
【Coursera GenAI with LLM】 Week 3 LLM-powered applications Class Notes
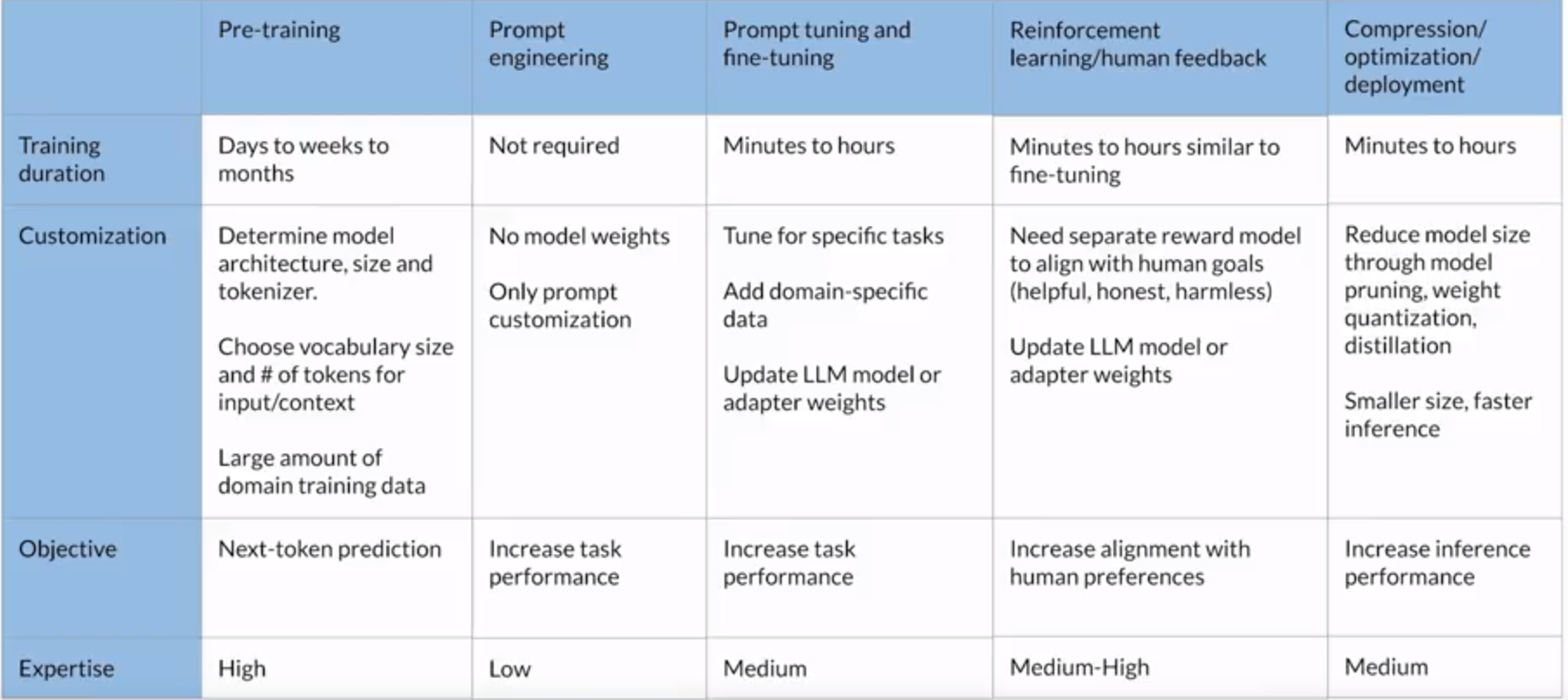
Model optimizations to improve application performance
-
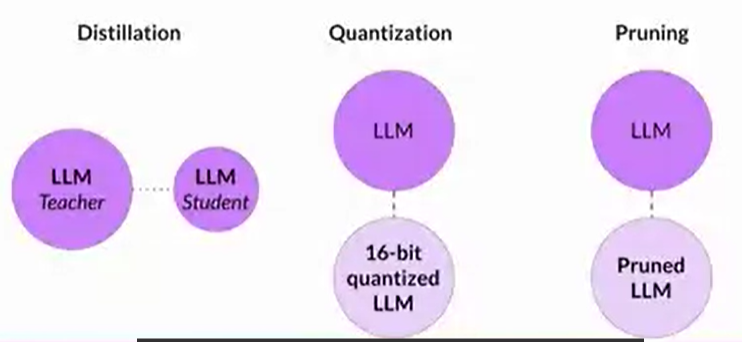
Distillation: uses a larger model, the teacher model, to train a smaller model, the student model, we freeze teacher's weights and generate completions, also generate student model's completion, the difference between those 2 completions is Distillation Loss . Student model will adjust its final prediction layer or hidden layer. You then use the smaller model for inference to lower your storage and compute budget.
