Linux如何在目录下灵活创建、浏览、删除百万个文件
一、创建百万级小文件
1、单核CPU情况
seq 1000000 |xargs -i dd if=/dev/zero of={}.data bs=1024 count=1 &> /dev/null
#生成一百万个大小为1KB、内容全为零的文件
seq 1000000 |xargs -i dd if=/dev/urandom of={}.data bs=1024 count=1 &> /dev/null
#生成一百万大小为1KB,内容为随机数据的文件
首先通过
seq 1000000生成从1到1000000的序列
|(管道符号): 将前面命令的输出作为后面命令的输入。
xargs: 是一个用于将输入行转换为命令行参数的工具。
-i: 选项告诉xargs将输入行中的占位符(默认是{})替换为输入行的内容。dd是一个强大的复制和转换数据的命令。
if=/dev/null:指定/dev/zero作为输入文件,这是一个无限量供应字节流的特殊文件,所有读取操作都会返回零值字节
if=/dev/urandom: 指定了输入文件为/dev/urandom,这是一个生成随机数的设备文件,可以提供随机数据。
of={}.data: 指定了输出文件的格式,其中{}会被seq生成的数字依次替换,形成如1.data、2.data这样的文件名
bs=1024: 设置每次读写的块大小为1024字节。
count=1: 指定只读写一次块,因此每个文件的大小是1KB。
>> /dev/null 2>&1: 这部分重定向了命令的所有输出(标准输出和错误输出)到/dev/null。这意味着不论是正常输出还是错误信息都不会显示在终端上。
2、多核CPU情况
seq 1000000 |xargs -i -P 0 dd if=/dev/zero of={}.data bs=1024 count=1 &> /dev/null
#生成一百万个大小为1KB、内容全为零的文件
seq 1000000 |xargs -i -P 0 dd if=/dev/urandom of={}.data bs=1024 count=1 &> /dev/null
#生成一百万大小为1KB,内容为随机数据的文件
-P 0选项指定了尽可能多地开启并发进程数量如果要保证最高效率,应当设置并发进程数量等于cpu的核心数量
3、执行效率对比
3.1、单核的顺序执行
time seq 1000 |xargs -i dd if=/dev/urandom of={}.data bs=1024 count=1 &> /dev/null

3.2、多核的并发执行
time seq 1000 |xargs -i -P 4 dd if=/dev/urandom of={}.data bs=1024 count=1 &> /dev/null

二、如何列出/浏览这些文件
1、查看目录下文件的数量
ls | wc -l

2、列出?
一般情况下我们会直接使用ls进行列出处理
ls
 |
|---|
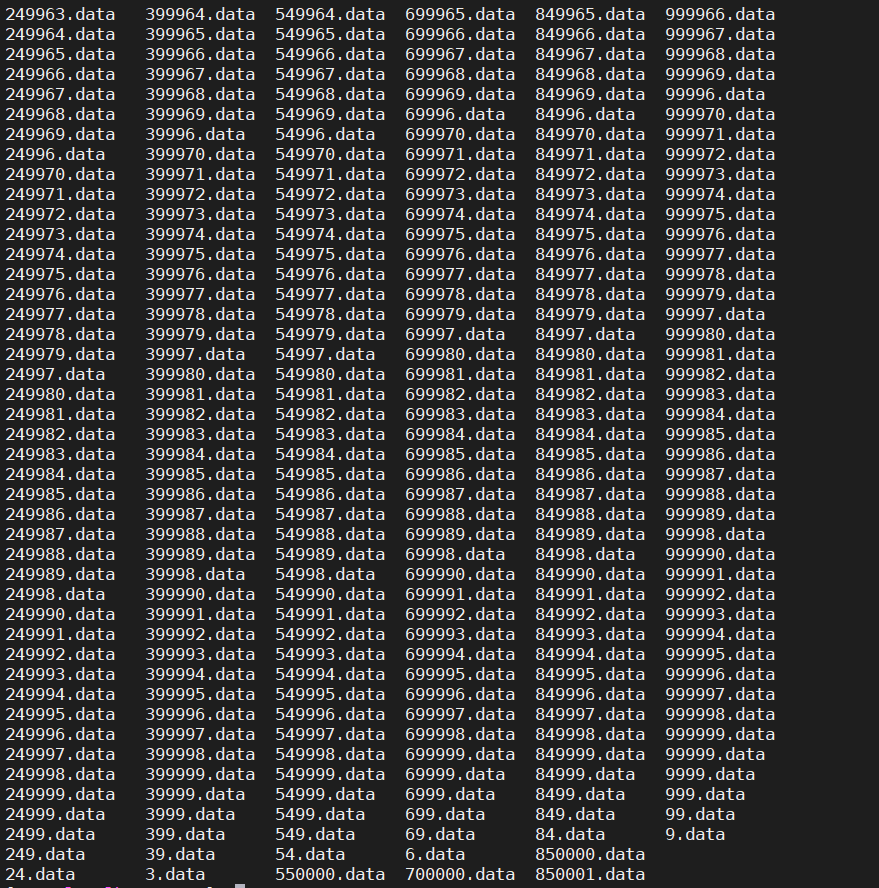 |
但是不难看出键入ls命令后终端会卡住
最后所有的文件名会一次性打印在终端的屏幕上
3、ls -f(关闭排序功能)
默认ls命令会在内存中对输出的文件进行排序
[root@localhost test]# man ls | grep -w "\-f"
-f do not sort, enable -aU, disable -ls --color
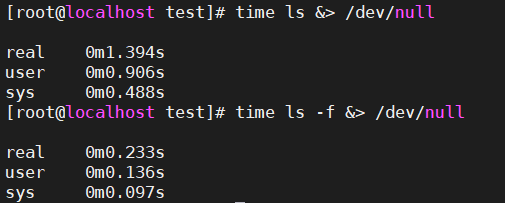
3.1、执行效率对比
[root@localhost test]# time ls &> /dev/null
real 0m1.394s
user 0m0.906s
sys 0m0.488s
[root@localhost test]# time ls -f &> /dev/null
real 0m0.233s
user 0m0.136s
sys 0m0.097s
4、通过重定向导入到文件中浏览对应的文件名
ls -1 -f > /tmp/filelist.txt
-1:一行一个文件名
-f:关闭排序功能

