
Spark简介
一、什么是Spark
Apache Spark™ is a unified analytics engine for large-scale data processing.
Apache Spark™ 是用于大规模数据处理的统一分析引擎。
Spark是一个实现快速通用的集群计算平台。是由AMP实验室开发的通用内存并行计算框架,提供了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,运行用户将Spark部署在大量廉价硬件之上,形成集群。
1.1 Spark的四大特性
(1)Speed
Spark使用DAG调度器,查询优化程序和物理执行引擎,实现批量和流式数据的高性能
(2)Easy of Use
Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法。
(3)Generality
Spark可以用于批处理、交互式查询(SparkSQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。
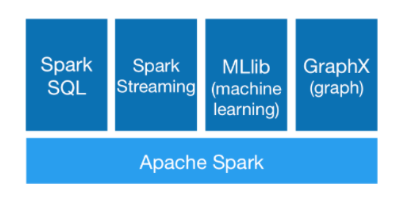
(4)Runs Everywhere
Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等。Spark提供了Standalone作为其内置的资源管理和调度框架。
二、Spark的组成
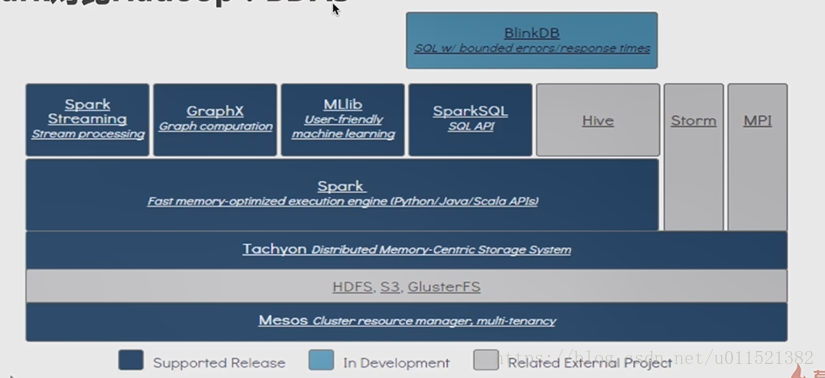
(1)Spark
是整个组件的核心,是一个大数据分布式编程框架,不仅实现了MapReduce的算子map函数和reduce函数及计算模型,还提供更为丰富的算子,如filter、join、groupByKey等。Spark将分布式数据抽象为弹性分布式数据集(RDD),实现了应用任务调度、RPC、序列化和压缩,并为运行在其上的上层组件提供API。其底层采用Scala这种函数式语言书写而成,并且所提供的API深度借鉴Scala函数式的编程思想,提供与Scala类似的编程接口。
(2)Shark
是构建在Spark和Hive基础上的数据仓库,已终止开发。
(3)Spark SQL
提供在大数据上的SQL查询功能,Spark SQL使用Catalyst做查询解析和优化器,并在底层使用Spark作为执行引擎实现SQL的Operator。用户可以在Spark上直接书写SQL,相当于为Spark扩充了一套SQL算子,这无疑更加丰富了Spark的算子和功能,同时Spark SQL不断兼容不同的持久化存储(如HDFS、Hive等),为其发展奠定广阔的空间。
(4)Spark Streaming
通过将流数据按指定时间片累积为RDD,然后将每个RDD进行批处理,进而实现大规模的流数据处理。
(5)Graphx
基于BSP模型,进行大规模同步全局的图计算,尤其是进行多轮迭代时,基于Spark内存计算的优势尤为明显。
(6)Tachyon
Tachyon是一个分布式内存文件系统。
(7)Mesos
Mesos是一个资源管理框架,提供类似于YARN的功能。用户可以再其中插件式地运行Spark、MapReduce、Tez等计算框架的任务。Mesos会对资源和任务进行隔离,并实现高效的资源任务调度。
(8)BlinkDB
BlinkDB是一个用于在海量数据上进行交互式SQL的近似查询引擎。BlinkDB的核心思想是:通过一个自适应优化框架,随着时间的推移,从原始数据建立并维护一组多维样本;通过一个动态样本选择策略,选择一个适当大小的示例,然后基于查询的准确性和响应时间满足用户查询需求。
三、Spark的企业级应用
(1)亚马逊云计算服务AWS
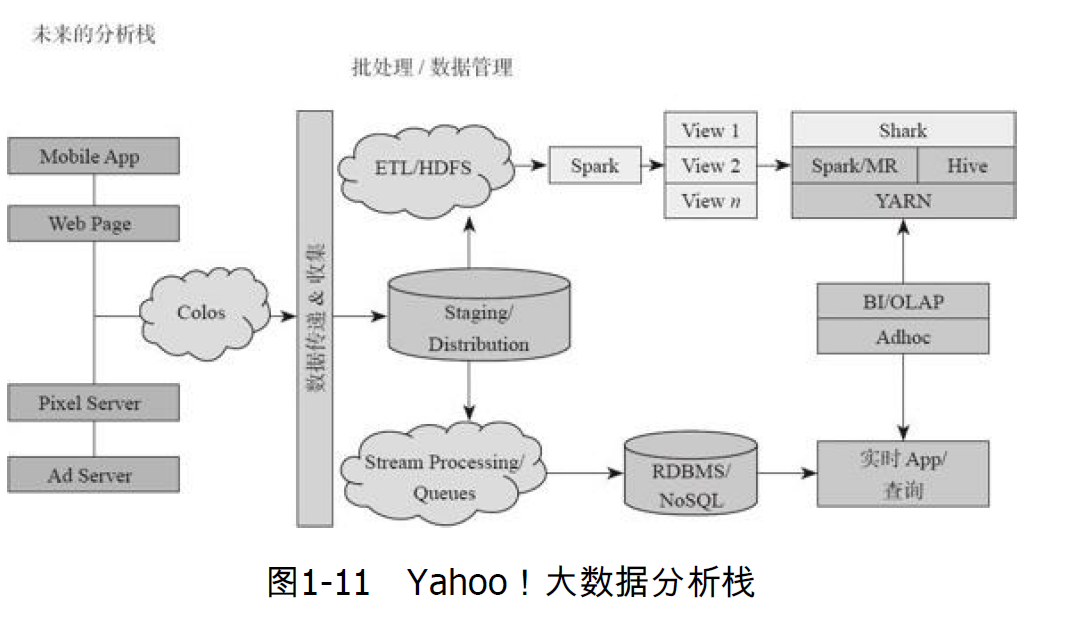
(2)Yahoop的移动App、网站、广告服务、图片服务等服务的后端实时处理框架均采用了Spark+Shark的架构
(3)Spark在淘宝的应用
淘宝技术团队使用了Spark来解决多次迭代的机器学习算法、高计算复杂度的算法等。应用于内容推荐、社区发现等
(4)腾讯
腾讯大数据精准推荐借助Spark快速迭代的优势,实现了在“数据实时采集、算法实时训练、系统实时预测”的全流程实时并行高维算法,最终成功应用于广点通pCTR投放系统上。
(5)优酷土豆
优酷土豆将Spark应用于视频推荐(图计算)、广告业务,主要实现机器学习、图计算等迭代计算。
