
【Coursera GenAI with LLM】 Week 3 Reinforcement Learning from Human Feedback Class Notes
Helpful? Honest? Harmless? Make sure AI response in those 3 ways.
If not, we need RLHF is reduce the toxicity of the LLM.
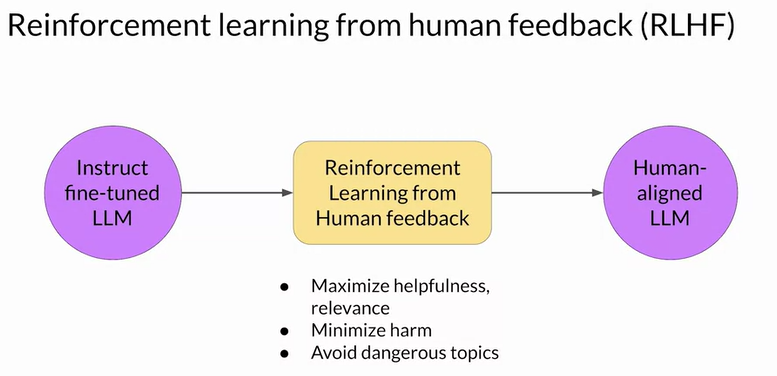
Reinforcement learning: is a type of machine learning in which an agent learns to make decisions related to a specific goal by taking actions in an environment, with the objective of maximizing some notion of a cumulative reward. RLHF can help making personalized LLMs.
RLHF cycle: iterate until reward score is high:
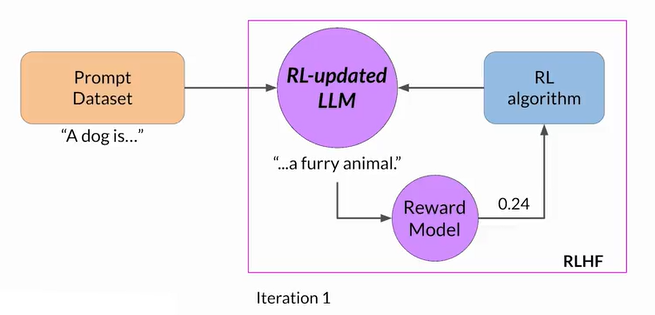
- Select an instruct model, define your model alignment criterion (ex. helpfulness)
- obtain human feedback through labeler workforce to rate the completions
- Convert rankings into pairwise training data for the reward model