通过less、more、vim等工具进行浏览和搜索
三、如何快速删除目录下所有文件
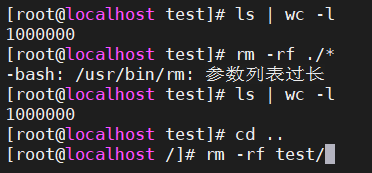
1、rm -f ./* ?
rm -rf ./*
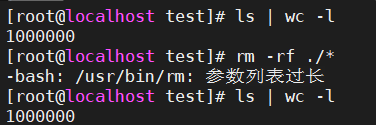
很显然,rm的参数列表过长,无法执行rm命令
2、将整个目录名作为参数传递给rm命令
rm -rf test
3、使用find配合-delete参数
find /test/ -mindepth 1 -delete

这条命令会从指定目录开始,查找所有非目录项(即文件)并删除它们。
-mindepth 1确保不删除当前目录本身,以防万一你需要保留该目录结构以便后续检查或操作。
四、需要保留指定文件怎么办
1、创建一个文件列出需要保留的文件名(一行一个文件名)
[root@localhost ~]# cd /tmp/
[root@localhost tmp]# cat > reserved_list.txt <<EOF
> 6.data
> 66.data
> 666.data
> 6666.data
> 66666.data
> EOF
#在一个干净的目录下创建
2、创建一个名为empty的空目录
[root@localhost tmp]# mkdir empty
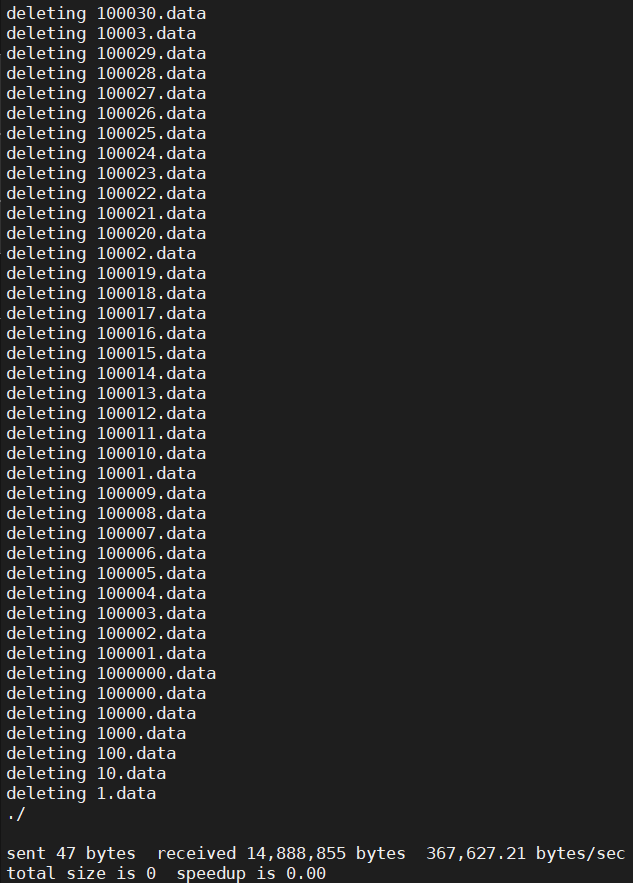
3、使用rsync命令
[root@localhost ~]# rsync -av --delete /tmp/empty/ /test/ --exclude-from=/tmp/reserved_list.txt
3.1、命令详解

rsync: 是一个用于文件传输和数据备份的高效工具,它可以镜像本地或远程系统上的文件和目录,并且可以高效地更新差异部分。-av: 这里有两个选项:-a或--archive是一个综合选项,意味着进行归档模式的拷贝,它保留了 symbolic links, devices, permissions, owner, groups, timestamps, 和其它文件属性,并递归地拷贝目录。-v或--verbose表示详细模式,会让rsync在执行时输出更多的信息,比如哪些文件正在被传输。
--delete: 这个选项指示rsync它会让目标目录(/test/)与源目录(/tmp/empty/)保持一致,移除目标目录中多余的文件。/tmp/empty/: 源目录,这是一个假设为空的目录。因为源目录是空的,结合--delete选项,实际上会导致目标目录/test/中的所有内容被删除(除非有排除规则)。/test/: 目标目录,你想同步到或依据源目录进行清理的目录。--exclude-from=/tmp/reserved_list.txt: 这个选项指定了一个文件列表,其中包含了不想被删除或同步的文件/目录的模式。rsync会读取/tmp/reserved_list.txt文件中的每一行作为排除模式,确保这些模式匹配到的文件或目录不会被删除。
整个命令的意思是:以归档模式并且详细输出的形式,同步空目录 /tmp/empty/ 到目录 /test/,在同步过程中删除目标目录中源目录不存在的文件,但排除 /tmp/reserved_list.txt 文件中列出的文件或目录不被删除。这是一种清理或重置目录结构的方法,同时保留特定的“保留”文件或目录不被删除。
4、检查源目录是否保留了指定文件
ls /test/