-
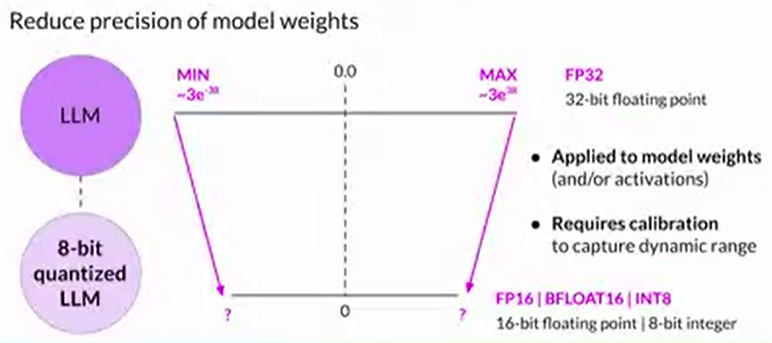
Quantization: post training quantization transforms a model's weights to a lower precision representation, such as a 16-bit floating point or eight-bit integer. This reduces the memory footprint of your model.
-
Pruning: removes redundant model parameters that contribute little to the model's performance.
Cheat Sheet
RAG (Retrieval Augmented Generation)
Chain of thought prompting
Program-Aided Language Model (PAL)
- LLM + Code interpreter --> to solve the problem that LLM can't do math