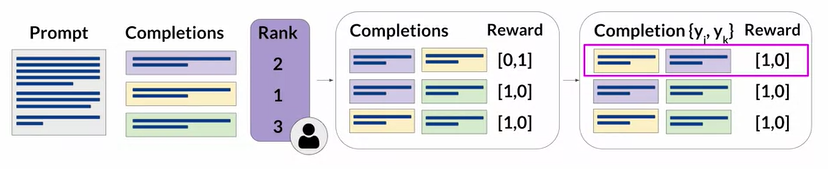
- Train reward model to predict preferred completion from {y_j, y_k} for prompt x
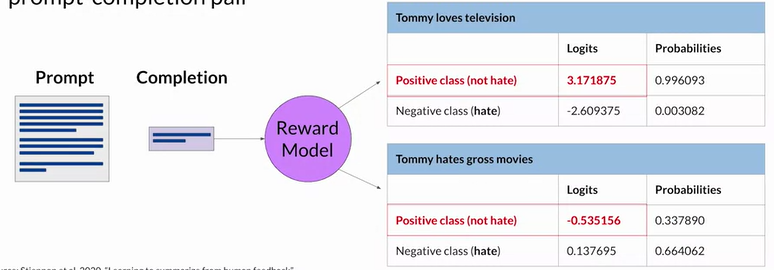
- Use the reward model as a binary classifier to automatically provide reward value for each prompt-completion pair
lower reward score, worse the performance
softmax(logits) = probabilities
RL Algorithm
- RL algorithm updates the weights off the LLM based on the reward is signed to the completions generated by the current version off the LLM
- ex. Q-Learning, PPO (Proximal Policy Optimization, the most popular method)
- PPO optimize LLM to more aligned with human preferences
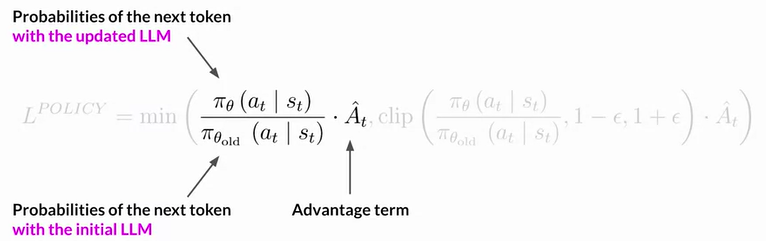
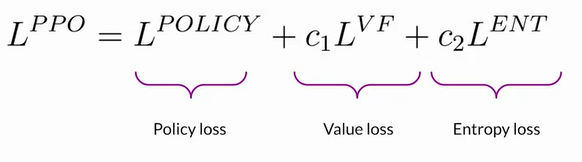
Reward hacking: the model will achieve high reward score but it actually doesn't align with the criterion, the quality is not improved
-
