py#SPI实现
SPI源码定义语句,通过定义语句可以知道需要输入哪些参数以及具体的参数信息
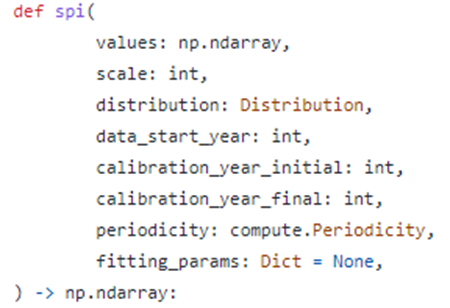
输入参数说明:
| 参数 | 含义 | 数据格式 | 说明 |
| values | 降水量 | 一维numpy数组 | 单位不限,如果时间尺度为月,则第一个值对应初始年的1月;如果为日,则对应初始年1月1日。 |
| scale | 时间尺度 | int | 用于定义SPI的时间尺度 |
| distribution | 概率分布 | Distribution | 定义降水符合的概率分布函数,可选择"gamma"或"pearson" |
| data_start_year | 数据开始年份 | int | 降水数据集开始的年份 |
| calibration_year_initial | 校正期开始年份 | int | 参与SPI长时间序列校正开始的年份 |
| calibration_year_final | 校正期结束年份 | int | 参与SPI长时间序列校正结束的年份 |
| periodicity | 时间尺度的单位 | 字符型 | 可选择'monthly'或'daily' |
| fitting_params | 预先计算的拟合参数 | Dict | 通常使用默认值,Dict=none |
代码:
import numpy as np
import pandas as pd
from climate_indices import indices
from climate_indices import compute
import matplotlib.pyplot as plt
#读取降水数据
tampa=pd.read_table('tampa.txt',sep=';',header=None)
tampa_pre=tampa.values[:,0]
#计算SPI
#开始年份
ystr=1900
#结束年份
yend=2000
tampa_spi=indices.spi(values=tampa_pre,
scale=3,
distribution=indices.Distribution.gamma,
data_start_year=ystr,
calibration_year_initial=ystr,
calibration_year_final=yend,
periodicity=compute.Periodicity.monthly
)
参考:
官方:https://climate-indices.readthedocs.io/en/latest/
源码:https://github.com/monocongo/climate_indices/blob/master/src/climate_indices/indices.py#L70
https://blog.csdn.net/EWBA_GIS_RS_ER/article/details/115290209

 浙公网安备 33010602011771号
浙公网安备 33010602011771号