卷积层的 parameters。
- 将pool5从2×2−s2转换为3×3−s1,但是这样变化后,会改变感受野(receptive field)的大小。因此,采用了 atrous algorithm 的技术,这里所谓的 atrous algorithm,就是 hole filling algorithm。
- 删除了所有的dropout层和fc8层。
- 我们使用SGD对结果模型进行微调,initial learning rate为10−3,momentum,为0.9,weight decay为0.0005,batch size为32。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号