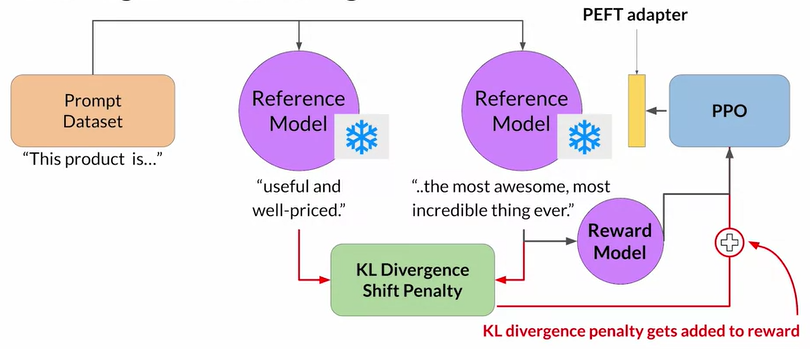
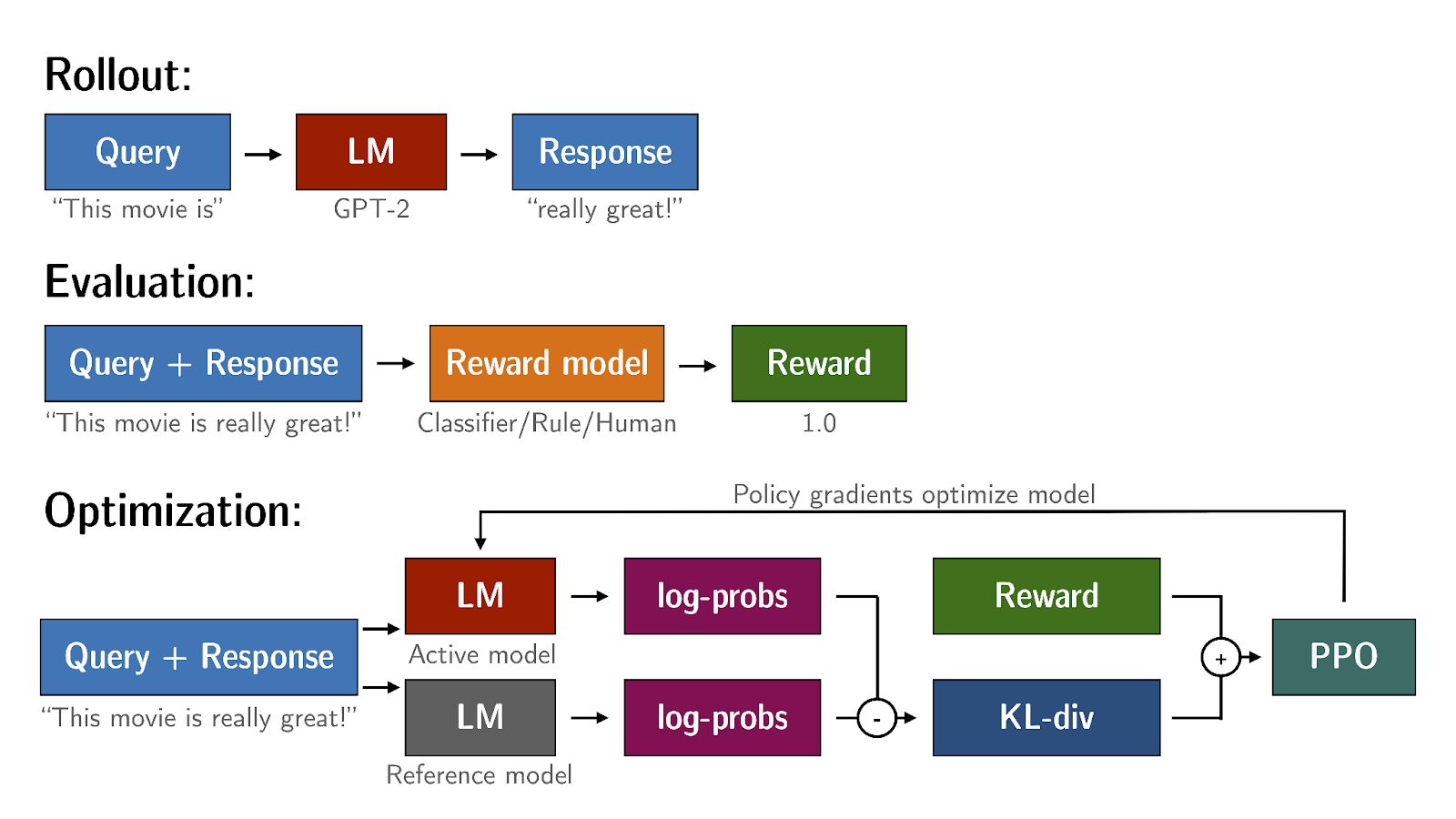
To avoid this, we can use the initial instruct model (aka reference model). * during training, we pass prompt dataset to both reference model and RL-updated LLM,
-
Then, we calculate KL Divergence Shift Penalty (a statistical measure of how different two probability distributions are) between two models
-
Add the penalty to the Reward Model, then go through PPO, PEFT, and back to reward model
-
-
Constitutional AI
- First proposed in 2022 by researchers at Anthropic
- a method for training models using a set of rules and principles that govern the model's behavior.
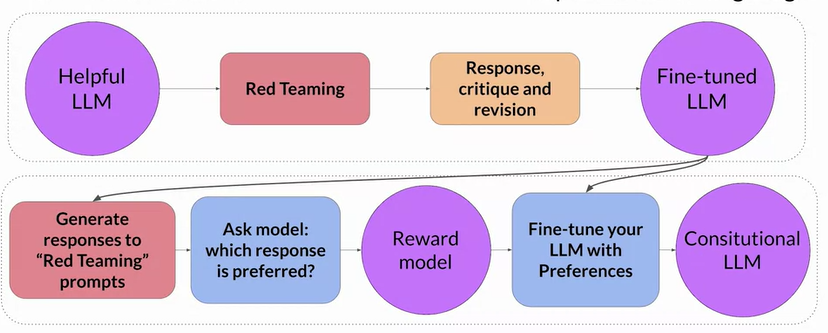
Red Teaming: make it to generate harmful responses. Then, remove all harmful responses
PPO: Proximal Policy Optimization


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?