

SQL server高级语法
1. 公共表达式CTE
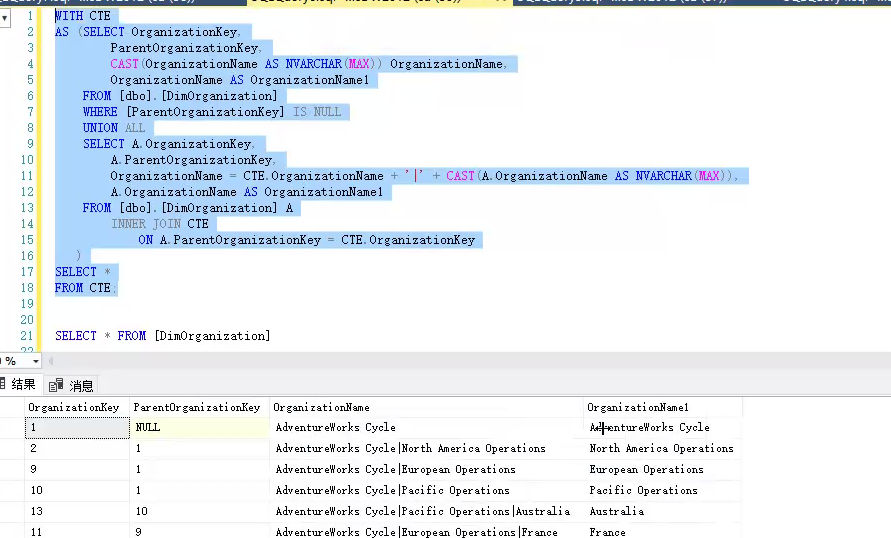
公用表表达式 (CTE) 具有一个重要的优点,那就是能够引用其自身,从而创建递归 CTE。递归 CTE 是一个重复执行初始 CTE 以返回数据子集直到获取完整结果集的公用表表达式。
如下面的例子,可以递归把组织名放到一起。
其实CTE的作用就相当于子查询
2.窗口函数、分区函数
窗口函数和聚集函数一样都是对定义的行集(组)进行聚集,但是不像聚集一样只返回一个值,窗口函数可以为每个组返回多个值,执行聚集的行组是窗口(因此称为‘窗口函数’)。窗口函数是在聚集函数的基础上加了一个 over(),所有的聚集函数都可以利用这种方式转换成窗口函数。窗口函数是最后才执行的,在order by 之前,where和group by之后
Partition By分区子句:可以根据partition by子句定义行的分区或组,以完成聚集,如果使用空括号,那么整个结果集就是分区,窗口函数将对它进行聚集计算,可以把Partition By看成是移动的Group By,可以用Partition By对定义的行组计算聚集(当遇到新的组时复位),并返回每个值(每个组中的成员),而不是用一个组表示表中这个值的所有实例。

窗口函数除了用于聚集函数sum,count,avg等之外,还有row_number(计算行数),rank(排名),lead() ,lag()前移后移 在日常工作中使用也很大;
3.FOR XML Path
这个在sql server中的作用主要是把行数据转列。在mysql中有group_concat,DB2中有listagg,而sql server中没有,所以用for xml path
如下,我要取得年月,直接查询是这样的
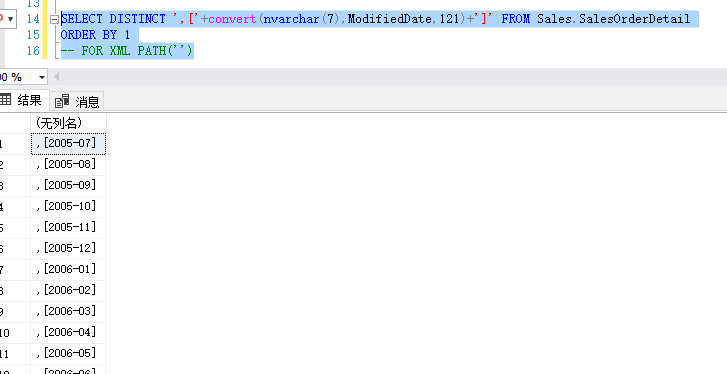
当我在后面加上了for xml path 后就得到了一行的结果:
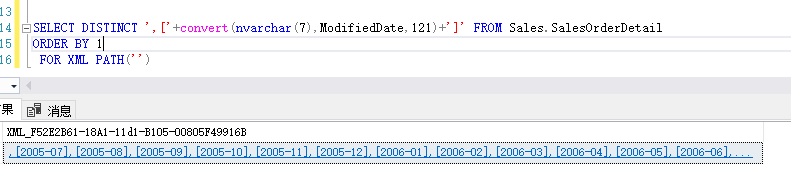
用字符串处理函数去掉前面的第一个逗号,就可以得到一个可用的字符串,用于存储过程之类的;
4.PIVOT 和UNPIVOT 行列转换函数
PIVOT:行转列,下面的代码实现的是,选择orderid为71774和71780的两个产品作为列名,以productID作为行,得到汇总数据
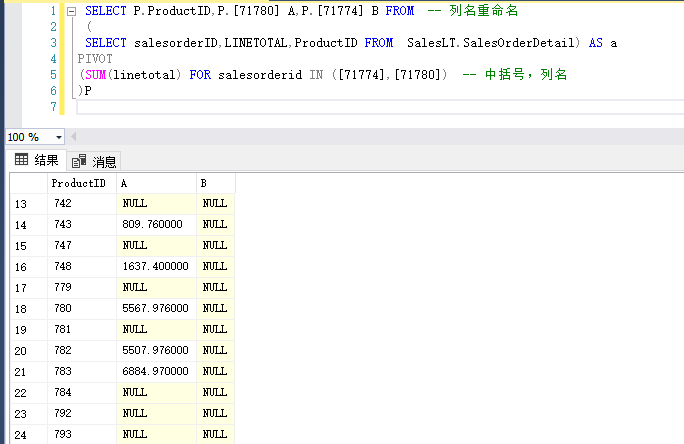
UNPIVOT 列转行 贴一个官方教程的例子:
运行结果:

5.Merge 的应用 主要用于更新数据,贴一个我写的存储
6.动态sql
文本拼接语句 缺点:1.容易被注入,被黑 最好不用 2.容易报错,如西安的拼音 xi'an
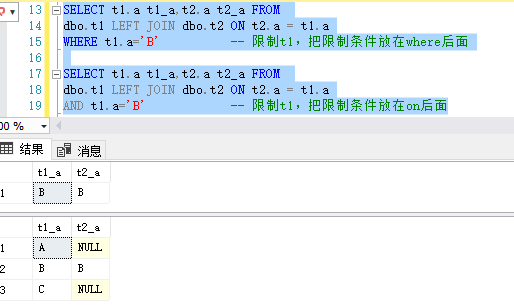
7.ON条件 在使用left jion时,on和where条件的区别如下:
on条件是在生成临时表时使用的条件,它不管on中的条件是否为真,都会返回左边表中的记录。
where条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有left join的含义(必须返回左边表的记录)了,条件不为真的就全部过滤掉
举个例子:
先创建t1,t2两个表
以下是限制left join 左边的表的结果,可以看到上面的才是我们想要的结果
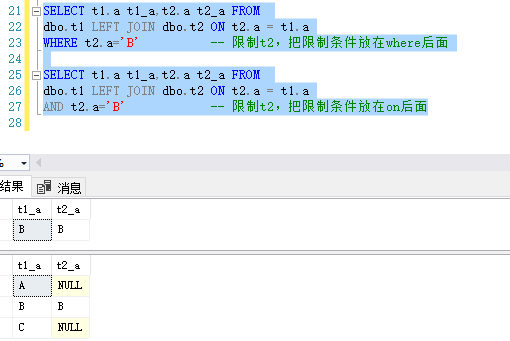
以下是限制t2的结果,可以发现把条件放在on后面才是我们想要的结果
8.Except 和Intersect
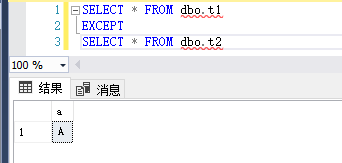
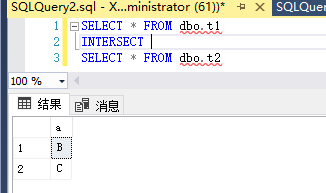
比较两个查询的结果,返回非重复值。
EXCEPT 从左查询中返回右查询没有找到的所有非重复值。
INTERSECT 返回 INTERSECT 操作数左右两边的两个查询都返回的所有非重复值,即二者交集。
还是用刚刚的表,t1中是ABC,t2中是BCD
那么EXCEPT返回的是A
INTERSECT返回的是BC
作者:Miranda.Tang
出处:http://www.cnblogs.com/miranda-tang/
本作品采用署名-非商业性使用 3.0协议进行许可。欢迎转载,演绎,但是必须保留本文的署名Miranda.Tang,且不能用于商业目的。
posted on 2018-01-23 16:06 miranda_tang 阅读(4878) 评论(0) 编辑 收藏 举报