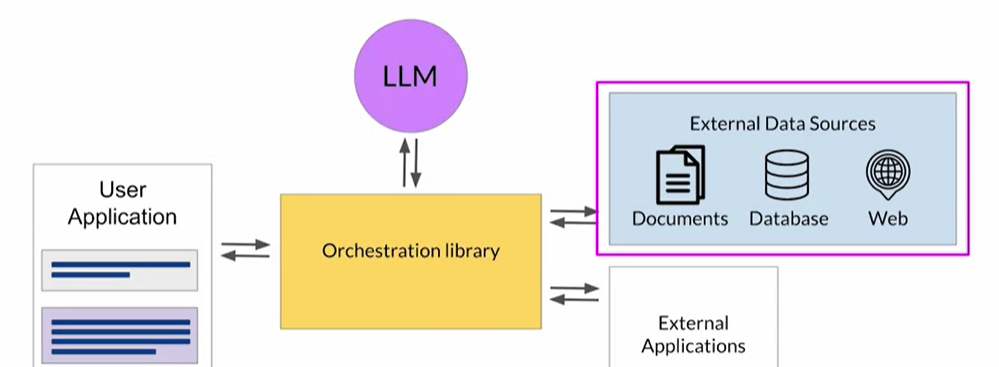
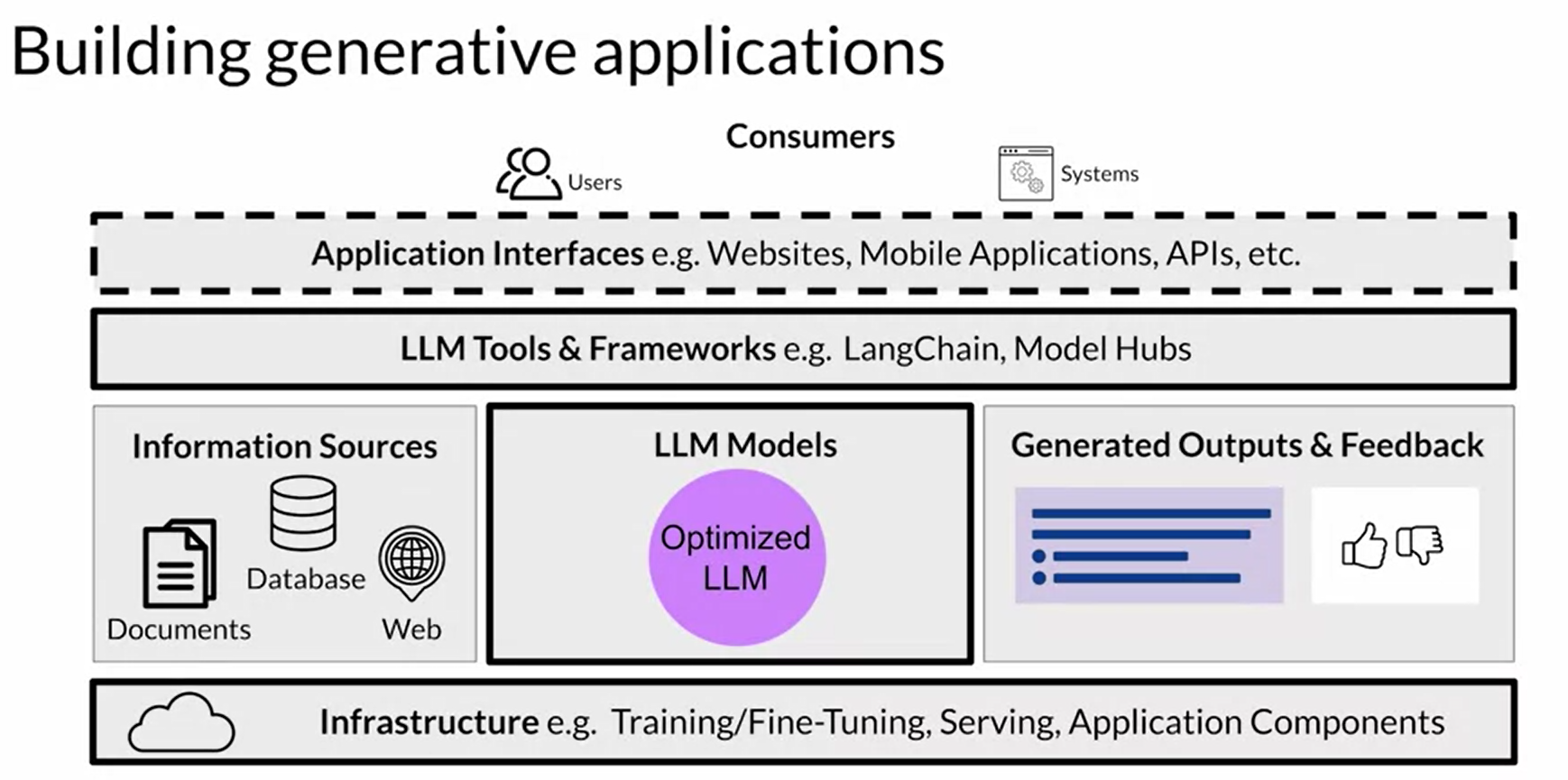
Orchestrator: can manage the information between LLM, external app and external databases. ex. Langchain
ReAct: it's a format for prompting (?), synergizing reasoning and action in LLMs
- Thought: reason about the current situation
- Action: an external task model can carry out from an allowed set of actions--search, lookup, finish
- Observation: a few example


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?